Spark 개념
Spark 란
-
Hadoop : HDFS + MapReduce
- 병렬처리(parallezation)
- 데이터 분산(Distribution)
- 장애 내성(Fault Tolerance) -> 복제
- Job --> MapReduce
[Job 1] -------------> [Job2]
-> HDFS 저장
-
Spark :
[ 참조] : https://wikidocs.net/26139-
병렬처리
-
데이터 분산
-
인 메모리 데이터 처리
-
장애 내성(Fault Tolerance) -> RDD
-
JVM Object 중 Distribute Collection(Map,Set,, )
-
함수지향적 언어 (scalar, python,,, java)
-
Funtional Operator (map, filter, ,,,,, )
-
Job --> spark (In-Memroy 실행 모델) : Hadoop100 배의 성능 처리
[Job 1] -------------> [Job2]
-> In-Memory 유지 -
스파크쉘(spark-shell) <-- REPL (Read-Eval-Print Loop)
- scalar,python,r,java,sql -
스파크 라이브러리
- Spark Sql , Spark Stream, MLib, GraphX -
클러스터 매니저(Cluster Manager)
- Standalone , Mesos, Yarn
-
-
Data 처리 그릇 : RDD , DataFrame, DataSet(
[ 참조 ] https://artist-developer.tistory.com/17-
RDD(Resilient Distributed Data)
- Resilient (Data 복구)
- Lineage (Data 혈통/족보) --> Data 의 처리/연산 순서
- 일정한 방향성을 Job 실행
- RDD Lineage는 DAG(Directed Acyclic Graph)
- RDD 동작 원리의 핵심은 Lazy EvaluationRDD 처리 연산
- transform[변환] : RDD[n] 생성 => filter, map
- action(행동): 계산결과 반환, RDD 요소의 특정 작업 => count, foreach
-
DataFrame
- (Pandas,R, Excel Sheet)
- 행/열 Data
- column을 가질수 있다. -
DataSet
- Data 의 Schema(구조)를 포함
- 행/열 Data
- column을 가질수 있다.
-
Scala 실습
- 함수형 언어
- HelloWorldObject 테스트
--------------------------------------------------------------------------
[참조] https://www.scala-lang.org/download/2.12.10.html
wget https://downloads.lightbend.com/scala/2.12.10/scala-2.12.10.tgz
tar -xvzf scala-2.12.10.tgz
cp -r scala-2.12.10 ../scala-2.12.10
vi .bashrc
export SCALA_HOME=/home/hadoop/scala-2.12.10
export PATH=$PATH:~~~~~~:$SCALA_HOME/bin
cat > HelloWorldObject.scala
// main 함수를 생성App 을 상속하여 실행하는 방법
object HelloWorldObject {
def main(args: Array[String]): Unit = {
println("Hello World main")
}
}
scalac HelloWorldObject.scala
scala HelloWorldObject
--------------------------------------------------------------------------
- 객체
- 자료형
- 문자열
- 변수 -> var, val
- 함수 -> def 함수( ) = { }
def add(x: Int, y: Int): Int = { return x + y }
add(2,3)
- 람다함수
(x: Int, y: Int): Int => x + y
def exec(f(x: Int, y: Int): Int => x + y, 2, 3
def exec(f: (Int, Int) => Int, x: Int, y: Int) = f(x, y)
exec((x: Int, y: Int) => x + y, 2, 3)
- 커링 -
(Quiz) 6의 배수 확인법
1) 6의 배수인지 -> 6으로 나누기
def modN(n:Int, x:Int) = ((x%n) ==0)
def modN(n:Int)(x:Int) = ((x%n) ==0)
def modSix:Int => Boolean = modN(6)
modSix(15)
modSix(12)
2) 6의 배수인지 ->2로, 3으로 나누기
def modN(n1:Int, n2:Int, x:Int) = ( ((x%n1)==0) &&((x%n2) ==0) )
-------------------------------
def modN(n1:Int, n2:Int) (x:Int) = ( ((x%n1)==0) &&((x%n2) ==0) )
def modSix:Int => Boolean = modN(3,2)
-------------------------------
def modN(n1:Int) (n2:Int) (x:Int) = ( ((x%n1)==0) &&((x%n2) ==0) )
def modSix:Int => Boolean = modN(3)(2)
--------------------------------
modSix(4)
modSix(24)
modSix(25)
- 420 = 3 4 5 7
(Quiz) 420의 x,y 배수 확인법
def modN(n:Int, x:Int, y:Int) = ( ((n%x)==0) &&((n%y) ==0) )
- 클래스 -
- 멤버변수, 메소드, 메소드 오버라이드, 생성자
- 상속, 추상(abstract) 클래스
- 봉인(sealed) 클래스
- 콜렉션
- 배열(array),
- 리스트(list), 셋(set), 튜플(tuple),
- 맵(map) : key,value 형태
- 반복문 : for , 조건식, do..while, while
- 정렬, 그룹핑, 필터링 함수
- map
- reduce, fold
- groupBy
- filter
- zip
- mapValues
- sort
버전 확인
> scala.util.Properties.versionString
- String = version 2.12.10Spark RDD 실습
[scala : 실습예제 01 : LICENSE파일에 BSD 몇 개있어요? ]
/ spark-shell /
sc
-> org.apache.spark.SparkContext = org.apache.spark.SparkContext@64027866
val licLines = sc.textFile("/home/hadoop/spark-3.1.2/LICENSE")
val lineCnt = licLines.count
val bsdLines = licLines.filter(line => line.contains("BSD"))
bsdLines.count
def isBSD(line: String) = { line.contains("BSD") }
val isBSD = (line: String) => line.contains("BSD")
val bsdLines1 = licLines.filter(isBSD)
bsdLines1.count
bsdLines.foreach(bLine => println(bLine))[scala : 실습예제 02 : map 변환 연산자 ]
//# def map[B](f: (A) ⇒ B): Traversable[B]
//# def map[U](f: (T) => U): RDD[U]
val numbers = sc.parallelize(10 to 50 by 10)
numbers.foreach(x => println(x))
val numbersSquared = numbers.map(num => num * num)
numbersSquared.foreach(x => println(x))
val reversed = numbersSquared.map(x => x.toString.reverse)
reversed.foreach(x => println(x))
# _ -> 밑줄문자 : placeholder (자기객체의 요소)
val alsoReversed = numbersSquared.map(_.toString.reverse)
alsoReversed.foreach(x => println(x))
alsoReversed.first
alsoReversed.top(4)[scala : 실습예제 03 : client-ids.log 파일의 변환 ]
$ echo "15,16,20,20,77,80,94,94,98,16,31,31,15,20" > client-ids.log
val lines = sc.textFile("/home/hadoop/data/client-ids.log")
val idsStr = lines.map(line => line.split(","))
idsStr.foreach(println(_))
idsStr.first
idsStr.collect
//# def flatMap[U](f: (T) => TraversableOnce[U]): RDD[U]
// flatMap <-- 단일 배열(array) 화 함수
val ids = lines.flatMap(_.split(","))
ids.collect
ids.first
ids.collect.mkString("; ")
val intIds = ids.map(_.toInt)
intIds.collect--> 일정기간 접속한 id는 몇명 ?
