[배경지식] 네트워크
-
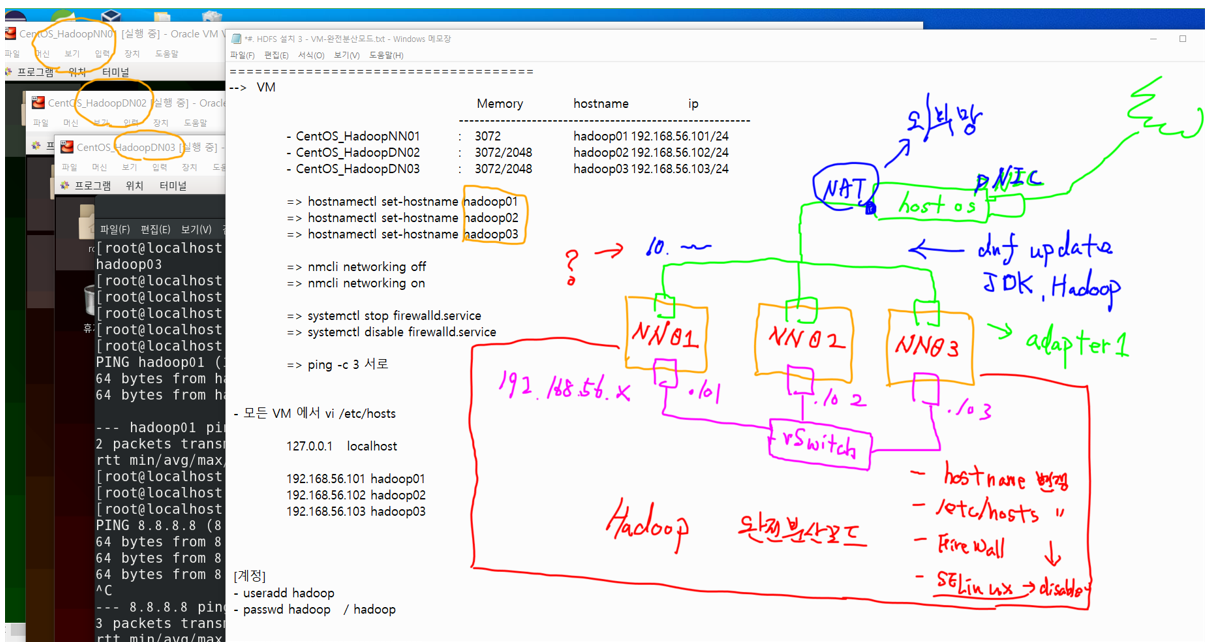
pNIIC : 실제 운영하는 물리적 네트워크
-
nat : 10.xx 망으로 되어있음
<- dnf update, jdk, hadoop
-
hadoop 분산모드 구성
hostadapter 구성 => switch 장비를 둠 == vSwitch
192.168.56.x => 망
192.168.56.106 NN01
192.168.56.107 NN02
192.168.56.108 NN03 -
LAN 카드 두개 구성 WHY?
update하거나 log 받야아 할 상황에서 외부망을 씀 -> nat 연결
hadoop에 완전 분산 모드 만들음 => 망을 이용
web server가 밖에서 공유하는 ip
참고: https://waspro.tistory.com/517
[배경지식] SSH
-
SSH(Secure Shell Protocol)
- 컴퓨터간 Public Network(ex. 인터넷)를 통해 통신을 할 때 안전하게 통신하기 위한 프로토콜
- 대표적 사용 예시
1. 데이터 전송 ex. 원격 저장소 github (push)- 원격 제어 ex. AWS 클라우드 서비스 (서버 접속 -> 명령)
-
왜 FTP, Telnet와 같은 통신 프로토콜은 사용하지 않는가?
- client pc에서 접속할 때 id와 pwd 넣을 때 plain text로 오고간다. 만약 중간에 누군가가 네트워크 모니터링 도구로 스캔하면 id, pwd는 그대로 노출될 것이다. 따라서 telnet은 암호화가 안돼서, 보안에 취약해서 SSH가 대신 사용된다.
