Vanilla Neural Network
- 가장 기본적인 형태의 인공 신경망을 가리키는 용어
- 바닐라 신경망은 일반적으로 입력층, 출력층, 그리고 그 사이에 위치한 하나 이상의 은닉층으로 구성된다. 각 층은 여러 개의 뉴런으로 이루어져 있고, 이 뉴런들은 서로 가중치를 고려한 연결로 이어져 있다
- 이미지 또는 벡터를 입력으로 받아서 입력 하나가 Hidden layer를 거쳐서 하나의 출력을 내보낸다
- 출력이 Classification 문제라면 카테고리가 된다
- 하지만 Machine Learning의 관점에서 생각해보면 모델이 다양한 입력을 처리할 수 있도록 유연해질 필요가 있다
RNN
- 작은 "Recurrent Core Cell"을 가지고 있다
- 입력 x가 RNN으로 들어간다
- RNN에는 내부에 "hidden state"를 가지고 있다
- "hidden state"는 RNN이 새로운 입력을 불러들일 때마다 매번 업데이트된다
- "hidden state"는 모델에 feed back되고 이후에 또 다시 새로운 입력 x가 들어온다
- RNN이 매 단계마다 값을 출력하는 경우
- RNN이 입력을 받는다
- "hidden state"를 업데이트 한다
- 출력 값을 내보낸다
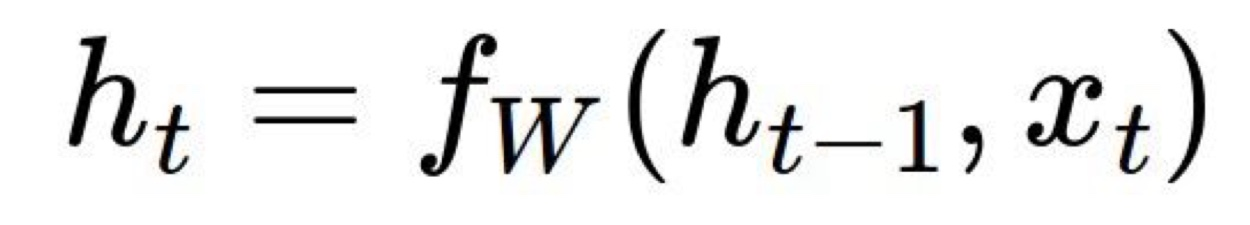
- h_t : 다음 상태의 hidden state
- fw : 파라미터 W를 가지는 함수 f
- h_t-1 : hidden state
- x_t : 입력
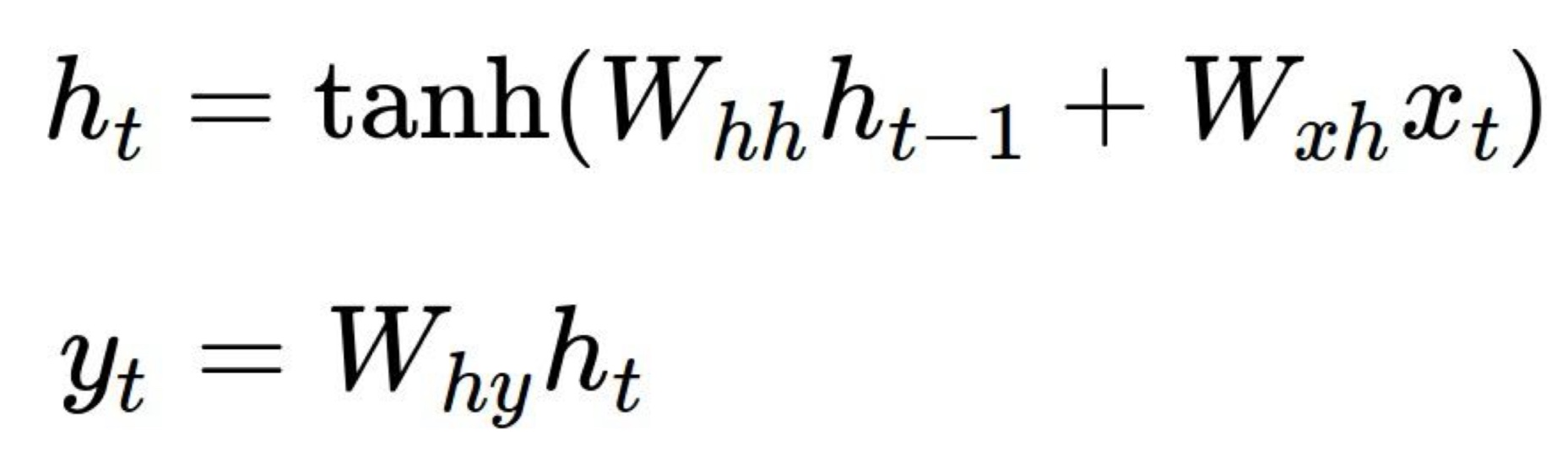
- h_t : 다음 상태의 hidden state
- W_hh : 가중치 행렬
- 이전 hidden state와 곱해지는 값
- h_t-1 : hidden state
- W_xh : 가중치 행렬
- x_t : 입력
- y_t : 출력
- System에 non-linearity를 구현하기 위해 tanh를 적용한다
RNN의 두가지 해석
RNN이 hidden state를 가지며 이를 "재귀적으로" feedback 한다
- Multiple time steps을 unrolling 해서 보면 헷갈리지 않는다
- Unrolling을 하면 hidden states, 입/출력, 가중치 행렬들간의 관계를 조금 더 명확히 이해할 수 있다
Many to Many의 경우
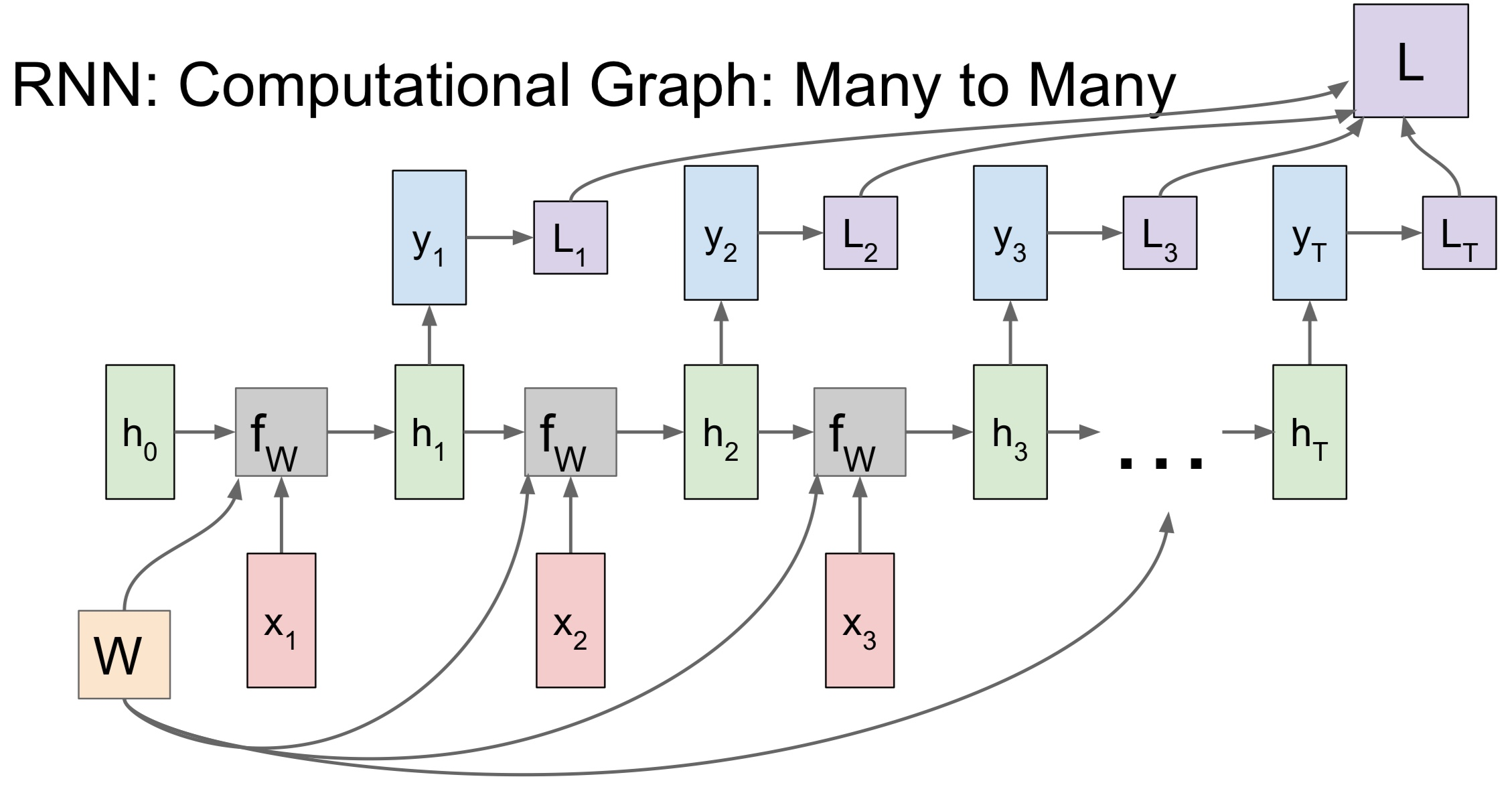
- h_t : initial hidden state
- h_0는 0으로 초기화시킨다
- x_t : 입력
- W : 가중치 행렬
