LeNet-5
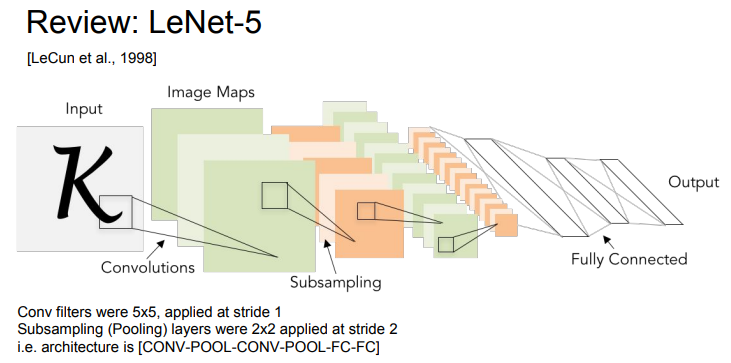
- LeNet은 산업에 아주 성공적으로 적용된 최초의 ConvNet이다
- LeNet은 이미지를 입력으로 받아서 stride = 1 인 5 x 5 필터를 거치고 몇 개의 Conv Layer와 pooling layer를 거친다. 그리고 끝 단에 FC Layer가 붙는다
- 엄청 간단한 모델이지만 숫자 인식에서 엄청난 성능을 보여줬다
- 우편 번호나 은행 수표의 숫자 인식 등에 활용되었다
AlexNet
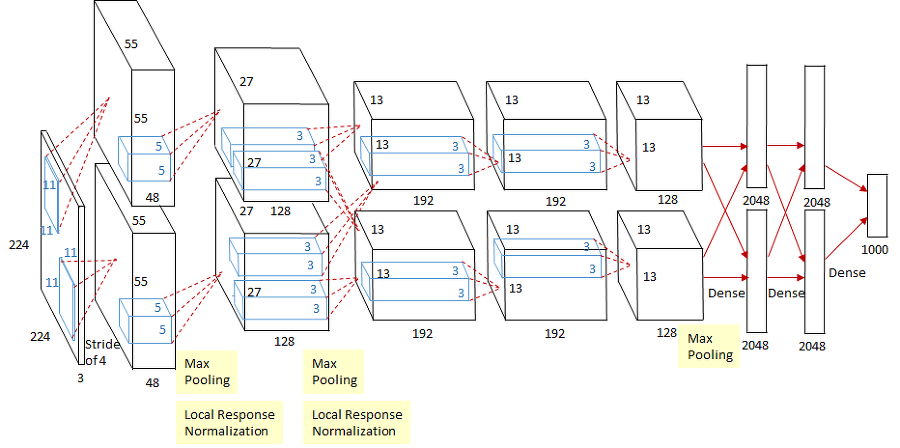
- 최초의 Large scale CNN이다
- 기본적으로 conv - pool - normalization 구조가 두 번 반복된다. 그리고 conv layer가 조금 더 붙고, 그 뒤에 pooling layer가 있다. 마지막에는 FC-layer가 몇 개 붙는다
- 생긴 것만 봐서는 기존의 LeNet과 레이어만 더 많아지고 상당히 유사하다
- AlexNet는 5개의 Conv Layer와 2개의 FC-Layer로 구성된다
- 대체로 다른 Conv Net의 다이어그램과 유사하긴 하지만 한 가지 차이점이 있다. 그것은 바로 모델이 두개로 나눠져서 서로 교차하는 것이다
- AlexNet을 학습할 당시에 GTX850 으로 학습시켰다. 이 GPU는 메모리가 3GB 뿐이다
- 전체 레이어를 GPU에 다 넣을 수 없었기에 네트워크를 GPU에 분산시켜서 넣었다
- AlexNet은 최초의 CNN기반 우승 모델이고 수년 전까지 대부분의 CNN 아키텍쳐의 베이스모델로 사용되어 온다
특징
- ReLU 활성화 함수 사용
- ReLU는 계산 효율성이 뛰어나고, 그래디언트 소실 문제를 완화하는 데 도움이 되었다
- data augumentation을 많이 수행했다
- lipping, jittering, color norm 등을 적용하였다
- 데이터를 증가시키는 역할을 한다
- Dropout 사용
- 파라미터 값은 0.5이다
- 과적합을 방지한다
- 학습 시 Batch size는 128이다
- SGD momentum 사용
- SGD momentum 값은 0.9이다
- 초기 학습률은 1e-2이다
- val accuracy가 올라가지 않는 지점에서는 학습이 종료되는 시점까지 Learning rate를 1e-10까지 줄인다
- weight decay 사용
- 학습 과정에서 모델의 가중치가 너무 커지는 것을 제한하여, 모델의 복잡도를 제어한다
