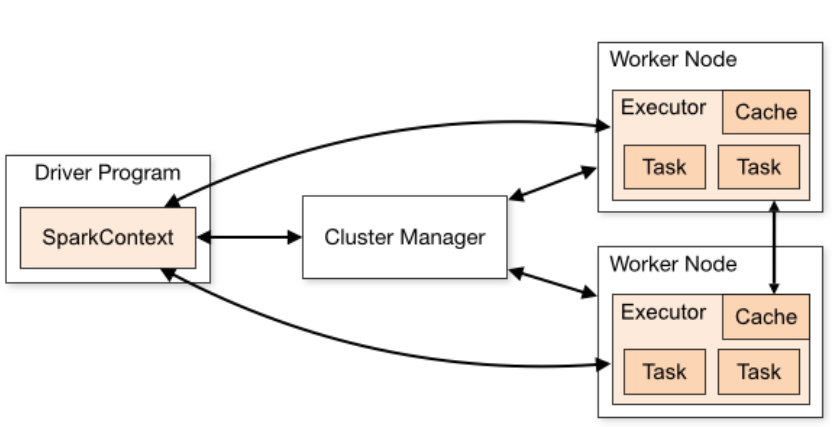
스파크 구조 + 실행 과정
- 스파크는 스파크 어플리케이션과 클러스터 매니저로 구성되어있음
- 스파크 어플리케이션 : 실제 일을 수행하는 역할 담당
- 클러스터 매니저 : 스파크 어플리케이션 사이 자원 중계 역할 담당
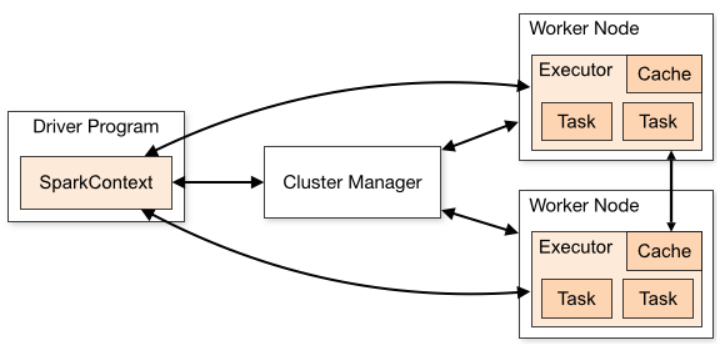
1. Spark Application
- Spark Application은 Driver Process와 Excutors로 구성됨
- 하나의 Spark Application에 1개의 Spark Driver + N개 Excutor가 포함됨
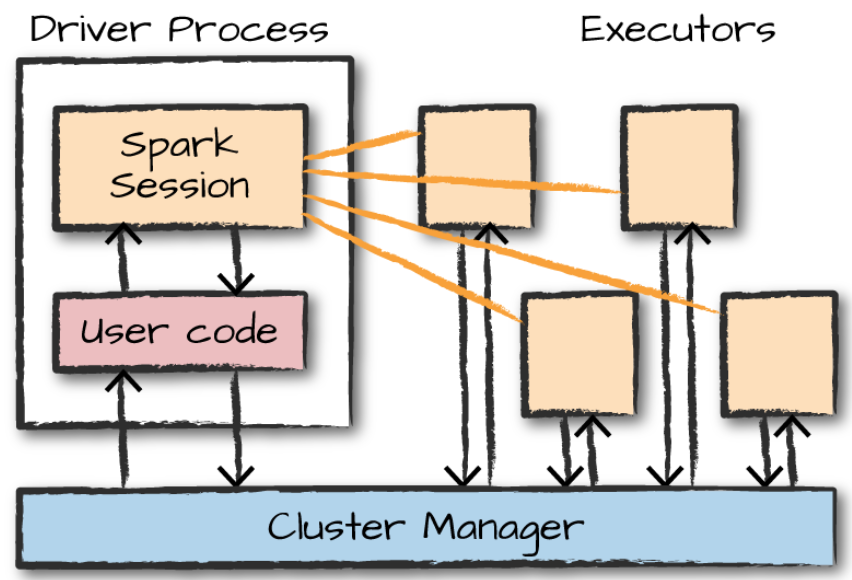
1) Driver :
- 한 개의 노드에서 실행되며, 스파크 전체 main() 함수를 실행함
- 어플리케이션 내 정보 유지관리, executor 실행, 배포 등의 역할 수행
- 사용자가 구성한 Job을 task 단위로 변환 => Excutor로 전달함
2) Executor :
- 다수의 worker 노드에서 실행되는 프로세스
- Spark Driver가 할당한 task를 수행해 결과를 반환
- 블록 매니저를 통해 cache하는 RDD를 저장함
Executor는 Cluster Manager에 의해 Spark Application에 할당됨
=> Spark Application이 완전히 종료된 후 할당이 끊어짐따라서, 서로 다른 스파크 어플리케이션 간 직접적 데이터 공유는 불가능!