- 매번 동일한 가중치 행렬이 사용된다
- 매번 h와 x는 달라지지만 W는 매번 동일하다
- y_t : 출력
- 예를 들어, 매 스텝의 class score가 될 수 있다
- L_t : Loss
- 함수 f와 파라미터 W는 매 스텝 동일하다
- 각 시퀀스마다 Ground truth label이 있다고 해보면 각 스텝마다 개별적으로 y_t에 대한 Loss를 계산할 수 있다
- Loss는 가령 softmax loss가 될 수 있다
- RNN의 최종 Loss는 각 개별 loss들의 합이다
- 각 단계에서 Loss가 발생하면 전부 더하여 최종 네트워크 Loss를 계산한다
- 이 네트워크의 Backprop을 생각해보면 모델을 학습시키려면 dLoss/dW를 구해야 한다
- Loss flowing은 각 스텝에서 이루어진다
- 이 경우에는 각 스텝마다 가중치 W에 대한 local gradient를 계산할 수 있다
- 이렇게 개별로 계산된 local gradient를 최종 gradient에 더한다
Many to One의 경우
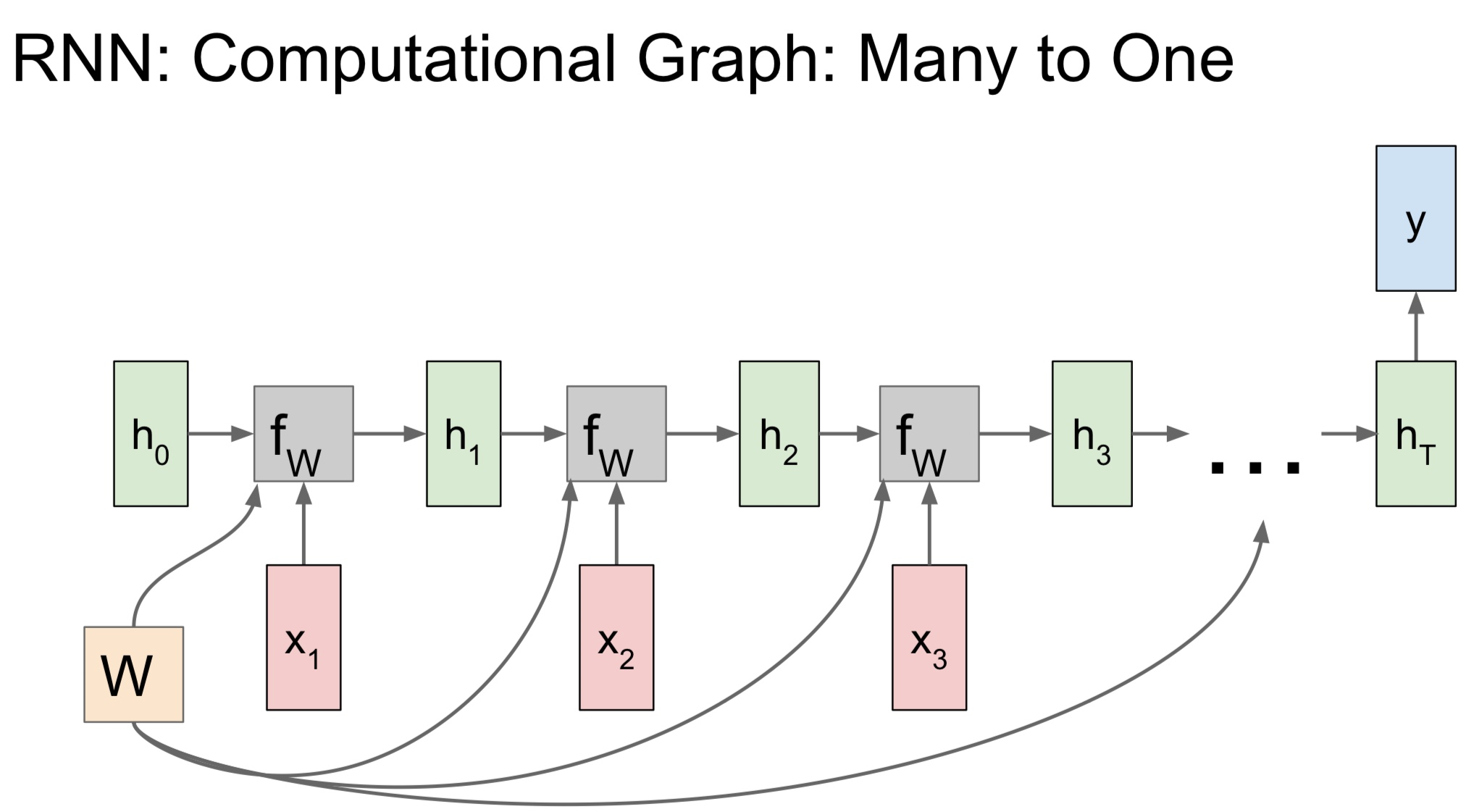
- 네트워크의 최종 hidden state에서만 결과 값이 나온다
- 최종 hidden state가 전체 시퀀스의 내용에 대한 일종의 요약으로 볼 수 있기 떄문이다
One to Many의 경우
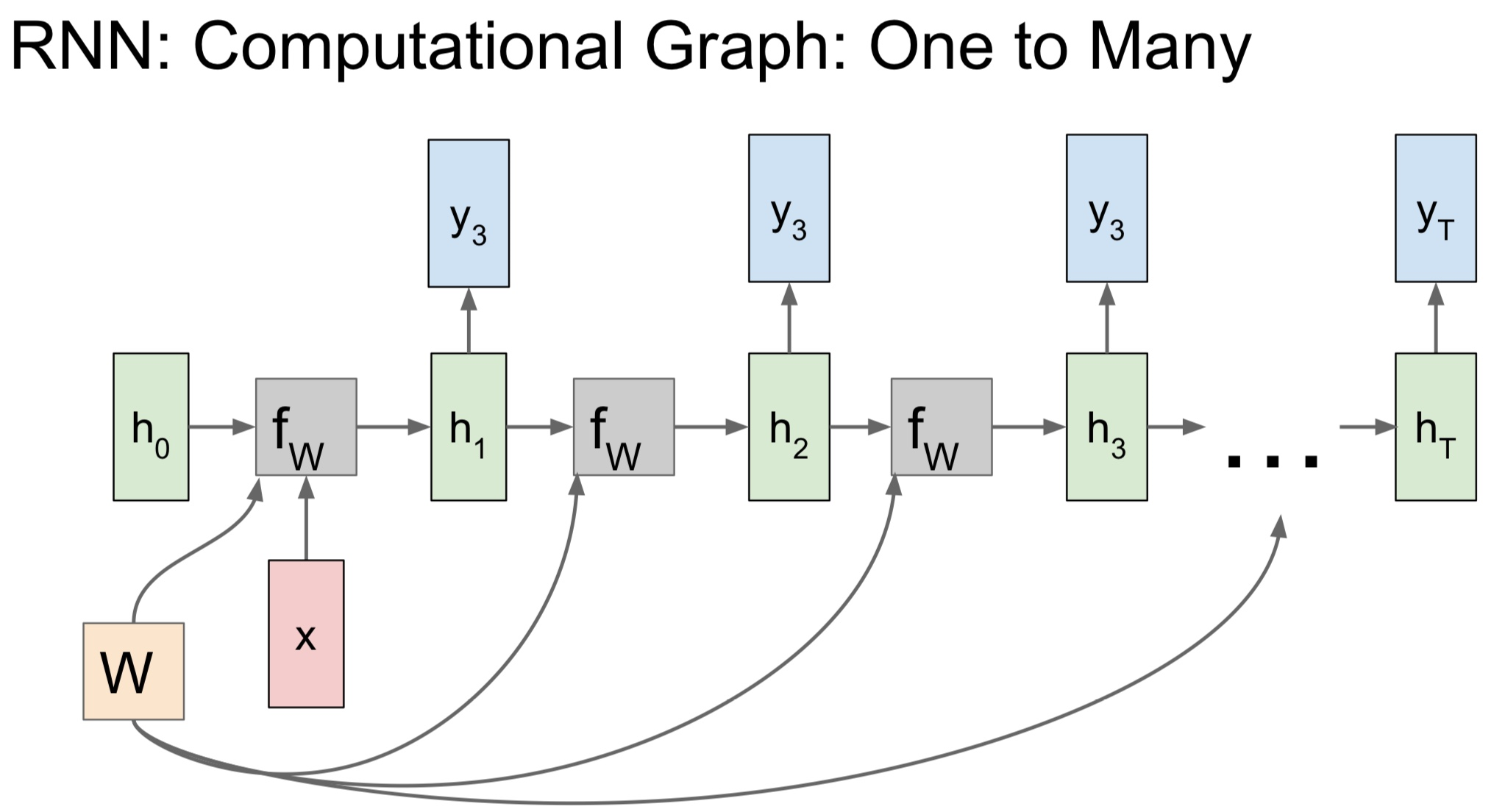
- "고정 입력" 을 받지만 "가변 출력"인 네트워크이다
- 이 경우에는 대게 고정 입력은 모델의 initial hidden state를 초기화시키는 용도로 사용한다
- 그리고 RNN은 모든 스텝에서 출력 값을 가진다
Sequence to Sequence 모델
이미지 삽입 p33
- "가변 입력" 과 "가변 출력" 을 가지는 모델이다
- "many to one" 모델과 "one to many" 모델의 결합으로 볼 수 있다
- encoder와 decoder 구조로 두 개의 스테이지로 구성된다
- encoder는 가변 입력을 받는다. 가령 English sentence가 될 수 있다
- encoder의 final hidden state 를 통해 전체 sentence를 요약한다
- Encoder 에서는 "many to one" 을 수행한다. "가변 입력"을 하나의 벡터로 요약한다
- 반면 Decoder는 "one to many"를 수행한다. 입력은 앞서 요약한 "하나의 벡터"이다
- 그리고 decoder는 "가변 출력"을 출력한다. 가령 다른 언어로 변역된 문장이 될 수 있다
- "가변 출력" 은 매 스텝 적절한 단어를 출력한다