//# def distinct(): RDD[T]
val uniqueIds = intIds.distinct
uniqueIds.collect
val finalCount = uniqueIds.count
val transactionCount = ids.count
//# def sample(withReplacement: Boolean, fraction: Double, seed: Long = Utils.random.nextLong): RDD[T]
val s = uniqueIds.sample(false, 0.3)
s.count
s.collect
val swr = uniqueIds.sample(true, 0.5)
swr.count
swr.collect
//# def takeSample(withReplacement: Boolean, num: Int, seed: Long = Utils.random.nextLong): Array[T]
val taken = uniqueIds.takeSample(false, 5)
uniqueIds.take(3)
//Implicit conversion: 클래스, 묵시적 형변환 함수 선언
class ClassOne[T](val input: T) { }
class ClassOneStr(val one: ClassOne[String]) {
def duplicatedString() = one.input + one.input
}
class ClassOneInt(val one: ClassOne[Int]) {
def duplicatedInt() = one.input.toString + one.input.toString
}
implicit def toStrMethods(one: ClassOne[String]) = new ClassOneStr(one)
implicit def toIntMethods(one: ClassOne[Int]) = new ClassOneInt(one)
val oneStrTest = new ClassOne("test")
val oneIntTest = new ClassOne(123)
oneStrTest.duplicatedString()
oneIntTest.duplicatedInt()double RDD 함수를 통한 기초통계량
intIds.mean
intIds.sum
intIds.variance
intIds.stdev히스토그램 histogram --> hist
intIds.histogram(Array(1.0, 50.0, 100.0))
intIds.histogram(3)PairRDD: [ key, value ] <- map(java,scala), dictionary(python)
[파일] data_products.txt
[파일] data_transactions.txt
--> 2015-03-30#12:46 AM#51#50#6#7501.89
--> 구매날짜#구매시간#고객ID#상품ID#수량#구매금액
==> 1) 최대횟수로 구매고객에게 곰인형 사은품 증정하기
--> 고객ID별 총 구매금액
val tranFile = sc.textFile("/home/hadoop/data/data_transactions.txt")
val tranData = tranFile.map(_.split("#"))
tranData.collect
var transByCust = tranData.map(tran => (tran(2).toInt, tran))
transByCust.countByKey()
transByCust.countByKey().values.sum#. 구매횟수가 가장 많았던 고객의 ID 와 구매숫자
val (cid, purch) = transByCust.countByKey().toSeq.sortBy(_._2).last
#. 구매횟수가 가장 많았던 고객에게 곰인형 사은품을 보낸 내용 기록
var complTrans = Array(Array("2015-03-30", "11:59 PM", "53", "4", "1", "0.00"))#. 53번 고객의 모든 구매기록 출력
transByCust.lookup(53)
transByCust.lookup(53).foreach(tran => println(tran.mkString(", ")))==> 2) Barbie Shopping Mall Playset 를 2개 이상 구매한 고객에게 5% 할인
--> 판매품 25#Barbie Shopping Mall Playset#437.5#9
--> 구매목록 2015-03-30#12:46 AM#51#50#6#7501.89
transByCust = transByCust.mapValues(tran => {
if(tran(3).toInt == 25 && tran(4).toDouble > 1)
tran(5) = (tran(5).toDouble * 0.95).toString
tran })==> 3) 81번 Dictionary 상품을 5권 이상 구매한 고객에게 70번 상품 칫솔을 보내기
--> 판매품 81#Dictionary#29.65#4
70#Toothbrush#5.1#1
transByCust = transByCust.flatMapValues(tran => {
if(tran(3).toInt == 81 && tran(4).toInt >= 5) {
val cloned = tran.clone()
cloned(5) = "0.00"; cloned(3) = "70"; cloned(4) = "1";
List(tran, cloned)
}
else
List(tran)
})#. reduceByKey, foldByKey
==> 3) 최대 구매금액을 가진 고객을 찾아라
--> 구매목록 2015-03-30#12:46 AM#51#50#6#7501.89
val amounts = transByCust.mapValues(t => t(5).toDouble)
val totals = amounts.foldByKey(0)((p1, p2) => p1 + p2).collect()
totals.toSeq.sortBy(_._2).last
amounts.foldByKey(100000)((p1, p2) => p1 + p2).collect()
complTrans = complTrans :+ Array("2015-03-30", "11:59 PM", "76", "63", "1", "0.00")
transByCust = transByCust.union(sc.parallelize(complTrans).map(t => (t(2).toInt, t)))
transByCust.map(t => t._2.mkString("#")).saveAsTextFile("output-transByCust")#. aggregateByKey
==> 4) 고객별 구매목록
val prods = transByCust.aggregateByKey(List[String]())(
(prods, tran) => prods ::: List(tran(3)),
(prods1, prods2) => prods1 ::: prods2)
prods.collect()wiki 데이터 사용 실습
- wiki 관련 데이터 download
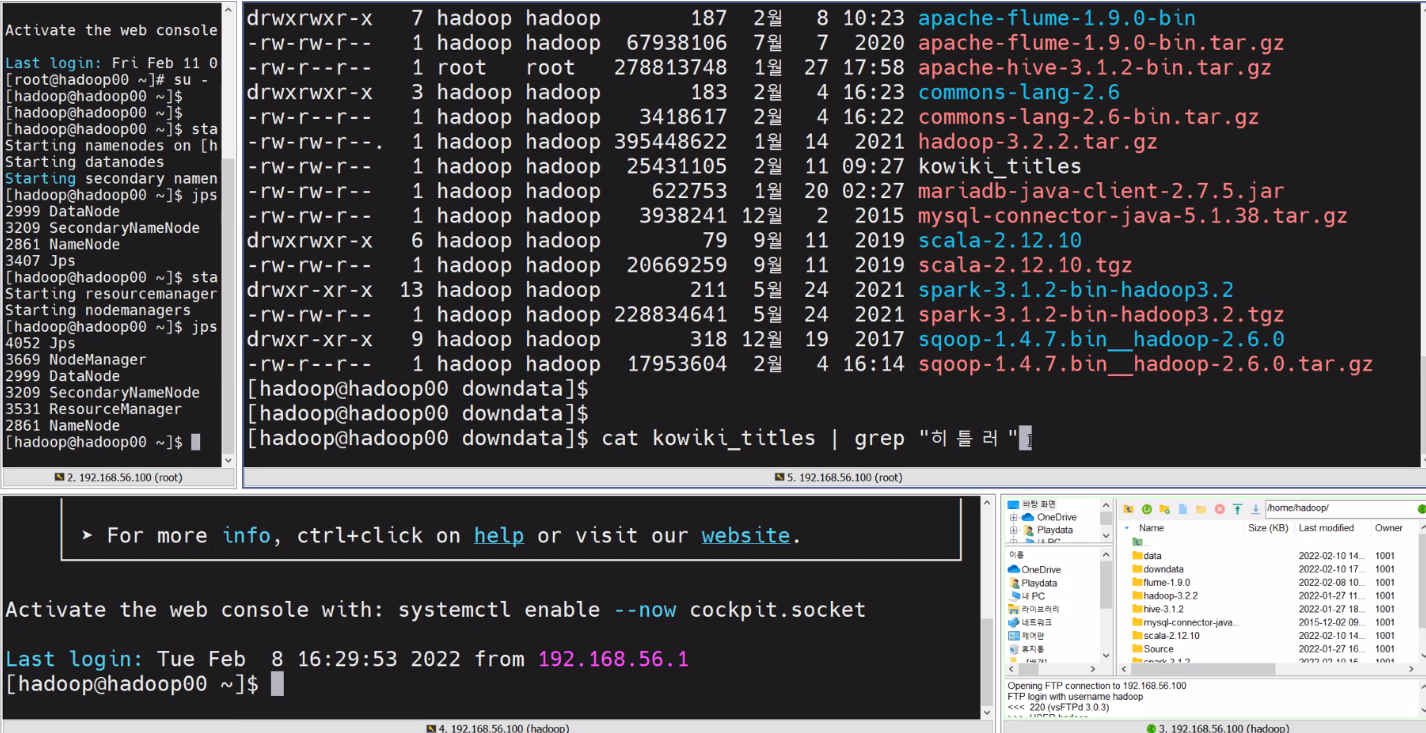
curl https://dumps.wikimedia.org/kowiki/latest/kowiki-latest-all-titles-in-ns0.gz | zcat > kowiki_titles

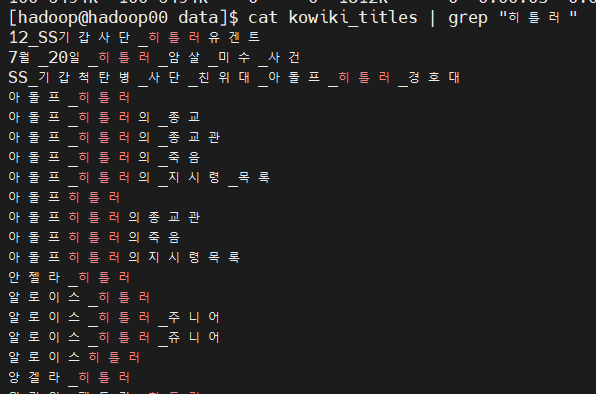
- 히틀러라는 단어 grep
cat kowiki_titles | grep "히틀러"
spark-shell
kowiki_titles 파일에서 히틀러라는 단어 grep
-
var lines = sc.textFile("/home/hadoop/data/kowiki_titles")
lines.count

-
var words= lines.flatMap(x=>x.split("_"))
words.count

-
var filterTest = words.filter(line=>line.contains("히틀러"))
filterTest.count

-
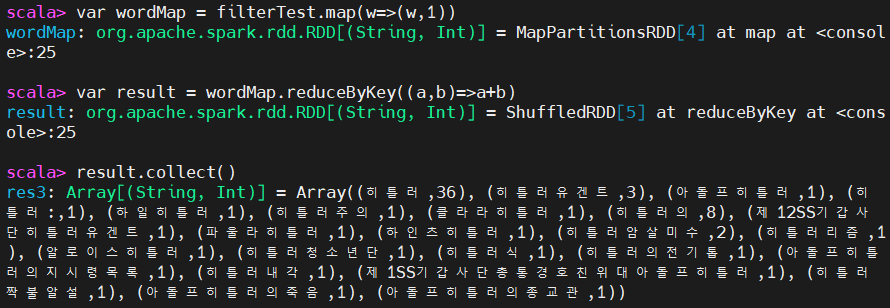
var wordMap = filterTest.map(w=>(w,1))
var result = wordMap.reduceByKey((a,b)=>a+b) # 누적시키며 count
result.collect()
pyspark
kowiki_titles 파일에서 히틀러라는 단어 grep
text_file = sc.textFile("/home/hadoop/data/kowiki_titles", use_unicode=True)
counts=text_file.flatMap(lambda line: str(line).split("_")) \
.filter(lambda x: "히틀러" in x) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.collect()
counts.first()
counts.count()
counts.take(4)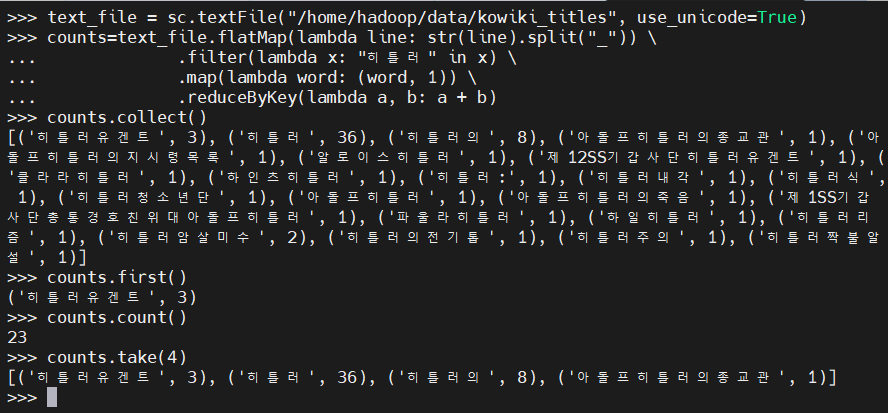
spark-scala-DataFrame-DataSet
-- (11) -------------------------------------------------------------------------------
import spark.implicits._
val itPostsRows = sc.textFile("/home/hadoop/data/italianPosts.csv")
val itPostsSplit = itPostsRows.map(x => x.split("~"))
val itPostsRDD = itPostsSplit.map(x => (x(0),x(1),x(2),x(3),x(4),x(5),x(6),x(7),x(8),x(9),x(10),x(11),x(12)))
val itPostsDFrame = itPostsRDD.toDF()
itPostsDFrame.show(10)
val itPostsDF = itPostsRDD.toDF("commentCount", "lastActivityDate", "ownerUserId", "body", "score", "creationDate", "viewCount", "title", "tags", "answerCount", "acceptedAnswerId", "postTypeId", "id")
itPostsDF.printSchema
import java.sql.Timestamp