-
SSH의 통신 방법
- 한 쌍의 Key(Private Key/Public Key)를 통해 접속하려는 컴퓨터와 인증 과정을 거침-
사용자(클라이언트)와 서버(호스트)는 각각의 키를 보유 => 키를 이용해서 상대를 인증하고 안전하게 데이터를 주고 받음
-
키 페어 : 공개키와 개인키 두 가지로 이루어진 한 쌍을 뜻하며
공개키 : .pub / 개인키 : .pem의 형식을 띔 -
비대칭키 방식과 대칭키 방식으로 동작함
-
비대칭키 방식
- 사용자 & 서버가 서로 정체를 증명하는 방식(인증 절차)
- 사용자가 키페어 생성 => 공개키 서버에 전송 => 서버에서 공개키 암호화 => 사용자 개인키(.pem)로 인증
-
대칭키 방식
- 정보를 주고받는 방식
- 대칭키라는 한 개의 키만 사용
- 서버or사용자 하나의 대칭키 만들어 공유
- 대칭키 이용해 정보 암호화 => 받은쪽에서 동일한 대칭키로 암호 풀어 정보 획득
-
[참고]
SSH란 ? https://library.gabia.com/contents/infrahosting/9002/
대칭키, 비대칭키? https://universitytomorrow.com/22
- openSSH 서버
- Secure Shell은 telnet의 취약한 부분을 암호화해서 오고가게 한다.
- 인증서를 갖고 송수신을 하게 되어있음
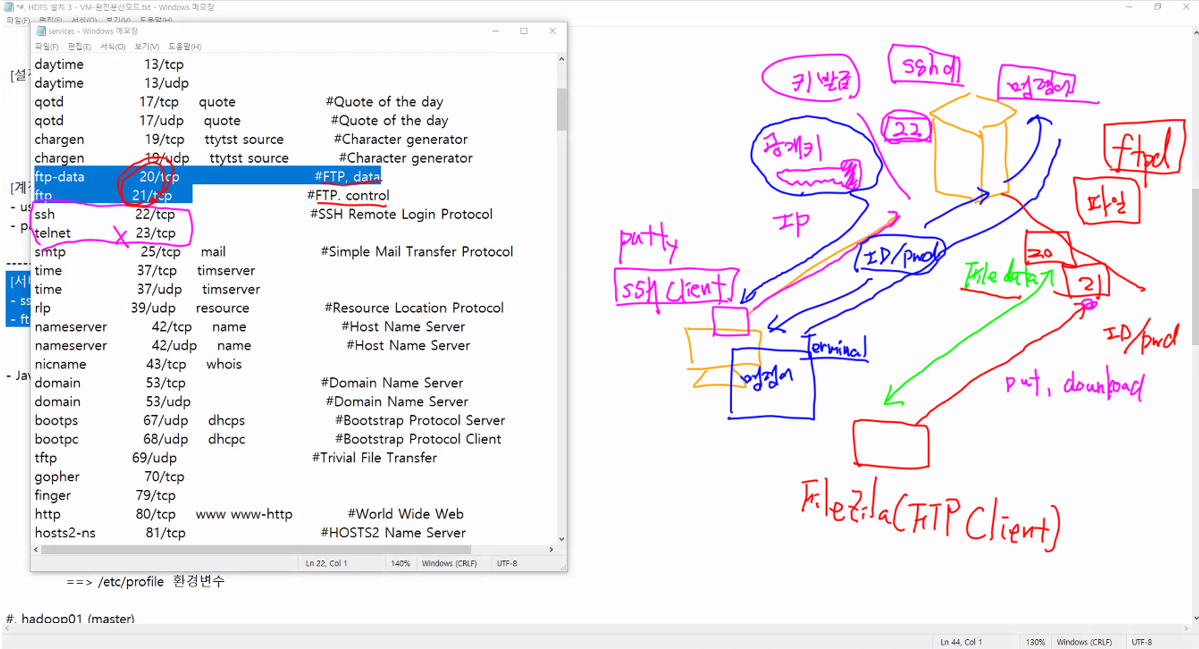
- ssh을 올려서 22번 port를 올려서 key를 발급 => 공개키[public key]가 들어가있음
- secureshel client(putty) IP 로 접속을 시도함 => 암호화된 통로로 접근할 수 있다.