- Output sentence의 각 losses를 합해서 Backprob을 진행한다
Truncated Backpropagation Through Time (TBPTT)
- 순환 신경망(RNN)에서 시간에 걸쳐 오차를 역전파하는 방법 중 하나이다
- 기본적인 Backpropagation Through Time (BPTT)은 모든 시간 단계에 대해 그래디언트를 계산하고 역전파한다. 그러나 이 방법은 시퀀스가 길어질수록 계산 비용이 매우 커지고, 그래디언트 소실 또는 폭발 문제가 발생할 수 있다. 이를 해결하기 위해 TBPTT 방법이 사용된다
- TBPTT는 시간 단계를 일정 구간으로 나누고, 각 구간에 대해 독립적으로 역전파를 수행한다
- 보통 100 단위로 자른다
- 100 스텝만 forward pass를 하고 이 서브스퀀스의 Loss를 계산한다. 그리고 gradient step을 진행한다
- 이 과정을 반복한다. 다만 이전 batch에서 계산한 hidden states는 계속 유지한다. 다음 Batch의 forward pass를 계산할 때는 이전 hidden state를 이용한다. 그리고 gradient step은 현재 Batch에서만 진행한다
이미지삽입 p43 44 45
Image Captioning
- Caption은 가변길이다. Caption 마다 다양한 시퀀스 길이를 가지고 있다
- Image Captioning은 RNN Language Model가 아주 잘 어울린다
- 모델에는 입력 이미지를 받기 위한 CNN이 있다. CNN은 요약된 이미지정보가 들어있는 Vector를 출력한다
- 이 Vector는 RNN의 초기 Step의 입력으로 들어간다. 그러면 RNN은 Caption에 사용할 문자들을 하나씩 만들어낸다
Test Time
- 우선 입력 이미지를 받아서 CNN의 입력으로 넣는다
- 다만 softmax scores를 사용하지 않고 직전의 4,096-dim vector를 출력으로 한다
- 이 vector를 이용해서 전체 이미지 정보를 요약하는데 사용할 것이다
- 모델이 문장을 생성해 내기에 앞서 초기 값을 넣어줘야 한다
- 이 경우에는 입력이 특별하다. 모델에게 "여기 이미지 정보가 있으니 이 조건에 맞는 문장을 만들어줘!" 라고 시작해야 한다
- 이전 까지의 모델에서는 RNN 모델이 두 개의 가중치 행렬을 입력으로 받았다. 하나는 현재 스텝의 입력이고 다른 하나는 이전 스텝의 Hidden state 이었다. 그리고 이 둘을 조합해서 다음 hidden state를 얻었다