case class Post (commentCount:Option[Int], lastActivityDate:Option[java.sql.Timestamp],
ownerUserId:Option[Long], body:String, score:Option[Int], creationDate:Option[java.sql.Timestamp],
viewCount:Option[Int], title:String, tags:String, answerCount:Option[Int],
acceptedAnswerId:Option[Long], postTypeId:Option[Long], id:Long)
object StringImplicits {
implicit class StringImprovements(val s: String) {
import scala.util.control.Exception.catching
def toIntSafe = catching(classOf[NumberFormatException]) opt s.toInt
def toLongSafe = catching(classOf[NumberFormatException]) opt s.toLong
def toTimestampSafe = catching(classOf[IllegalArgumentException]) opt Timestamp.valueOf(s)
}
}
import StringImplicits._
def stringToPost(row:String):Post = {
val r = row.split("~")
Post(r(0).toIntSafe,
r(1).toTimestampSafe,
r(2).toLongSafe,
r(3),
r(4).toIntSafe,
r(5).toTimestampSafe,
r(6).toIntSafe,
r(7),
r(8),
r(9).toIntSafe,
r(10).toLongSafe,
r(11).toLongSafe,
r(12).toLong)
}
val itPostsDFCase = itPostsRows.map(x => stringToPost(x)).toDF()
itPostsDFCase.printSchema
import org.apache.spark.sql.types._
val postSchema = StructType(Seq(
StructField("commentCount", IntegerType, true),
StructField("lastActivityDate", TimestampType, true),
StructField("ownerUserId", LongType, true),
StructField("body", StringType, true),
StructField("score", IntegerType, true),
StructField("creationDate", TimestampType, true),
StructField("viewCount", IntegerType, true),
StructField("title", StringType, true),
StructField("tags", StringType, true),
StructField("answerCount", IntegerType, true),
StructField("acceptedAnswerId", LongType, true),
StructField("postTypeId", LongType, true),
StructField("id", LongType, false))
)
import org.apache.spark.sql.Row
def stringToRow(row:String):Row = {
val r = row.split("~")
Row(r(0).toIntSafe.getOrElse(null),
r(1).toTimestampSafe.getOrElse(null),
r(2).toLongSafe.getOrElse(null),
r(3),
r(4).toIntSafe.getOrElse(null),
r(5).toTimestampSafe.getOrElse(null),
r(6).toIntSafe.getOrElse(null),
r(7),
r(8),
r(9).toIntSafe.getOrElse(null),
r(10).toLongSafe.getOrElse(null),
r(11).toLongSafe.getOrElse(null),
r(12).toLong)
}
val rowRDD = itPostsRows.map(row => stringToRow(row))
val itPostsDFStruct = spark.createDataFrame(rowRDD, postSchema)
itPostsDFStruct.columns
itPostsDFStruct.dtypes
-- (12) ------------------------------------------------------------------------------------
val postsDf = itPostsDFStruct
val postsIdBody = postsDf.select("id", "body")
val postsIdBody = postsDf.select(postsDf.col("id"), postsDf.col("body"))
val postsIdBody = postsDf.select(Symbol("id"), Symbol("body"))
val postsIdBody = postsDf.select('id, 'body)
val postsIdBody = postsDf.select($"id", $"body")
val postIds = postsIdBody.drop("body")
postsIdBody.filter('body contains "Italiano").count()
val noAnswer = postsDf.filter(('postTypeId === 1) and ('acceptedAnswerId isNull))
val firstTenQs = postsDf.filter('postTypeId === 1).limit(10)
val firstTenQsRn = firstTenQs.withColumnRenamed("ownerUserId", "owner")
postsDf.filter('postTypeId === 1).withColumn("ratio", 'viewCount / 'score).where('ratio < 35).show()
//The 10 most recently modified questions:
postsDf.filter('postTypeId === 1).orderBy('lastActivityDate desc).limit(10).show
-- (13) ------------------------------------------------------------------------------------
import org.apache.spark.sql.functions._
postsDf.filter('postTypeId === 1).withColumn("activePeriod", datediff('lastActivityDate, 'creationDate)).orderBy('activePeriod desc).head.getString(3).replace("<","<").replace(">",">")
//res0: String = <p>The plural of <em>braccio</em> is <em>braccia</em>, and the plural of <em>avambraccio</em> is <em>avambracci</em>.</p><p>Why are the plural of those words so different, if they both are referring to parts of the human body, and <em>avambraccio</em> derives from <em>braccio</em>?</p>
postsDf.select(avg('score), max('score), count('score)).show
import org.apache.spark.sql.expressions.Window
postsDf.filter('postTypeId === 1).select('ownerUserId, 'acceptedAnswerId, 'score, max('score).over(Window.partitionBy('ownerUserId)) as "maxPerUser").withColumn("toMax", 'maxPerUser - 'score).show(10)
postsDf.filter('postTypeId === 1).select('ownerUserId, 'id, 'creationDate, lag('id, 1).over(Window.partitionBy('ownerUserId).orderBy('creationDate)) as "prev", lead('id, 1).over(Window.partitionBy('ownerUserId).orderBy('creationDate)) as "next").orderBy('ownerUserId, 'id).show()
val countTags = udf((tags: String) => "<".r.findAllMatchIn(tags).length)
val countTags = spark.udf.register("countTags", (tags: String) => "<".r.findAllMatchIn(tags).length)
postsDf.filter('postTypeId === 1).select('tags, countTags('tags) as "tagCnt").show(10, false)
-- (14) ------------------------------------------------------------------------------------
val cleanPosts = postsDf.na.drop()
cleanPosts.count()
postsDf.na.fill(Map("viewCount" -> 0))
val postsDfCorrected = postsDf.na.replace(Array("id", "acceptedAnswerId"), Map(1177 -> 3000))
-- (15) ------------------------------------------------------------------------------------
val postsRdd = postsDf.rdd
val postsMapped = postsDf.rdd.map(row => Row.fromSeq(