- 주 데이터가 파일
- 파일을 오고가려면 20번 21번 port가 열려있어야 함
- Filezila(FTP Client) 설치 => 접속 id, pwd 통해 접속 => 21번 port로 ex. file을 올려, 다운로드 명령어가 오감 => file 데이터에 대한 처리는 20번을 통해서 오고 내려감
- ftpd가 설치되어있어야 함
- openssh ftp는 vs ftpd를 이용
- SSH은 파일 - ftp라고 하지만 21번은 명령어 전달, 20번은 파일 데이터 전달 하는 포트 2개가 열려있음
HDFS 설치 3 - VM-완전분산모드
====================================
- Oracle Virtual Box 6.1 / 포인트 장치 -> usb
====================================서버 기본 설정
고정 IP 설정
--> VM
Memory hostname ip
------------------------------------------------
- CentOS_HadoopNN01 : 3072 hadoop01 192.168.56.101/24
- CentOS_HadoopDN02 : 3072/2048 hadoop02 192.168.56.102/24
- CentOS_HadoopDN03 : 3072/2048 hadoop03 192.168.56.103/24
hostname 설정 (root / hadoop01, 02, 03 적용)
=> hostnamectl set-hostname hadoop01
=> hostnamectl set-hostname hadoop02
=> hostnamectl set-hostname hadoop03
각 서버마다 host명으로 접근 가능하도록 hosts 파일 설정
hadoop01, hadoop02, hadoop03에서 다 변경
=> vi /etc/hosts
=>192.168.56.101 hadoop01
=>192.168.56.102 hadoop02
=>192.168.56.103 hadoop03
네트워크 비활성/활성화 (root / hadoop01, 02, 03 적용)
=> nmcli networking off
=> nmcli networking on방화벽 해제 (root / hadoop01, 02, 03 적용)
* 방화벽
: 내부망을 보호하기 위한 네트워크 구성요소
: 외부로부터의 유입을 차단=> systemctl stop firewalld.service # 방화벽 서비스 해제
=> systemctl disable firewalld.service # 재부팅시 방화벽 실행 x ping test