- 하지만 이제는 이미지 정보도 더해줘야 한다
- 사람마다 모델에 이미지정보를 추가하는 방법이 다르겠지만 가장 쉬운 방법은 세 번째 가중치 행렬을 추가하는 것이다. 다음 hidden state를 계산할 때마다 모든 스텝에 이 이미지 정보를 추가한다
- 그 후 vocabulary의 모든 스코어들에 대한 분포를 계산한다. 이 문제에서 vocabulary는 "모든 영어 단어들"과 같이 엄청나게 크다
- 분포에서 샘플링을 하고 그 단어를 다음 스텝의 입력으로 다시 넣어준다
- 샘플링된 단어(y0)가 들어가면 다시 vacab에 대한 분포를 추정하고 다음 단어를 만들어낸다. 모든 스텝이 종료되면 결국 한 문장이 만들어진다
- 이 때, 라는 특별한 토큰이 있는데 이는 문장의 끝을 알려준다
- 가 샘플링되면 모델은 더이상 단어를 생성하지 않으며 이미지에 대한 caption이 완성된다
- Train time에는 모든 caption의 종료지점에 토큰을 삽입한다
- 네트워크가 학습하는 동안에 시퀀스의 끝에 토큰을 넣어야 한다는 것을 알려줘야 하기 때문이다
- 학습이 끝나고 Test time에는 모델이 문장 생성을 끝마치면 토큰을 샘플링한다
- 이 모델은 완전히 supervised learning으로 학습시킨다. 따라서 이 모델을 학습시키기 위해서는 natural language caption이 있는 이미지를 가지고 있어야 한다
- 이 모델을 학습시키기 위해서는 natural language model과 CNN을 동시에 backp 시킬 수 있다
Attention Model
- 기본적인 아이디어는, 모델이 입력 데이터의 다른 부분에 대해 다른 '주의' 또는 '가중치'를 둘 수 있게 하는 것이다
- 예를 들어, 번역 모델이 '나는 고양이를 좋아한다'라는 문장을 번역할 때, '고양이'라는 단어에 더 많은 주의를 기울이면 더 좋은 번역 결과를 얻을 수 있다
- Attention 모델은 이런 아이디어를 수학적으로 구현한 것으로, 입력 데이터의 각 부분에 대한 가중치(또는 '어텐션 스코어')를 계산한다
- 이 가중치는 일반적으로 입력 데이터의 중요도를 나타내며, 모델의 출력을 계산할 때 사용된다
- 이 모델은 Caption을 생성할 때 이미지의 다양한 부분을 집중해서(attention) 볼 수 있다
- 우선 CNN이 있는데 CNN으로 벡터 하나를 만드는게 아니라 각 벡터가 공간정보를 가지고 있는 grid of vector를 만들어낸다(LxD)
이미지 삽입 p81
- Forward pass 시에 매 스텝 vocabulary에서 샘플링을 할 때 모델이 이미지에서 보고싶은 위치에 대한 분포 또한 만들어낸다