row.toSeq.updated(3, row.getString(3).replace("<","<").replace(">",">")).
updated(8, row.getString(8).replace("<","<").replace(">",">"))))
val postsDfNew = spark.createDataFrame(postsMapped, postsDf.schema)
-- (16) ------------------------------------------------------------------------------------
postsDfNew.groupBy('ownerUserId, 'tags, 'postTypeId).count.orderBy('ownerUserId desc).show(10)
postsDfNew.groupBy('ownerUserId).agg(max('lastActivityDate), max('score)).show(10)
postsDfNew.groupBy('ownerUserId).agg(Map("lastActivityDate" -> "max", "score" -> "max")).show(10)
postsDfNew.groupBy('ownerUserId).agg(max('lastActivityDate), max('score).gt(5)).show(10)
val smplDf = postsDfNew.where('ownerUserId >= 13 and 'ownerUserId <= 15)
smplDf.groupBy('ownerUserId, 'tags, 'postTypeId).count.show()
smplDf.rollup('ownerUserId, 'tags, 'postTypeId).count.show()
smplDf.cube('ownerUserId, 'tags, 'postTypeId).count.show()
spark.sql("SET spark.sql.caseSensitive=true")
spark.conf.set("spark.sql.caseSensitive", "true")
-- (17) ------------------------------------------------------------------------------------
val itVotesRaw = sc.textFile("/home/hadoop/data/talianVotes.csv").map(x => x.split("~"))
val itVotesRows = itVotesRaw.map(row => Row(row(0).toLong, row(1).toLong, row(2).toInt, Timestamp.valueOf(row(3))))
val votesSchema = StructType(Seq(
StructField("id", LongType, false),
StructField("postId", LongType, false),
StructField("voteTypeId", IntegerType, false),
StructField("creationDate", TimestampType, false))
)
val votesDf = spark.createDataFrame(itVotesRows, votesSchema)
val postsVotes = postsDf.join(votesDf, postsDf("id") === votesDf("postId"))
val postsVotesOuter = postsDf.join(votesDf, postsDf("id") === votesDf("postId"), "outer")
-- (31) ------------------------------------------------------------------------------------
postsDf.createOrReplaceTempView("posts_temp")
postsDf.write.saveAsTable("posts")
votesDf.write.saveAsTable("votes")
spark.catalog.listTables().show()
spark.catalog.listColumns("votes").show()
spark.catalog.listFunctions.show()
-- (32) ------------------------------------------------------------------------------------
val resultDf = sql("select * from posts")
spark-sql> select substring(title, 0, 70) from posts where postTypeId = 1 order by creationDate desc limit 3;
$ spark-sql -e "select substring(title, 0, 70) from posts where postTypeId = 1 order by creationDate desc limit 3"
-- (42) ------------------------------------------------------------------------------------
postsDf.write.format("json").saveAsTable("postsjson")
sql("select * from postsjson")
val props = new java.util.Properties()
props.setProperty("user", "user")
props.setProperty("password", "password")
postsDf.write.jdbc("jdbc:postgresql://postgresrv/mydb", "posts", props)
-- (43) ------------------------------------------------------------------------------------
val postsDf = spark.read.table("posts")
val postsDf = spark.table("posts")
val result = spark.read.jdbc("jdbc:postgresql://postgresrv/mydb", "posts", Array("viewCount > 3"), props)
sql("CREATE TEMPORARY TABLE postsjdbc "+
"USING org.apache.spark.sql.jdbc "+
"OPTIONS ("+
"url 'jdbc:postgresql://postgresrv/mydb',"+
"dbtable 'posts',"+
"user 'user',"+
"password 'password')")
sql("CREATE TEMPORARY TABLE postsParquet "+
"USING org.apache.spark.sql.parquet "+
"OPTIONS (path '/path/to/parquet_file')")
val resParq = sql("select * from postsParquet")
-- (55) ------------------------------------------------------------------------------------
val postsFiltered = postsDf.filter('postTypeId === 1).withColumn("ratio", 'viewCount / 'score).where('ratio < 35)
postsFiltered.explain(true)spark-pyspark-DataFrame-DataSet
from __future__ import print_function
-- (11) ------------------------------------------------------------------------------------
itPostsRows = sc.textFile("home/hadoop/data/italianPosts.csv")
itPostsSplit = itPostsRows.map(lambda x: x.split("~"))
itPostsRDD = itPostsSplit.map(lambda x: (x[0],x[1],x[2],x[3],x[4],x[5],x[6],x[7],x[8],x[9],x[10],x[11],x[12]))
itPostsDFrame = itPostsRDD.toDF()
itPostsDFrame.show(10)
# +---+--------------------+---+--------------------+---+--------------------+----+--------------------+--------------------+----+----+---+----+
# | _1| _2| _3| _4| _5| _6| _7| _8| _9| _10| _11|_12| _13|
# +---+--------------------+---+--------------------+---+--------------------+----+--------------------+--------------------+----+----+---+----+
# | 4|2013-11-11 18:21:...| 17|<p>The infi...| 23|2013-11-10 19:37:...|null| | |null|null| 2|1165|
# | 5|2013-11-10 20:31:...| 12|<p>Come cre...| 1|2013-11-10 19:44:...| 61|Cosa sapreste dir...| <word-choice>| 1|null| 1|1166|
# | 2|2013-11-10 20:31:...| 17|<p>Il verbo...| 5|2013-11-10 19:58:...|null| | |null|null| 2|1167|
# | 1|2014-07-25 13:15:...|154|<p>As part ...| 11|2013-11-10 22:03:...| 187|Ironic constructi...|<english-compa...| 4|1170| 1|1168|
# | 0|2013-11-10 22:15:...| 70|<p><em&g...| 3|2013-11-10 22:15:...|null| | |null|null| 2|1169|
# | 2|2013-11-10 22:17:...| 17|<p>There's ...| 8|2013-11-10 22:17:...|null| | |null|null| 2|1170|
# | 1|2013-11-11 09:51:...| 63|<p>As other...| 3|2013-11-11 09:51:...|null| | |null|null| 2|1171|
# | 1|2013-11-12 23:57:...| 63|<p>The expr...| 1|2013-11-11 10:09:...|null| | |null|null| 2|1172|
# | 9|2014-01-05 11:13:...| 63|<p>When I w...| 5|2013-11-11 10:28:...| 122|Is "scancell...|<usage><...| 3|1181| 1|1173|
# | 0|2013-11-11 10:58:...| 18|<p>Wow, wha...| 5|2013-11-11 10:58:...|null| | |null|null| 2|1174|
# +---+--------------------+---+--------------------+---+--------------------+----+--------------------+--------------------+----+----+---+----+
# only showing top 10 rows
itPostsDF = itPostsRDD.toDF(["commentCount", "lastActivityDate", "ownerUserId", "body", "score", "creationDate", "viewCount", "title", "tags", "answerCount", "acceptedAnswerId", "postTypeId", "id"])
