✨ 학습 목적 :
이 내용을 참고해서 Spark Streaming을 해보려고 했는데, KafkaUtils는 현재 사용중인 spark 3.1.2 버전에서 지원하지 않았다.알아보니 Spark Streaming에는 DStreams라는 기능과 DataFrmae과 연동할 수 있는 Strucutred Streaming이 나뉜다는것을 알게되었다. 둘의 차이가 무엇일까...🤔
스파크 스트리밍 개념도 잡을겸 글 정리해본다.
01. Introduction
-
Spark는 스트리밍 데이터로 작업하는 두 가지 방식을 제공한다.
Spark로 실시간 Streaming 처리를 하는 방법에는 Spark Streaming방식과 structured streaming 방식이 존재한다. 가장 최신에 등장한 것은 structured streaming! -
dstream과 structured streaming의 차이점을 정리한 글들을 자세히 보면 다들 structured streaming을 쓰는걸 추천한다. 그 이유는 이제부터 자세히 살펴보자😁
02. Spark Streaming vs Structur Streaming
-
Spark Streaming에서는 RDD를 기반으로 Micro-bath을 수행한다.
-
Structured Streaming도 Micro-Batch 처리 엔진을 사용해 쿼리를 처리하지만,
연속 처리라는 저지연 처리 모드를 도입해 실시간에 가까운(트리거 간격) 처리를 한다. 또한 성능과 사용 용이성이 좋은 Dataframe이나 Dataset API를 기반으로 한다.
.
간단히 Spark Streaming과 Structured Streaming을 살펴보자.
Spark Streaming
- Spark Streaming은 Spark RDD를 기반으로 Micro-batch를 수행한다.
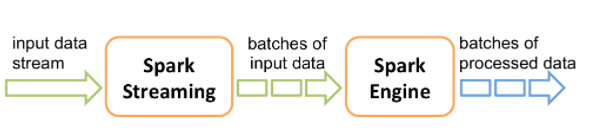
- 그림처럼 실시간으로 input data stream을 받아서 DStream(discretized stream)의 작은 배치 단위로 나눠 Spark Engine으로 보낸다. Spark engine에서는 가공한 데이터를 반환한다.

- DStream은 이산화된 데이터로, 시간별로 도착한 데이터들의 RDD 집합이다.
Structured Streaming
- 스파크의 API(DataFrame, Dataset, SQL)을 지원하기 때문에 배치성으로 작성된 코드들을 사용할 수 있다.
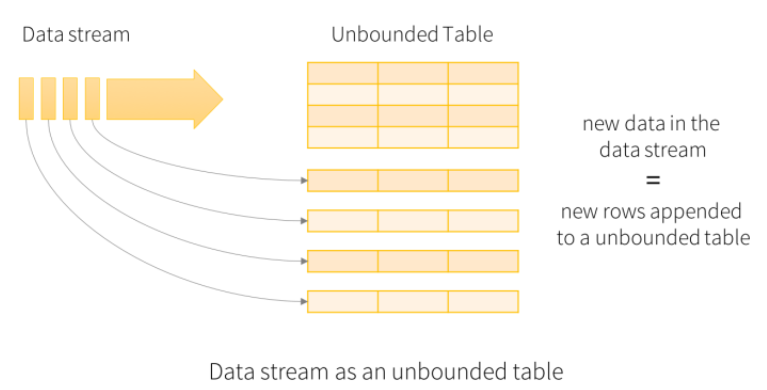
- Structured Streaming은 배치 개념이 없다. 입력 데이터 스트림을 "input table"로 간주하고, 트리거에서 수신되는 모든 데이터는 데이터 스트림에 추가되며, 스트림의 각 행은 result table로 업데이트 된다.
정리하자면
😤 그래서 왜 Structured Streaming가 더 좋은데?
-
실시간 처리 기능
Structured Streaming은 배치 처리를 하지 않고 데이터를 데이터 스트림에 계속 추가함으로써 지연이 거의 없는 데이터 처리를 수행한다. Spark Streaming은 input 데이터를 배치 작업으로 처리하며 DStream으로 생성한는 작업을 거치기 때문에 배치 처리를 하지 않는 Structured Streaming에 비해 실시간 처리 기능이 떨어진다. -
RDD vs DataFrame/DataSet
Structured Streaming은 DataFrame과 Dataset을, Spark Streaming은 RDD를 사용해 스트리밍 처리를 한다. RDD와 Dataframe을 비교해봤을 때 성능과 사용 용의성 측면에서 DataFrame이 더욱 우수하다. Spark: RDD vs DataFrames 이 글을 참고하자 -
이벤트 시간 처리
Structured Streaming은 이벤트 시간 처리 기능을 지원한다. 반면 Spark Streaming은 이 기능을 지원하지 않는다. 이벤트 시간은 실제로 이벤트가 발생한 시간, 즉 데이터가 실제로 들어온 시간이다. Structured Streaming은 이벤트 발생 시간을 기준으로 데이터를 처리하는 기능을 제공하기 때문에, 지연된 데이터를 정확히 처리할 수 있다.
03. Streaming + Kafka 방식 비교
Spark Streaming
- pyspark.streaming 라이브러리를 이용해서 Discretized Stream을 소스 데이터로 transform 한다.
Spark Streaming Programming Guide 참고
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# Create a local StreamingContext with two working thread and batch interval of 1 second
sc = SparkContext("local[2]", "NetworkWordCount")
ssc = StreamingContext(sc, 1)
# Create a DStream that will connect to hostname:port, like localhost:9999
lines = ssc.socketTextStream("localhost", 9999)
# Split each line into words
words = lines.flatMap(lambda line: line.split(" "))
# Count each word in each batch
pairs = words.map(lambda word: (word, 1))
wordCounts = pairs.reduceByKey(lambda x, y: x + y)
# Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.pprint()
ssc.start() # Start the computation
ssc.awaitTermination() # Wait for the computation to terminate
$ ./bin/spark-submit examples/src/main/python/streaming/network_wordcount.py localhost 9999
Structured Streaming
- Structured Streaming에서는 readStream, writeStream을 사용해 input, output을 설정해 로직을 수행한다.
Structured Streaming Programming Guide 참고
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
spark = SparkSession \
.builder \
.appName("StructuredNetworkWordCount") \
.getOrCreate()
# Create DataFrame representing the stream of input lines from connection to localhost:9999
lines = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9999) \
.load()
# Split the lines into words
words = lines.select(
explode(
split(lines.value, " ")
).alias("word")
)
# Generate running word count
wordCounts = words.groupBy("word").count()
# Start running the query that prints the running counts to the console
query = wordCounts \
.writeStream \
.outputMode("complete") \
.format("console") \
.start()
query.awaitTermination()
$ ./bin/spark-submit examples/src/main/python/sql/streaming/structured_network_wordcount.py localhost 9999
🎈 Reference
- Spark Streaming vs. Structured Streaming
- Spark로 실시간 데이터 처리하기 (Intro)
- Structured Streaming Programming Guide
- Spark Streaming Programming Guide
- Structured Streaming + Kafka Integration Guide (Kafka broker version 0.10.0 or higher)
- Spark Streaming + Kafka Integration Guide (Kafka broker version 0.8.2.1 or higher)