- 이미지의 각 위치에 대한 분포는 Train time에 모델이 어느 위치를 봐야하는지에 대한 attention이라 할 수 있다
- 첫 번째 hidden state(h0)는 이미지의 위치에 대한 분포를 계산한다
- 이 분포(a1)를 다시 벡터 집합(LxD Feature)과 연산하여 이미지 attention(z1)을 생성한다
이미지 삽입 p83
- 요약된 벡터(z1)는 Neural network의 다음 스텝의 입력으로 들어간다. 그리고 두 개의 출력이 생성된다 (a2, d1)
- 하나는 vocabulary의 각 단어들의 분포이다(d1). 그리고 다른 하나(a2)는 이미지 위치에 대한 분포이다
이미지 삽입 p85
- 이 과정을 반복하면 매 스텝마다 값 두개(a, d)가 계속 만들어진다
이미지 삽입 p86
- Train을 끝마치면, 모델이 caption을 생성하기 위해서 이미지의 attention을 이동시키는 모습을 볼 수 있다
- 가령 여기 만들어진 caption은 "A bird flying over a body of water."이다
- caption을 만들 때 마다 이미지 내에 다양한 곳들에 attention을 주는 것을 볼 수 있다
- hard/soft attention의 개념이 있는데, soft attention의 경우에는 "모든 특징"과 "모든 이미지 위치"간의 weighted combination을 취하는 경우이다. 반면 hard attention의 경우에는 모델이 각 타임 스텝마다 단 한곳만 보도록 강제한 경우이다
- hard attention의 경우에 이미지 위치를 딱 하나만 정해야 하는데, 사실상 하나만 정하기 까다롭다
- 따라서 Hard attention을 학습시키려면 기본 backprob 보다는 조금 더 fanier한 방법을 써야한다
이미지 삽입 p87
- Attention Model을 학습시키고 나서 Caption을 생성해보면 실제로 모델이 Caption을 생성할 때 의미있는 부분에 attention을 집중한다는 것을 알 수 있다
- "A woman is throwing a frisbee in a park"에서 Attention mask를 살펴보면, 모델이 "원반(frisbee)" 라는 단어를 생성할 때 이미지에서도 실제 원반이 위치하는 곳을 정확하게 attention하는 것을 알 수 있다
- 모델에게 매 스텝 어디를 보라고 말해준 적이 없어도 모델 스스로가 Train time에 알아냈다
- 모델이 원반 영역에 집중하는 것이 올바른 일이라는 것을 스스로 알아낸 것이다