2. Cluster Manager
Cluster Manager
- 스파크 어플리케이션의 리소스를 효율적으로 분배하는 역할
- 스파크는 Executor에 task를 할당 및 관리 하기 위해 클러스터 매니저에 의존함
- 스파크는 클러스터 매니저의 상세 동작을 알지 못함(Black-box)
- 클러스터 매니저와 통신하며, 할당 가능한 Excutor를 전달받음
Cluster Manager 종류
- 스파크가 사용 가능한 클러스터 매니저에는
Spark StandAlone, Yarn, Meos, Kubernetes 등이 있음
StandAlone 방식 vs Yarn, Meos, K8s .. 방식
-
StandAlone : 단일 컴퓨터에서 스파크 전체를 동작시키는 방식(클러스터x) => Driver와 Excutor는 각각 쓰레드로 동작함
Excutor는 Worker 노드 하나 당 한개 씩 동작함 -
Yarn, Mesos, K8s : Worker 노드에 여러개 Excutor를 실행시킬 수있음
Spark Application 실행 과정

1. 사용자가 Spark-Submit으로 application을 제출
2. Spark Driver => main() 실행, SparkContext를 생성함
3. SparkContext가 Cluster Manager와 연결됨
4. Spark Driver가 Cluster Manager로부터 Executor 실행을 위한 리소스를 요청함
5. Spark Context는 작업 내용을 task 단위로 분할해 Excutor에 전달
6. Excutor는 작업을 수행하고, 결과를 전달함
참고 : https://artist-developer.tistory.com/8?category=962892
스파크 데이터 구조
스파크 데이터 구조는 크게
1) RDD 2) Dataframe 3) Dataset 으로 구분할 수 있음
1. RDD (Resillient Distributed Data)
RDD 배경
- 스파크는 HDFS의 MapReduce에서 오버헤드가 발생하는 문제점을 해결하기 위해 In-Memory 기반으로 데이터를 처리함
- 그러나 메모리의 특성상 실행 도중 오류가 발생하면 데이터가 모두 사라지게 됨 => 처음부터 다시 연산해야하는 단점이 있음
- 이 문제를 해결하기 위해 RDD라는 데이터 구조를 만들음
RDD(Resillient Distributed Data)
- *Resillient : 메모리 내부에서 데이터 손실 시 유실된 파티션을 재연산을 통해 복구할 수 있음
- Distributed : 스파크 클러스터를 통해 메모리에 분산되어 저장
- Data : 파일, 정보
==> 즉, RDD는 변하지 않는 분산된 데이터의 집합! - 위의 문제(실행 도중 오류 발생 -> 데이터 사라짐)를 해결하기 위해 HDFS와 동일하게 RDD도 수정(Modify)이 되지 않는 Read-Only 데이터 구조를 만들음
여기서 Resillient 개념이 중요함
Resillient
Read-Only 특성
- RDD는 Resillient라는 불변의 특성(Read-Only)을 가짐 => 데이터셋이 읽기 전용 => 데이터에 변형을 가해야 할때 기존의 RDD를 변형한 새로운 RDD의 생성이 필요함 => 따라서, Spark 내의 연산에 있어 수많은 새로운 RDD들이 생성됨
- 이러한 RDD의 생성 순서를 Lineage라고 함 (*혈통)
DAG의 형태
- Lineage는 DAG(Directed Acyclic Graph)의 형태를 갖게 됨
- Dag란 순환하지 않는 방향성 그래프이다. (아래 그림 참고)
일정한 방향성을 가지며, 노드간에 의존성이 있으므로 노드의 순서가 중요한 형태임

- DAG에 모든 RDD의 생성 과정이 기록되어있음 => 메모리에서 데이터가 유실되면 Lineage 기록에 따라서 유실되었던 RDD를 생성할 수 있음
- 스파크는 위 특성으로 Fault-tolerant를 보장(작업 도중 장애가 발생해도 예비 부품 혹은 절차가 즉시 역할을 대체 수행-> 서비스의 중단이 없게 하는 특성) 하는 강력한 기능을 갖게 됨!