=> ping -c 3 서로
root@hadoop01 $
ping hadoop02 -c 3
ping hadoop03 -c 3
root@hadoop02 $
ping hadoop01 -c 3
ping hadoop03 -c 3
root@hadoop03 $
ping hadoop01 -c 3
ping hadoop02 -c 3 SELinux 끄기 (root / hadoop01, 02, 03 적용)
SELinux
- 리눅스에 도입된 접근 권한 보안 모듈
- SELinux의 보안정책으로 서비스 구동이 원활하지 않을 수 있음 => but SELinux는 가급적 끄거나 비활성화하는걸 권장 x
- 이번 실습에서는 SELinux 끄고 실행
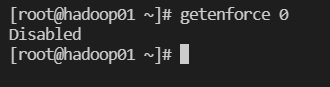
sentenforce 0
- SELinux 임시 비활성화
sentenforce 0(Permissive 상태) getenforce으로 SELinux 상태 확인


- SELinux 완전히 끄기
vi /etc/sysconfig/selinux=>SELINUX=disabled


reboot
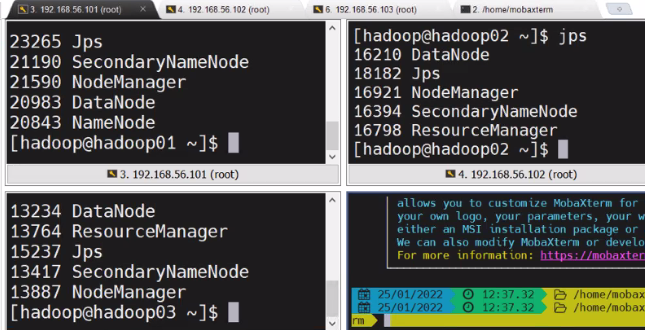
설치 확인 (root / hadoop01, 02, 03 적용)
su - hadoop
java -version
hadoop version
jps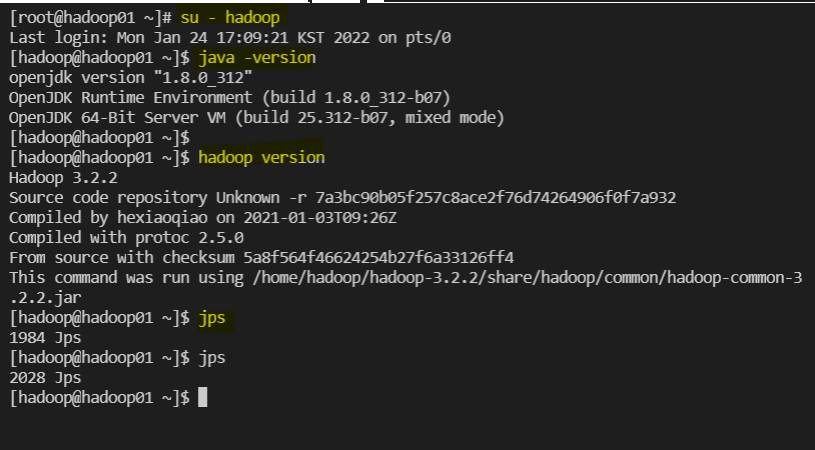
reate and setup ssh certificates (root, master(hadoop01))
- 하둡이 서로 소통하기 위해서 공개키 갖고있어야 함
- 동떨어진 PC가 서로 소통하기 위해서는 신뢰할 수 있는 환경 => 공개키로 만든다
- 공개키를 다 DATANODE에 COPY해놓아야 함
-
ssh-keygen -t rsa -
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys -
chmod 640 ~/.ssh/authorized_keys -
ssh localhost -
ssh-keygen -t rsa
같은 키로 구성이되어야 연계가 됨
이 과정은 master(hadoop01)에서 해야함
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
public에 생긴걸 추가를 한다
(authorized keys 파일이 이미 있으면=> rm authorized_keys 한 다음에 cat부터 해야 함)

-
root에서 hadoop 계정에 인증서 있는지 확인
ll /home/hadoop/.ssh/id_rsa.pub -