- 이는 손실 함수에 가중치의 제곱 항을 추가함으로써 이루어진다
- 모델 앙상블로 성능을 향상시켰다. 그리고 여러개의 모델을 앙상블시켜서 성능을 개선했다
- LRU (Local Response Normalization) 적용
- ReLU 활성화 함수 뒤에 Local Response Normalization(LRN)을 적용하였다
- 이는 ReLU의 활성화 값을 정규화하여 학습을 안정화시키는 데 도움이 되었다
ZFNet
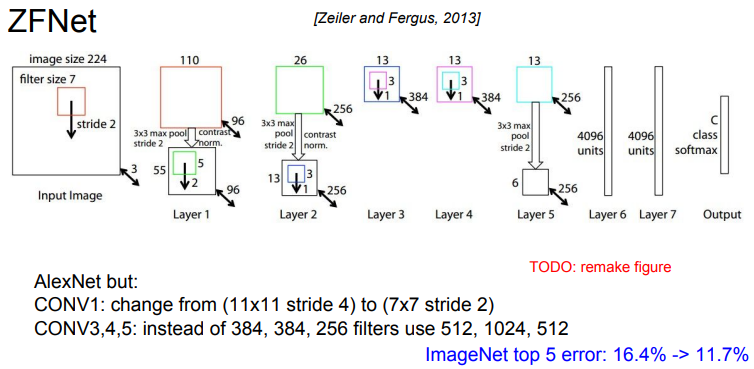
- ZFNet은 대부분 AlexNet의 하이퍼파라미터를 개선한 모델이다
- AlexNet과 같은 레이어 수이고 기본적인 구조도 같다
- 다만 stride size, 필터 수 같은 하이퍼파라미터를 조절해서 AlexNet의 Error rate를 좀 더 개선시켰다
특징
- 첫 번째 컨볼루션 레이어의 필터 크기 조정
- AlexNet에서는 첫 번째 컨볼루션 레이어의 필터 크기가 11x11였지만, ZFNet에서는 이를 7x7로 줄였다
- 이는 이미지의 세부적인 정보를 더 잘 잡아낼 수 있게 한다
- 두 번째 컨볼루션 레이어의 필터 수 조정
- ZFNet은 두 번째 컨볼루션 레이어의 필터 수를 AlexNet의 256개에서 384개로 늘렸다
- 이는 모델이 더 복잡한 패턴을 학습할 수 있게한다
VGGNet
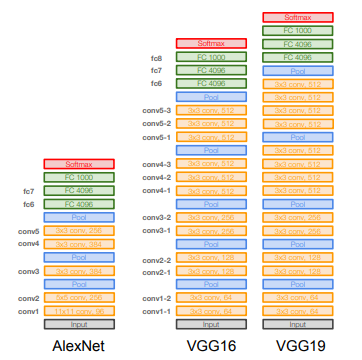
- VGGNet의 특징은 우선 훨씬 더 깊어졌고 그리고 더 작은 필터를 사용한다는 것이다
- AlexNet에서는 8개의 레이어였지만 VGGNet은 16 ~ 19개의 레이어를 가진다
- VGGNet은 아주 작은 필터만 사용한다. 항상 3 x 3 필터만 사용하는데 이는 이웃픽셀을 포함할 수 있는 가장 작은 필터이다
- 이렇게 작은 필터를 유지해 주고 주기적으로 Pooling을 수행하면서 전체 네트워크를 구성하게 된다
- AlexNet과 유사하지만 Local Response Normalization은 사용하지 않는다. 도움이 크게 안되기 때문이다
- VGG16과 VGG19은 아주 유사하다. 다만 VGG19가 조금 더 깊기 때문에 VGG19가 아주 조금 더 좋다. 깊어진만큼 메모리도 조금 더 사용한다
- AlexNet에서 처럼 모델 성능을 위해서 앙상블 기법을 사용했다
- VGG의 마지막 FC-Layer인 FC7은 이미지넷 1000 class의 바로 직전에 위치한 레이어이다.