- 모델 전체가 미분가능하기 때문에 soft attention 또한 backprob이 가능하다. 따라서 이 모든 것들은 train time에서 나온 것들이다
이미지 삽입 p88
- RNN + Attention 조합은 Image captioning 뿐만 아니라 더 다양한 것들을 할 수 있다. 가령 Visual Question Answering(VQA) 같이 말이다
- 이 문제에서는 입력이 두 가지이다. 하나는 이미지이고 다른 하나는 이미지에 관련된 질문이다
- 왼쪽 이미지에 다음과 같은 질문을 할 수 있다. 'Q: 트럭에 그려져 있는 멸종위기 동물은 무엇입니까?'. 모델은 네개의 보기 중에서 정답을 맞춰야 한다
이미지 삽입 p89
- 이 모델 또한 RNN과 CNN으로 만들 수 있다. "many to one" 의 경우이다
- 모델은 자연어 문장(질문)을 입력으로 받아야 한다
- 이는 RNN을 통해 구현할 수 있다. RNN이 질문을 vector로 요약한다. 그리고 이미지 요약을 위해서는 CNN이 필요하다. CNN/RNN에서 나온 벡터를 조합하면 질문에 대한 분포를 예측할 수 있다
Multi-layer RNN
이미지 삽입 p90
- 3-Layer RNN이 있다고 했을 때 입력이 첫 번째 RNN으로 들어가서 첫 번째 hidden state를 만들어낸다
- RNN 하나를 돌리면 hidden states 스퀀스가 생긴다 (밑에서 두 번째 행)
- 이렇게 만들어진 hidden state 시퀀스를 다른 RNN의 입력으로 넣어줄 수 있다. 그러면 두 번째 RNN layer가 만들어내는 또 다른 hidden states 시퀀스가 생겨난다 (밑에서 세 번째)
- 이런 식으로 RNN layer를 쌓아올릴 수 있다
- 이렇게 하는 이유는 모델이 깊어질수록 다양한 문제들에서 성능이 더 좋아지기 때문이다
- 더 깊게 쌓는 방법은 RNN에서도 적용된다. 많은 경우에 3~4 layer RNN을 사용한다
- 하지만 보통은 엄청나게 깊은 RNN모델을 사용하지는 않는다. 일반적으로는 2,3,4 layer RNN이 적절하다
RNN의 문제점
이미지 삽입 p91
-
위 이미지처럼 일반적인(vanilla) RNN Cell이 있을 때 입력은 "현재 입력, x_t" 와 "이전 hidden state h_t-1"이다. 그리고 이 두 입력을 쌓는다 (Stack)
-
이렇게 두 입력을 쌓고 가중치 행렬 W와 행렬 곱 연산을 하고 tanh 를 씌워서 다음 hidden state(h_t)를 만든다
-
그러면 이 아키텍쳐는 backward pass에 그레디언트를 계산하는 과정에서 어떤 일이 발생할까?