root 계정
// /home/hadoop/.ssh/id_rsa.pub
// hadoop02, hadoop03 에 키 복사
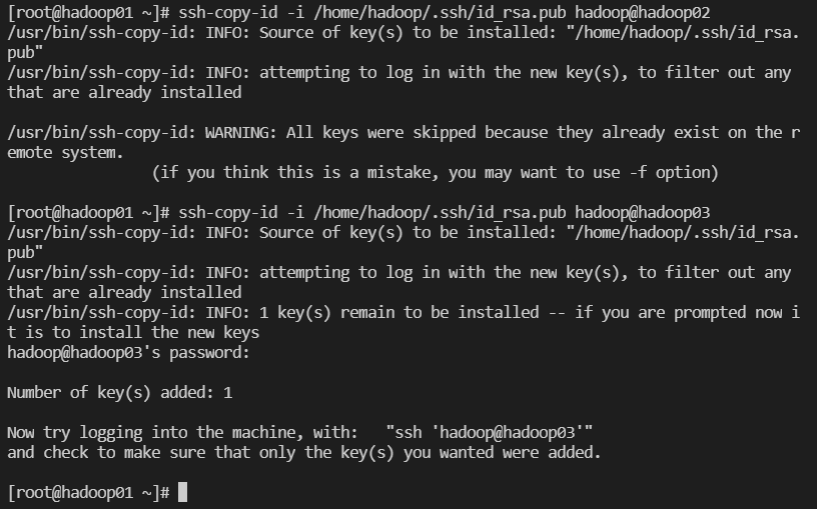
$ ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@hadoop02
$ ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@hadoop03
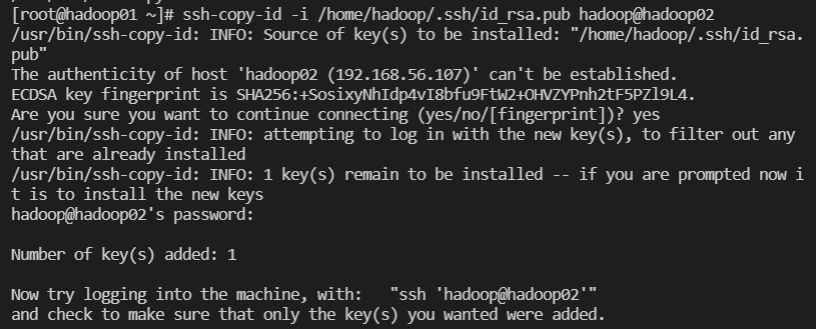

##########################################################
@ key_permission denied 문제 해결
만약 key_permission deny 문제가 생긴다면
- hadoop01, 02, 03 root
ssh-keygen-t rsa를 입력
- hadoop01, 02, 03 에서 su - haddoop (하둡 계정으로 변경=> 입력)
1.cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
2.chmod 640 ~/.ssh/authorized_keys
3.ssh localhost
4.exit
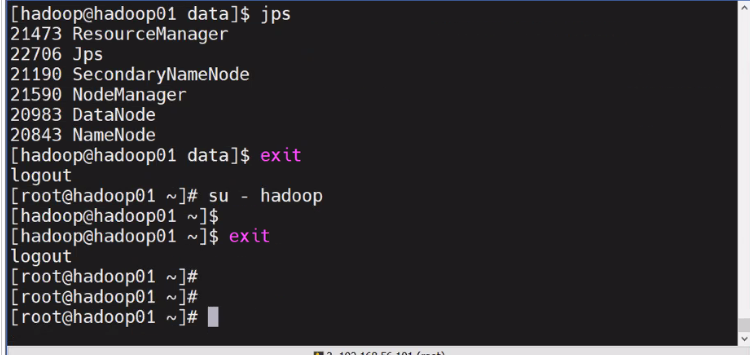
-
hadoop01의 root에서 02, 03에 키값을 넘겨줌
$ ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@hadoop02
$ ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@hadoop03 -
hadoop01에서 hadoop으로 로그인
SSH 접속 확인
-
ssh 접속 확인 - hadoop02, hadoop03
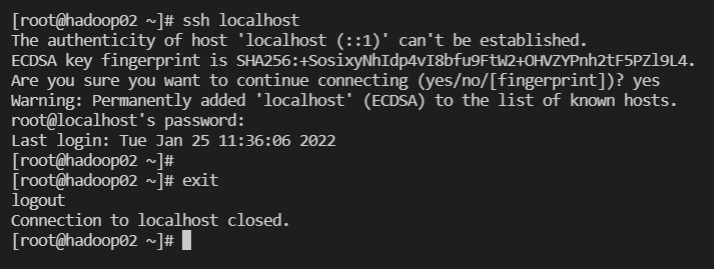
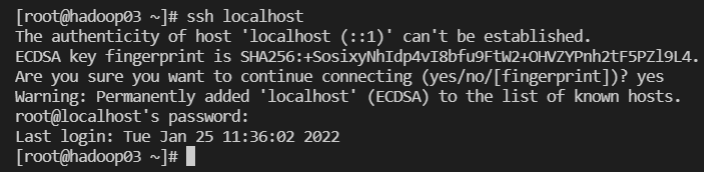
-
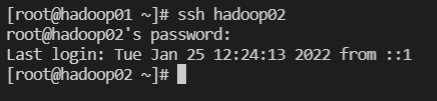
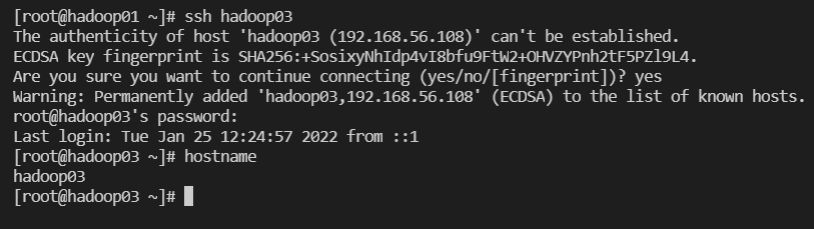
master에서 다른 pc 접속

-
master에서 copy
-
hadoop02, 03에서 key 생성 확인
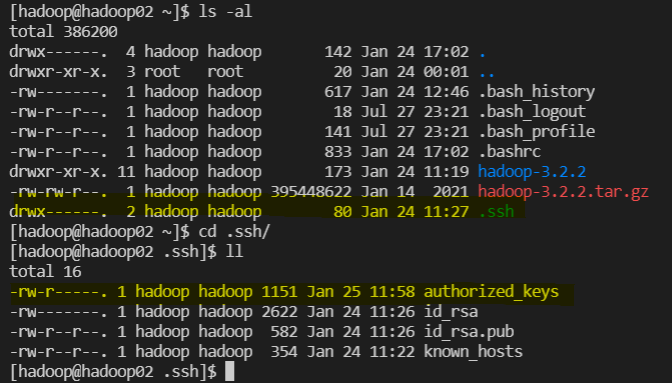
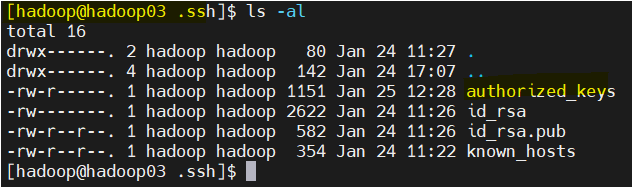
-
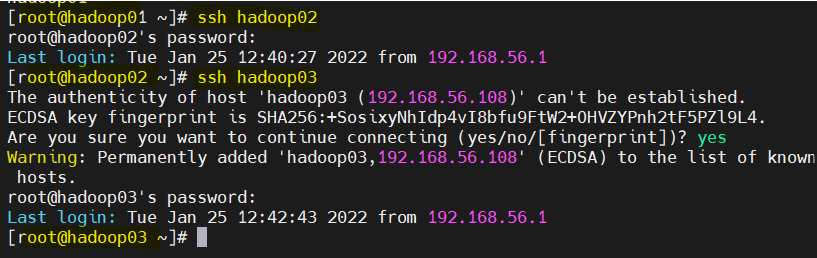
ssh 확인
ssh hadoop02
ssh hadoop03