itPostsDF.printSchema()
# root
# |-- commentCount: string (nullable = true)
# |-- lastActivityDate: string (nullable = true)
# |-- ownerUserId: string (nullable = true)
# |-- body: string (nullable = true)
# |-- score: string (nullable = true)
# |-- creationDate: string (nullable = true)
# |-- viewCount: string (nullable = true)
# |-- title: string (nullable = true)
# |-- tags: string (nullable = true)
# |-- answerCount: string (nullable = true)
# |-- acceptedAnswerId: string (nullable = true)
# |-- postTypeId: string (nullable = true)
# |-- id: string (nullable = true)
from pyspark.sql import Row
from datetime import datetime
def toIntSafe(inval):
try:
return int(inval)
except ValueError:
return None
def toTimeSafe(inval):
try:
return datetime.strptime(inval, "%Y-%m-%d %H:%M:%S.%f")
except ValueError:
return None
def toLongSafe(inval):
try:
return long(inval)
except ValueError:
return None
def stringToPost(row):
r = row.encode('utf8').split("~")
return Row(
toIntSafe(r[0]),
toTimeSafe(r[1]),
toIntSafe(r[2]),
r[3],
toIntSafe(r[4]),
toTimeSafe(r[5]),
toIntSafe(r[6]),
toIntSafe(r[7]),
r[8],
toIntSafe(r[9]),
toLongSafe(r[10]),
toLongSafe(r[11]),
long(r[12]))
from pyspark.sql.types import *
postSchema = StructType([
StructField("commentCount", IntegerType(), True),
StructField("lastActivityDate", TimestampType(), True),
StructField("ownerUserId", LongType(), True),
StructField("body", StringType(), True),
StructField("score", IntegerType(), True),
StructField("creationDate", TimestampType(), True),
StructField("viewCount", IntegerType(), True),
StructField("title", StringType(), True),
StructField("tags", StringType(), True),
StructField("answerCount", IntegerType(), True),
StructField("acceptedAnswerId", LongType(), True),
StructField("postTypeId", LongType(), True),
StructField("id", LongType(), False)
])
rowRDD = itPostsRows.map(lambda x: stringToPost(x))
itPostsDFStruct = sqlContext.createDataFrame(rowRDD, postSchema)
itPostsDFStruct.printSchema()
itPostsDFStruct.columns
itPostsDFStruct.dtypes
-- (12) ------------------------------------------------------------------------------------
postsDf = itPostsDFStruct
postsIdBody = postsDf.select("id", "body")
postsIdBody = postsDf.select(postsDf["id"], postsDf["body"])
postIds = postsIdBody.drop("body")
from pyspark.sql.functions import *
postsIdBody.filter(instr(postsIdBody["body"], "Italiano") > 0).count()
noAnswer = postsDf.filter((postsDf["postTypeId"] == 1) & isnull(postsDf["acceptedAnswerId"]))
firstTenQs = postsDf.filter(postsDf["postTypeId"] == 1).limit(10)
firstTenQsRn = firstTenQs.withColumnRenamed("ownerUserId", "owner")
postsDf.filter(postsDf.postTypeId == 1).withColumn("ratio", postsDf.viewCount / postsDf.score).where("ratio < 35").show()
#+------------+--------------------+-----------+--------------------+-----+--------------------+---------+-----+--------------------+-----------+----------------+----------+----+-------------------+
#|commentCount| lastActivityDate|ownerUserId| body|score| creationDate|viewCount|title| tags|answerCount|acceptedAnswerId|postTypeId| id| ratio|
#+------------+--------------------+-----------+--------------------+-----+--------------------+---------+-----+--------------------+-----------+----------------+----------+----+-------------------+
#| 5|2013-11-21 14:04:...| 8|<p>The use ...| 13|2013-11-11 21:01:...| 142| null|<prepositions&...| 2| 1212| 1|1192| 10.923076923076923|
#| 0|2013-11-12 09:26:...| 17|<p>When wri...| 5|2013-11-11 21:01:...| 70| null|<punctuation&g...| 4| 1195| 1|1193| 14.0|
#| 1|2013-11-12 12:53:...| 99|<p>I can't ...| -3|2013-11-12 10:57:...| 68| null|<grammar>&l...| 3| 1216| 1|1203|-22.666666666666668|
#| 3|2014-09-11 14:37:...| 63|<p>The plur...| 5|2013-11-12 13:34:...| 59| null|<plural><...| 1| 1227| 1|1221| 11.8|
#| 1|2013-11-12 13:49:...| 63|<p>I rememb...| 6|2013-11-12 13:38:...| 53| null|<usage><...| 1| 1223| 1|1222| 8.833333333333334|
#| 5|2013-11-13 00:32:...| 159|<p>Girando ...| 6|2013-11-12 23:50:...| 88| null|<grammar>&l...| 1| 1247| 1|1246| 14.666666666666666|
#| 0|2013-11-14 00:54:...| 159|<p>Mi A?ca...| 7|2013-11-14 00:19:...| 70| null| <verbs>| 1| null| 1|1258| 10.0|
#| 1|2013-11-15 12:17:...| 18|<p>Clearly ...| 7|2013-11-14 01:21:...| 68| null|<grammar>&l...| 2| null| 1|1262| 9.714285714285714|
#| 0|2013-11-14 21:14:...| 79|<p>Alle ele...| 8|2013-11-14 20:16:...| 96| null|<grammar>&l...| 1| 1271| 1|1270| 12.0|
#| 0|2013-11-15 17:12:...| 63|<p>In Itali...| 8|2013-11-15 14:54:...| 68| null|<usage><...| 1| 1277| 1|1275| 8.5|