이미지 삽입 p92
-
우선 Backward pass 시 h_t에 대한 loss의 미분값을 얻는다
-
그 다음 Loss에 대한 h_t-1의 미분값을 계산하게 된다
-
backward pass의 전체과정은 위 이미지의 빨간색 통로를 따르게 된다
-
우선 그레이언트가 tanh gate를 타고 흘러간다. 그 다음 "Mat mul gate" 를 통과한다
-
Mat mul gate의 backprop은 결국 이 transpose(가중치 행렬) 을 곱하게 된다. 이는 매번 vanilla RNN cells을 하나 통과할 때 마다 가중치 행렬의 일부를 곱하게 된다는 것을 의미한다
-
RNN의 특성 상 RNN이 여러 시퀀스의 Cell을 쌓아 올리기 때문에 h_0에 대한 그레이언트를 구하고자 한다면 결국에는 모든 RNN Cells을 거쳐야 한다
-
cell 하나를 통과할 때 마다 각 Cell의 행렬 W transpose factors가 관여한다
-
다시 말해 h_0 의 그레디언트를 계산하는 식을 써보면 아주 많은 가중치 행렬들이 개입하며, 이는 좋지 않다
-
우선 가중치를 행렬이라고 생각하지 말고 스칼라로 생각해보면, 이 값들을 계속해서 곱한다고 했을 때 수백 개의 스텝이 있는 경우라면 값들을 수백 번 곱해줘야 한다. 만약 곱해지는 값이 1보다 큰 경우라면 점점 값이 커질 것이고 1보다 작은 경우라면 점점 작아져서 0이 될 것이다. 이 두 상황이 일어나지 않으려면 곱해지는 값이 1인 경우밖에 없다
-
이 상황은 행렬에서도 동일하게 적용된다. 행렬의 특이값(singular value)이 엄청나게 큰 경우일 때 singular value가 엄청 큰 행렬을 계속 곱하는 경우에도 역시 h_0의 그레디언트는 아주 커지게 된다
-
이를 'exploding gradient problem'이라고 한다
- backprop시 레이어가 깊어질수록 그레디언트가 기하급수적으로 증가하는 현상이다
-
행렬의 특이값이 1보다 작은 경우라면 정 반대의 현상이 발생한다. 기하급수적으로 그레디언트가 작아진다
-
이를 'vanishing gradient problem' 이라고 한다
해결법
Gradient Clipping
- 그래디언트의 크기가 특정 임계값을 넘지 않도록 그래디언트를 제한함으로써 이 문제를 완화한다
- 그레디언트를 계산하고 그레디언트의 L2 norm이 임계값보다 큰 경우 그레디언트가 최대 임계값을 넘지 못하도록 조정해준다
- 그레디언트의 L2 norm이 임계값보다 큰 경우, 그래디언트를 임계값으로 나누어 그래디언트의 크기를 줄인다
- 그 결과, 그래디언트의 최대 크기가 임계값이 되므로, 가중치 업데이트가 불안정해지는 것을 막을 수 있다
- 이 방법은 그닥 좋은 방법은 아니지만, 실제로는 많은 사람들이 RNN 학습에 이 방법을 활용한다
- exploding gradient problem을 해결하기에는 비교적 유용한 방법이긴 하지만 vanishing gradient problem를 다루려면 조금더 복잡한 RNN 아키텍쳐가 필요하다
LSTM (Long Short-Term Memory)
- LSTM은 vanishing & exploding gradients 문제를 완화시키기 위해서 디자인되었다
- LSTM은 '셀 상태(cell state)'라는 개념과, 이 셀 상태를 조절하는 게이트 메커니즘을 도입하였다
이미지 삽입 p97
- vanilla RNN은 hidden state가 있고, 매 스텝 재귀적인 방법으로 hidden state를 업데이트했다
- LSTM에는 한 Cell 당 두 개의 Hidden state가 있다. 하나는 h_t인데 vanilla RNN에 있었던 hidden state(h_t)와 유사한 개념이다. 다른 하나는 "Cell state"인 c_t라는 두 번째 벡터이다
- Cell state, c_t 는 LSTM 내부에만 존재하며 밖에 노출되지 않는 변수이다
- LSTM의 Updata 식을 보면 LSTM도 두 개의 입력을 받는다 (h_t-1, x_t). 그리고 4개의 gates를 계산한다. i, f, o, g 이다
- 이 gates를 cell states, c_t를 업데이트하는데 이용한다. 그리고 c_t로 다음 스텝의 hidden state를 업데이트한다
LSTM의 구조
- Forget 게이트 : 셀 상태에 어떤 정보를 삭제할지를 결정
- 게이트 : 셀 상태에 어떤 새로운 정보를 추가할지를 결정
- Cell 상태 : 각 시퀀스의 상태를 기억하며, Forget 게이트와 Input 게이트를 통해 정보가 삭제되거나 추가된다
- Output 게이트 : 셀 상태를 기반으로 다음 뉴런으로달할 출력을 결정
LSTM의 동작
- 우선 LSTM에서는 이전 hidden state인 h_t와 현재의 입력인 x_t를 입력으로 받는다
- 이전 hidden state와 입력을 받아서 쌓아 놓는다. 그리고 네 개의 gates의 값을 계산하기 위한 커다한 가중치 행렬을 곱해준다
- 각 gates 출력은 hidden state의 크기와 동일하다
- gates 4개는 [i, f, o, g]인데, 기억하기 쉽게 "ifog" 라고 부르기도 한다
- I : input gate
- I는 Cell에서의 입력 x_t에 대한 가중치이다
- F : forget gate