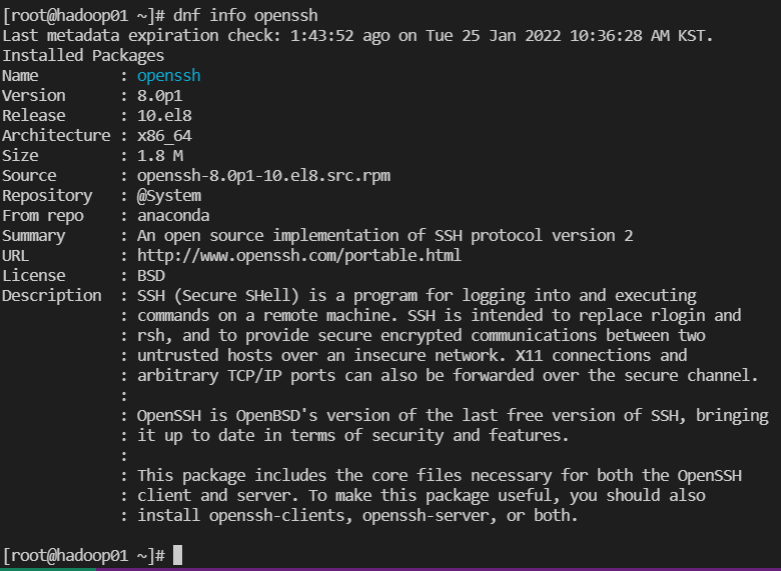
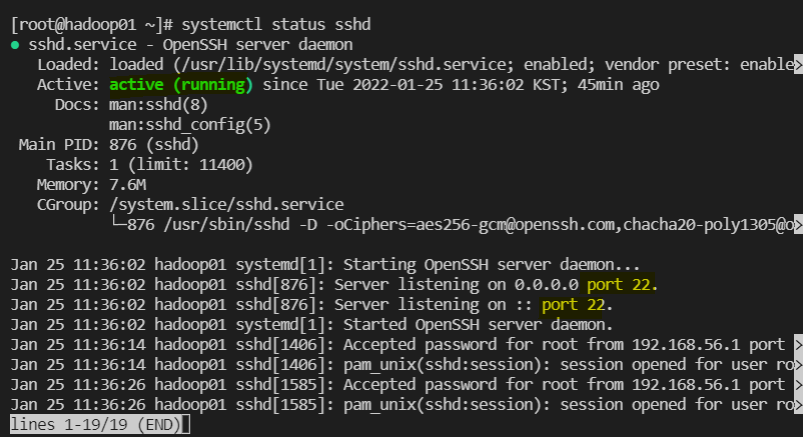
sshd / ftpd
- sshd
ssh 설치 확인 :dnf info openssh
가동중인지, 포트번호 열려있는지 확인 :systemctl status sshd
재시작 :systemctl restart sshd

- ftpd
ftpd 설치 확인 :dnf info vsftpd
install :dnf install vsftpd -y
재시작 :systemctl restart vsftpd
상태확인 :systemctl status vsftpd
부팅시 서비스 자동 시작 :systemctl enable vsftpd
참고해서 진행하기 : https://seoulitelab.tistory.com/entry/CentOS-8-ftp-%EC%84%A4%EC%B9%98 (방화벽을 내렸다면 다시 올릴필요 x)
Java 버전
- Java 버전 => jdk 1.8 +
- Hadoop v3 : jdk 1.8 +
dnf install java-1.8.0-openjdk
dnf info java-1.8.0-openjdk
dnf remove java-1.8.0-openjdk
dnf install java-1.8.0-openjdk-devel.x86_64 -y
java -version
==> /etc/profile 환경변수Hadoop 설정
- Hadoop 버전 => Hadoop v3.2.2
- Hadoop v3.2.2
- wget https://downloads.apache.org/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
- 압축해제 ->
- tar -xvzf hadoop-3.2.2.tar.gz
[hadoop]
==> /.bashrc 환경변수
cp .bashrc .bashrc~ <== 복사본 .bashrc~
cat >> .bashrc <== hadoop 계정 환경변수 추가
export HADOOP_HOME=/home/hadoop/hadoop-3.2.2
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin datanode, namenode 디렉토리 생성
/home/hadoop/hadoop-3.2.2/ ls
- rm -rf data
[hadoop01]
/data
/namenode
/datanode
[hadoop02~03]
/data
/datanode파일 설정
1. 파일설정 <1>
[ hadoop01 ~ 03]