#| 3|2013-11-19 18:08:...| 8|<p>The Ital...| 6|2013-11-15 16:09:...| 87| null|<grammar>&l...| 1| null| 1|1276| 14.5|
#| 1|2014-08-14 13:13:...| 12|<p>When I s...| 5|2013-11-16 09:36:...| 74| null|<regional>&...| 3| null| 1|1279| 14.8|
#| 10|2014-03-15 08:25:...| 176|<p>In Engli...| 12|2013-11-16 11:13:...| 148| null|<punctuation&g...| 2| 1286| 1|1285| 12.333333333333334|
#| 2|2013-11-17 15:54:...| 79|<p>Al di fu...| 7|2013-11-16 13:16:...| 70| null| <accents>| 2| null| 1|1287| 10.0|
#| 1|2013-11-16 19:05:...| 176|<p>Often ti...| 12|2013-11-16 14:16:...| 106| null|<verbs><...| 1| null| 1|1290| 8.833333333333334|
#| 4|2013-11-17 15:50:...| 22|<p>The verb...| 6|2013-11-17 14:30:...| 66| null|<verbs><...| 1| null| 1|1298| 11.0|
#| 0|2014-09-12 10:55:...| 8|<p>Wikipedi...| 10|2013-11-20 16:42:...| 145| null|<orthography&g...| 5| 1336| 1|1321| 14.5|
#| 2|2013-11-21 12:09:...| 22|<p>La parol...| 5|2013-11-20 20:48:...| 49| null|<usage><...| 1| 1338| 1|1324| 9.8|
#| 0|2013-11-22 13:34:...| 114|<p>There ar...| 7|2013-11-20 20:53:...| 69| null| <homograph>| 2| 1330| 1|1325| 9.857142857142858|
#| 6|2013-11-26 19:12:...| 12|<p>Sento ch...| -3|2013-11-21 21:12:...| 79| null| <word-usage>| 2| null| 1|1347|-26.333333333333332|
#+------------+--------------------+-----------+--------------------+-----+--------------------+---------+-----+--------------------+-----------+----------------+----------+----+-------------------+
# only showing top 20 rows
#The 10 most recently modified questions:
postsDf.filter(postsDf.postTypeId == 1).orderBy(postsDf.lastActivityDate.desc()).limit(10).show()
-- (13) ------------------------------------------------------------------------------------
from pyspark.sql.functions import *
postsDf.filter(postsDf.postTypeId == 1).withColumn("activePeriod", datediff(postsDf.lastActivityDate, postsDf.creationDate)).orderBy(desc("activePeriod")).head().body.replace("<","<").replace(">",">")
#<p>The plural of <em>braccio</em> is <em>braccia</em>, and the plural of <em>avambraccio</em> is <em>avambracci</em>.</p><p>Why are the plural of those words so different, if they both are referring to parts of the human body, and <em>avambraccio</em> derives from <em>braccio</em>?</p>
postsDf.select(avg(postsDf.score), max(postsDf.score), count(postsDf.score)).show()
from pyspark.sql.window import Window
winDf = postsDf.filter(postsDf.postTypeId == 1).select(postsDf.ownerUserId, postsDf.acceptedAnswerId, postsDf.score, max(postsDf.score).over(Window.partitionBy(postsDf.ownerUserId)).alias("maxPerUser"))
winDf.withColumn("toMax", winDf.maxPerUser - winDf.score).show(10)
# +-----------+----------------+-----+----------+-----+
# |ownerUserId|acceptedAnswerId|score|maxPerUser|toMax|
# +-----------+----------------+-----+----------+-----+
# | 232| 2185| 6| 6| 0|
# | 833| 2277| 4| 4| 0|
# | 833| null| 1| 4| 3|
# | 235| 2004| 10| 10| 0|
# | 835| 2280| 3| 3| 0|
# | 37| null| 4| 13| 9|
# | 37| null| 13| 13| 0|
# | 37| 2313| 8| 13| 5|
# | 37| 20| 13| 13| 0|
# | 37| null| 4| 13| 9|
# +-----------+----------------+-----+----------+-----+
postsDf.filter(postsDf.postTypeId == 1).select(postsDf.ownerUserId, postsDf.id, postsDf.creationDate, lag(postsDf.id, 1).over(Window.partitionBy(postsDf.ownerUserId).orderBy(postsDf.creationDate)).alias("prev"), lead(postsDf.id, 1).over(Window.partitionBy(postsDf.ownerUserId).orderBy(postsDf.creationDate)).alias("next")).orderBy(postsDf.ownerUserId, postsDf.id).show()
# +-----------+----+--------------------+----+----+
# |ownerUserId| id| creationDate|prev|next|
# +-----------+----+--------------------+----+----+
# | 4|1637|2014-01-24 06:51:...|null|null|
# | 8| 1|2013-11-05 20:22:...|null| 112|
# | 8| 112|2013-11-08 13:14:...| 1|1192|
# | 8|1192|2013-11-11 21:01:...| 112|1276|
# | 8|1276|2013-11-15 16:09:...|1192|1321|
# | 8|1321|2013-11-20 16:42:...|1276|1365|
# | 8|1365|2013-11-23 09:09:...|1321|null|
# | 12| 11|2013-11-05 21:30:...|null| 17|
# | 12| 17|2013-11-05 22:17:...| 11| 18|
# | 12| 18|2013-11-05 22:34:...| 17| 19|
# | 12| 19|2013-11-05 22:38:...| 18| 63|
# | 12| 63|2013-11-06 17:54:...| 19| 65|
# | 12| 65|2013-11-06 18:07:...| 63| 69|
# | 12| 69|2013-11-06 19:41:...| 65| 70|
# | 12| 70|2013-11-06 20:35:...| 69| 89|
# | 12| 89|2013-11-07 19:22:...| 70| 94|
# | 12| 94|2013-11-07 20:42:...| 89| 107|
# | 12| 107|2013-11-08 08:27:...| 94| 122|
# | 12| 122|2013-11-08 20:55:...| 107|1141|
# | 12|1141|2013-11-09 20:50:...| 122|1142|
# +-----------+----+--------------------+----+----+
countTags = udf(lambda (tags): tags.count("<"), IntegerType())
postsDf.filter(postsDf.postTypeId == 1).select("tags", countTags(postsDf.tags).alias("tagCnt")).show(10, False)
# +-------------------------------------------------------------------+------+
# |tags |tagCnt|
# +-------------------------------------------------------------------+------+
# |<word-choice> |1 |
# |<english-comparison><translation><phrase-request>|3 |
# |<usage><verbs> |2 |
# |<usage><tenses><english-comparison> |3 |
# |<usage><punctuation> |2 |
# |<usage><tenses> |2 |
# |<history><english-comparison> |2 |
# |<idioms><etymology> |2 |
# |<idioms><regional> |2 |
# |<grammar> |1 |
# +-------------------------------------------------------------------+------+
-- (14) ------------------------------------------------------------------------------------