RDD 동작 원리
RDD의 명령어
RDD의 명령어는 크게 Transformation과 Action으로 나눌 수 있음
1) Transformation 명령어
- Map, Filter, read 명령어 등이 속함
- 기존의 RDD에서 새로운 RDD를 생성 (Return값이 RDD)
- Transformation에서 Spark가 실제 연산 작업을 수행하지는 않음
2) Action 명령어
- collect, count, reduce 명령어 등이 속함
- Lineage에 기록된 RDD 생성 과정을 실제로 생성하는 명령어(Return값이 데이터 or 실행 결과)
Action에서 Lineage에 기록된 RDD 생성하는 과정
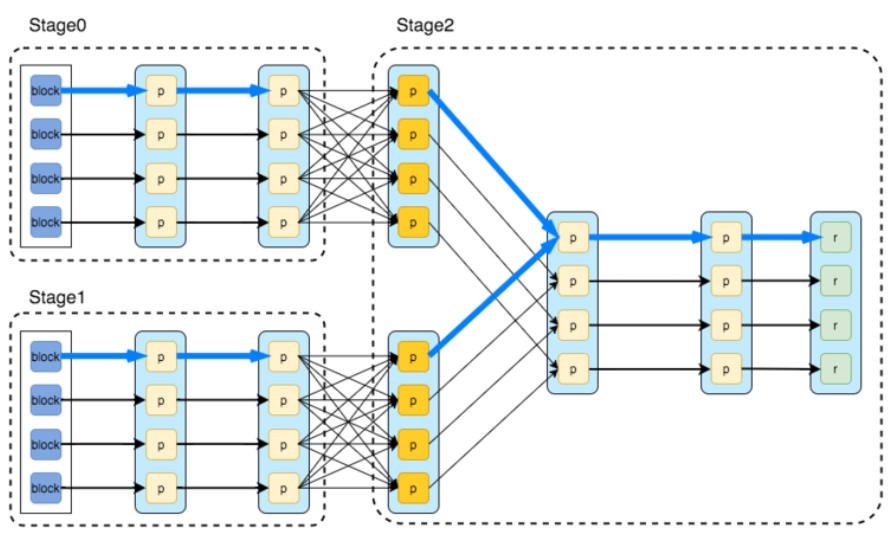
- Spark에서 작업이 시작 -> 스테이지(stage) 단위로 분할 => 여러개의 테스크(Task)로 나누어 실행됨
- 각 노드에 있는 데이터 분포 등에 따라 최적의 RDD 경로*를 찾음 (Lazy Evaluation*)
*최적의 RDD 생성 경로
각 노드에 저장된 데이터 셔플이 최소한으로 일어나는 것을 말함
노드간 셔플이 많이 일어나는 경우 = 넓은 의존성
노드간 셔플이 적게 일어나는 경우 = 좁은 의존성
(넓은 의존성 => 데이터간 셔플이 많이 일어남 => 성능 저하)
* Lazy Evaluation
RDD 동작 원리의핵심
Lazy Evaluation = 즉시 실행하지 않는 것을 의미
Action 연산자를 만나기 전까지 Transformation 연산자가 쌓여도 처리하지 않음
Hadoop의 Map Reduce와 대조적인 개념 => Spark는 간단한 Operation에 대한 성능 이슈를 고려하지 않아도 됨
2. Dataframe
- Pandas, R, Excel Sheet
- 행/열 Data
- column을 가질 수 있다.
3. Dataset
- Data의 Schema(구조)를 포함
- 행/열 Data
- column을 가질 수 있다.
4. refs
🎈 Reference
https://artist-developer.tistory.com/17?category=962892
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=cafesky7&logNo=221138921615