- F는 이전 스텝의 Cell의 정보를 얼마가 망각(forget) 할지에 대한 가중치 이다
- O : output gate
- O는 Cell state, c_t를 얼마나 밖에 드러내 보일지에 대한 가중치이다
- G : gate gate
- G는 input cell을 얼마나 포함시킬지 결정하는 가중치이다
- 각 gate에서 사용하는 non-linearity가 각양각색 이다
- input/forget/output gate의 경우는 sigmoid를 사용한다
- gate의 값이 0~1 사이라는 의미이다
- gate gate는 tanh를 사용한다
- 따라서 gate gate는 -1 ~ +1 의 값을 갖는다
- input/forget/output gate의 경우는 sigmoid를 사용한다
이미지 삽입 p99
- f * c_t-1
- f * c_t-1는 0또는 1이 된다
- 따라서 forget gate = 0인 element는 이전 cell state를 잊는다
- 반면 forget gate = 1이면 cell state의 element를 계속 기억한다
- 즉, forget gate는 이전 cell state의 gate on/off 를 결정한다
- i * g
- 벡터 i의 경우 시그모이드에서 나왔으므로 0 또는 1이다
- cell state의 각 element에 대해서, 이 cell state를 사용하고 싶으면 1 이 된다
- 반면 쓰고싶지 않으면 i = 0 이 된다
- gate gate는 tanh 출력이기 때문에 값이 -1 또는 +1 이다
- c_t는 현재 스텝에서 사용될 수 있는 "후보" 라고 할 수 있다
- c_t는 두 개의 독립적인 scaler 값(f, i)에 의해 조정된다
- 각 값(f, i)은 1까지 증가하거나 감소한다
- 수식을 해석해보자면, 우선 이전 cell state(c_t-1)을 계속 기억할지 말지를 결정한다 (f * c_t-1)
- 그런다음 각 스텝마다 1까지 cell state의 각 요소를 증가시키거나 감소시킬 수 있다 (i * g)
- 즉 cell state의 각 요소는 scaler integer counters 처럼 값이 줄었다 늘었다 하는 것으로 볼 수 있다
- h_t는 실제 밖으로 보여지는 값이다
- 그렇게 때문에 cell state는 counters의 개념으로 해석할 수 있다
- 각 스텝마다 최대 1 또는 -1씩 세는 것이다
- 이 값은 tanh를 통과한다. 그리고 최종적으로 output gate와 곱해진다
- output gate 또한 sigmoid에서 나온 값이다. 따라서 0~1의 값을 가진다
- output gate는 각 스텝에서 다음 hidden sate를 계산할 때 cell state를 얼마나 노출시킬지를 결정한다
LSTM의 backward pass
이미지 삽입 p100
- upsteam gradient를 살펴보면, 우선 "addition operation"의 backprob이 있다
- "addition" 에서는 upstream gradient가 그저 두 갈래로 복사된다
- 따라서 "element wise multply" 로 직접 전달된다
- 그레디언트는 upsteam gradient와 forget gate의 element wise 곱이 된다
- 결국 Cell state의 backprob은 그저 upstream gradient * forget gate이다
- 이 특성은 vanilla RNN에 비해 좋은점이 몇 가지가 있다
- 우선 forget gate와 곱해지는 연산이 matrix multiplication가 아닌 element-wise라는 점이다
- full matrix multiplication 보다는 element wise multiplication이 더 낫다
- 두 번째는 element wise multiplication을 통해 매 스텝 다른 값의 forget gate와 곱해질 수 있다는 점이다
- LSTM에서는 forget gate가 스텝마다 계속 변한다
- 따라서 LSTM은 exploding/vanishing gradient 문제를 더 쉽게 해결할 수 있다
- forget gate는 0~1 사이의 값이다. 따라서 forget gate를 반복적으로 곱한다고 했을 때 더 좋은 수치적 특성을 보일 수 있다
- 세 번째는 그래디언트가 tanh를 한 번만 거친다는 점이다
- vanilla RNN의 backward pass에서는 매 스탭 그래디언트가 tanh를 거쳐야 했다
- LSTM에서도 hidden state h_t를 출력 y_t를 계산하는 데 사용하는데 RNN처럼 매 스탭마다 tanh를 거치는 것이 아니라 tamh를 단 한 번만 거치면 된다
- 우선 forget gate와 곱해지는 연산이 matrix multiplication가 아닌 element-wise라는 점이다
- LSTM을 유심히 들여다보면 RsetNet과 유사하게 생겼다. ResNet의 Backward pass에서 identity connection이 아주 유용했는데 Identity Mapping이 ResNet 그레디언트를 위한 고속도로 역할을 했다
- LSTM도 동일하다. LSTM의 Cell state의 element-wise mult가 그레디언트를 위한 고속도로 역할을 한다
출처 및 참조