cleanPosts = postsDf.na.drop()
cleanPosts.count()
postsDf.na.fill({"viewCount": 0}).show()
postsDf.na.replace(1177, 3000, ["id", "acceptedAnswerId"]).show()
-- (15) ------------------------------------------------------------------------------------
postsRdd = postsDf.rdd
def replaceLtGt(row):
return Row(
commentCount = row.commentCount,
lastActivityDate = row.lastActivityDate,
ownerUserId = row.ownerUserId,
body = row.body.replace("<","<").replace(">",">"),
score = row.score,
creationDate = row.creationDate,
viewCount = row.viewCount,
title = row.title,
tags = row.tags.replace("<","<").replace(">",">"),
answerCount = row.answerCount,
acceptedAnswerId = row.acceptedAnswerId,
postTypeId = row.postTypeId,
id = row.id)
postsMapped = postsRdd.map(replaceLtGt)
def sortSchema(schema):
fields = {f.name: f for f in schema.fields}
names = sorted(fields.keys())
return StructType([fields[f] for f in names])
postsDfNew = sqlContext.createDataFrame(postsMapped, sortSchema(postsDf.schema))
-- (16) ------------------------------------------------------------------------------------
postsDfNew.groupBy(postsDfNew.ownerUserId, postsDfNew.tags, postsDfNew.postTypeId).count().orderBy(postsDfNew.ownerUserId.desc()).show(10)
#+-----------+--------------------+----------+-----+
#|ownerUserId| tags|postTypeId|count|
#+-----------+--------------------+----------+-----+
#| 862| | 2| 1|
#| 855| <resources>| 1| 1|
#| 846|<translation><eng...| 1| 1|
#| 845|<word-meaning><tr...| 1| 1|
#| 842| <verbs><resources>| 1| 1|
#| 835| <grammar><verbs>| 1| 1|
#| 833| | 2| 1|
#| 833| <meaning>| 1| 1|
#| 833|<meaning><article...| 1| 1|
#| 814| | 2| 1|
#+-----------+--------------------+----------+-----+
postsDfNew.groupBy(postsDfNew.ownerUserId).agg(max(postsDfNew.lastActivityDate), max(postsDfNew.score)).show(10)
postsDfNew.groupBy(postsDfNew.ownerUserId).agg({"lastActivityDate": "max", "score": "max"}).show(10)
# +-----------+---------------------+----------+
# |ownerUserId|max(lastActivityDate)|max(score)|
# +-----------+---------------------+----------+
# | 431| 2014-02-16 14:16:...| 1|
# | 232| 2014-08-18 20:25:...| 6|
# | 833| 2014-09-03 19:53:...| 4|
# | 633| 2014-05-15 22:22:...| 1|
# | 634| 2014-05-27 09:22:...| 6|
# | 234| 2014-07-12 17:56:...| 5|
# | 235| 2014-08-28 19:30:...| 10|
# | 435| 2014-02-18 13:10:...| -2|
# | 835| 2014-08-26 15:35:...| 3|
# | 37| 2014-09-13 13:29:...| 23|
# +-----------+---------------------+----------+
postsDfNew.groupBy(postsDfNew.ownerUserId).agg(max(postsDfNew.lastActivityDate), max(postsDfNew.score) > 5).show(10)
# +-----------+---------------------+----------------+
# |ownerUserId|max(lastActivityDate)|(max(score) > 5)|
# +-----------+---------------------+----------------+
# | 431| 2014-02-16 14:16:...| false|
# | 232| 2014-08-18 20:25:...| true|
# | 833| 2014-09-03 19:53:...| false|
# | 633| 2014-05-15 22:22:...| false|
# | 634| 2014-05-27 09:22:...| true|
# | 234| 2014-07-12 17:56:...| false|
# | 235| 2014-08-28 19:30:...| true|
# | 435| 2014-02-18 13:10:...| false|
# | 835| 2014-08-26 15:35:...| false|
# | 37| 2014-09-13 13:29:...| true|
# +-----------+---------------------+----------------+
smplDf = postsDfNew.where((postsDfNew.ownerUserId >= 13) & (postsDfNew.ownerUserId <= 15))
smplDf.groupBy(smplDf.ownerUserId, smplDf.tags, smplDf.postTypeId).count().show()
# +-----------+----+----------+-----+
# |ownerUserId|tags|postTypeId|count|
# +-----------+----+----------+-----+
# | 15| | 2| 2|
# | 14| | 2| 2|
# | 13| | 2| 1|
# +-----------+----+----------+-----+
smplDf.rollup(smplDf.ownerUserId, smplDf.tags, smplDf.postTypeId).count().show()
# +-----------+----+----------+-----+
# |ownerUserId|tags|postTypeId|count|
# +-----------+----+----------+-----+
# | 15| | 2| 2|
# | 13| | null| 1|
# | 13|null| null| 1|
# | 14| | null| 2|
# | 13| | 2| 1|
# | 14|null| null| 2|
# | 15| | null| 2|
# | 14| | 2| 2|
# | 15|null| null| 2|
# | null|null| null| 5|
# +-----------+----+----------+-----+
smplDf.cube(smplDf.ownerUserId, smplDf.tags, smplDf.postTypeId).count().show()
# +-----------+----+----------+-----+
# |ownerUserId|tags|postTypeId|count|
# +-----------+----+----------+-----+
# | 15| | 2| 2|
# | null| | 2| 5|
# | 13| | null| 1|
# | 15|null| 2| 2|
# | null|null| 2| 5|
# | 13|null| null| 1|
# | 14| | null| 2|
# | 13| | 2| 1|
# | 14|null| null| 2|
# | 15| | null| 2|
# | 13|null| 2| 1|
# | null| | null| 5|
# | 14| | 2| 2|
# | 15|null| null| 2|
# | null|null| null| 5|
# | 14|null| 2| 2|
# +-----------+----+----------+-----+
-- (17) ------------------------------------------------------------------------------------
itVotesRaw = sc.textFile("/~~~~~~~~/italianVotes.csv").map(lambda x: x.split("~"))
itVotesRows = itVotesRaw.map(lambda row: Row(id=long(row[0]), postId=long(row[1]), voteTypeId=int(row[2]), creationDate=datetime.strptime(row[3], "%Y-%m-%d %H:%M:%S.%f")))
votesSchema = StructType([
StructField("creationDate", TimestampType(), False),
StructField("id", LongType(), False),