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
~~~/hadoop-env.sh
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
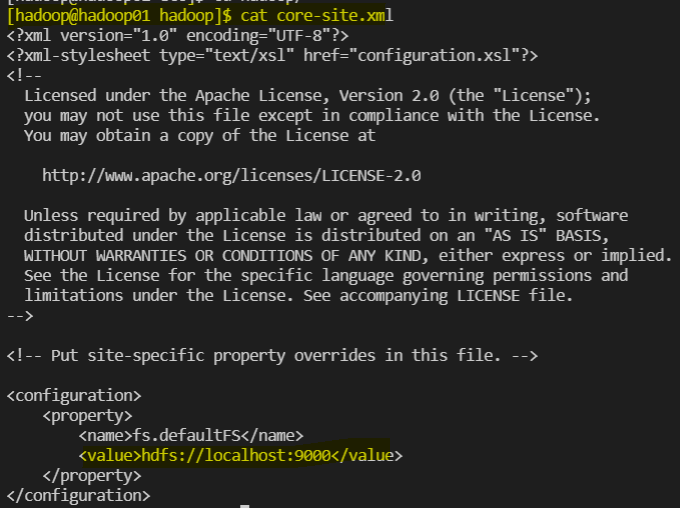
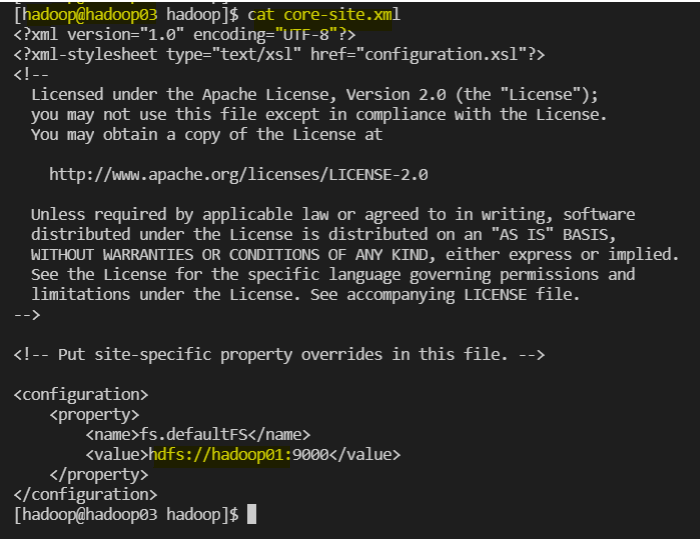
~~~ /core-site.xml
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
</configuration>hadoop-env.sh 확인
cat hadoop-env.sh | grep "JAVA_HOME"


수정 - hadoop02, 03도 core를 향하게 수정
2. 파일설정 <2>
[ hadoop01 ]
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
~~~ /hdfs-site.xml
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoop-3.2.2/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoop-3.2.2/hdfs/datanode</value>
</property>
</configuration>
[ hadoop02~03]
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
~~~ /hdfs-site.xml
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoop-3.2.2/hdfs/datanode</value>
</property>
</configuration>3. 파일설정 <3>
[ hadoop01 ~ 03]
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
~~~ /mapred-site.xml
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
~~~ /yarn-site.xml
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
HDFS 서비스 실행
==< HDFS 서비스 실행> =======================================
[ hadoop01 ]
hdfs namenode -format
start-dfs.sh
jps
[ hadoop02 ~ 03 ]
start-dfs.sh
jps
[ hadoop01 ~ 03 ]
start-yarn.sh
jps - 이렇게 나오면 성공