StructField("postId", LongType(), False),
StructField("voteTypeId", IntegerType(), False)
])
votesDf = sqlContext.createDataFrame(itVotesRows, votesSchema)
postsVotes = postsDf.join(votesDf, postsDf.id == votesDf.postId)
postsVotesOuter = postsDf.join(votesDf, postsDf.id == votesDf.postId, "outer")
-- (18) ------------------------------------------------------------------------------------
sqlContext.sql("SET spark.sql.caseSensitive=true")
sqlContext.setConf("spark.sql.caseSensitive", "true")
-- (21) ------------------------------------------------------------------------------------
postsDf.registerTempTable("posts_temp")
postsDf.write.saveAsTable("posts")
votesDf.write.saveAsTable("votes")
-- (22) ------------------------------------------------------------------------------------
resultDf = sqlContext.sql("select * from posts")
spark-sql> select substring(title, 0, 70) from posts where postTypeId = 1 order by creationDate desc limit 3;
$ spark-sql -e "select substring(title, 0, 70) from posts where postTypeId = 1 order by creationDate desc limit 3"
-- (31) ------------------------------------------------------------------------------------
postsDf.write.format("json").saveAsTable("postsjson")
sqlContext.sql("select * from postsjson")
props = {"user": "user", "password": "password"}
postsDf.write.jdbc("jdbc:postgresql:#postgresrv/mydb", "posts", properties=props)
-- (32) ------------------------------------------------------------------------------------
postsDf = sqlContext.read.table("posts")
postsDf = sqlContext.table("posts")
result = sqlContext.read.jdbc("jdbc:postgresql:#postgresrv/mydb", "posts", predicates=["viewCount > 3"], properties=props)
sqlContext.sql("CREATE TEMPORARY TABLE postsjdbc "+
"USING org.apache.spark.sql.jdbc "+
"OPTIONS ("+
"url 'jdbc:postgresql:#postgresrv/mydb',"+
"dbtable 'posts',"+
"user 'user',"+
"password 'password')")
sqlContext.sql("CREATE TEMPORARY TABLE postsParquet "+
"USING org.apache.spark.sql.parquet "+
"OPTIONS (path '/path/to/parquet_file')")
resParq = sql("select * from postsParquet")
-- (41) ------------------------------------------------------------------------------------
postsRatio = postsDf.filter(postsDf.postTypeId == 1).withColumn("ratio", postsDf.viewCount / postsDf.score)
postsFiltered = postsRatio.where(postsRatio.ratio < 35)
postsFiltered.explain(True)
# == Parsed Logical Plan ==
# 'Filter (ratio#314 < 35)
# +- Project [commentCount#285,lastActivityDate#286,ownerUserId#287L,body#288,score#289,creationDate#290,viewCount#291,title#292,tags#293,answerCount#294,acceptedAnswerId#295L,postTypeId#296L,id#297L,(cast(viewCount#291 as double) / cast(score#289 as double)) AS ratio#314]
# +- Filter (postTypeId#296L = cast(1 as bigint))
# +- Subquery posts
# +- Relation[commentCount#285,lastActivityDate#286,ownerUserId#287L,body#288,score#289,creationDate#290,viewCount#291,title#292,tags#293,answerCount#294,acceptedAnswerId#295L,postTypeId#296L,id#297L] ParquetRelation
#
# == Analyzed Logical Plan ==
# commentCount: int, lastActivityDate: timestamp, ownerUserId: bigint, body: string, score: int, creationDate: timestamp, viewCount: int, title: string, tags: string, answerCount: int, acceptedAnswerId: bigint, postTypeId: bigint, id: bigint, ratio: double
# Filter (ratio#314 < cast(35 as double))
# +- Project [commentCount#285,lastActivityDate#286,ownerUserId#287L,body#288,score#289,creationDate#290,viewCount#291,title#292,tags#293,answerCount#294,acceptedAnswerId#295L,postTypeId#296L,id#297L,(cast(viewCount#291 as double) / cast(score#289 as double)) AS ratio#314]
# +- Filter (postTypeId#296L = cast(1 as bigint))
# +- Subquery posts
# +- Relation[commentCount#285,lastActivityDate#286,ownerUserId#287L,body#288,score#289,creationDate#290,viewCount#291,title#292,tags#293,answerCount#294,acceptedAnswerId#295L,postTypeId#296L,id#297L] ParquetRelation
#
# == Optimized Logical Plan ==
# Project [commentCount#285,lastActivityDate#286,ownerUserId#287L,body#288,score#289,creationDate#290,viewCount#291,title#292,tags#293,answerCount#294,acceptedAnswerId#295L,postTypeId#296L,id#297L,(cast(viewCount#291 as double) / cast(score#289 as double)) AS ratio#314]
# +- Filter ((postTypeId#296L = 1) && ((cast(viewCount#291 as double) / cast(score#289 as double)) < 35.0))
# +- Relation[commentCount#285,lastActivityDate#286,ownerUserId#287L,body#288,score#289,creationDate#290,viewCount#291,title#292,tags#293,answerCount#294,acceptedAnswerId#295L,postTypeId#296L,id#297L] ParquetRelation
#
# == Physical Plan ==
# Project [commentCount#285,lastActivityDate#286,ownerUserId#287L,body#288,score#289,creationDate#290,viewCount#291,title#292,tags#293,answerCount#294,acceptedAnswerId#295L,postTypeId#296L,id#297L,(cast(viewCount#291 as double) / cast(score#289 as double)) AS ratio#314]
# +- Filter (((cast(viewCount#291 as double) / cast(score#289 as double)) < 35.0) && (postTypeId#296L = 1))
# +- Scan ParquetRelation[lastActivityDate#286,commentCount#285,acceptedAnswerId#295L,title#292,id#297L,postTypeId#296L,ownerUserId#287L,score#289,tags#293,viewCount#291,body#288,creationDate#290,answerCount#294] InputPaths: file:/user/hive/warehouse/posts, PushedFilters: [EqualTo(postTypeId,1)]