- 이 FC7은 4096 사이즈의 레이어인데 아주 좋은 feature represetation을 가지고 있는 것으로 알려져 있다
- 다른 데이터에서도 특징(feature) 추출이 잘되며 다른 Task에서도 일반화 능력이 뛰어난 것으로 알려져 있다
GoogLeNet
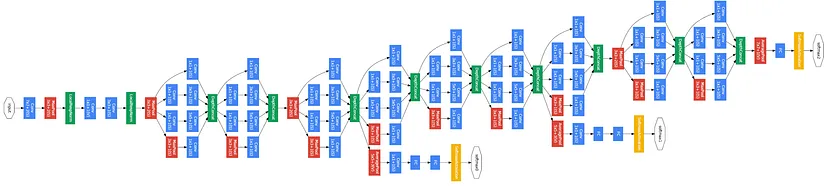
- 22개의 레이어를 가지고 있다
- GoogLeNet에서 가장 중요한 것은 효율적인 계산에 관한 그들의 특별한 관점이 있다는 것과 높은 계산량을 아주 효율적으로 수행하도록 네트워크를 디자인했다는 점이다
- GoogLeNet은 Inception module을 사용한다. Inception module을 여러개 쌓아서 만든다
- GoogLeNet에는 파라미터를 줄이기 위해서 FC-Layer를 없앴다
- 전체 파라미터 수가 5M 정도이다. 그럼에도 불구하고 훨씬 더 깊다
- GoogLeNet에서는 계산량이 많은 FC-layer를 대부분 걷어냈고 파라미터가 줄어들어도 모델이 잘 동작함을 확인했다
- AlexNet보다 12배 작은 파라미터를 가지고 있다
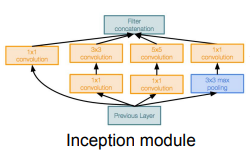
Inception Module
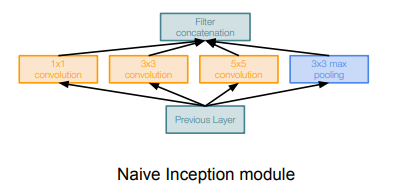
- 당시 개발자들은 "a good local network typology"를 디자인하고 싶었다. "network within a network" 라는 개념으로 local topology를 구현했고 이를 쌓아올렸다. 이 Local Network를 Inception Module이라고 한다
- Inception Module 내부에는 동일한 입력을 받는 서로 다른 다양한 필터들이 "병렬로" 존재한다
- 이전 레이어의 입력을 받아서 다양한 Conv 연산을 수행한다
- 1x1 / 3x3 / 5x5 conv에 Pooling도 있다
- 각 레이어에서 각각의 출력 값들이 나오는데 그 출력들을 모두 Depth 방향으로 합친다. 그렇게 합치면 하나의 tensor로 출력이 결정되고 이 하나의 출력을 다음 레이어로 전달한다
- 네트워크가 깊기 때문에 보조 분류기(auxiliary classifier)를 달아준다. 보조분류기를 중간 레이어에 달아주면 추가적엔 그레디언트를 얻을 수 있고 중간 레이어의 학습을 도울 수 있다
구성요소
- 1x1 합성곱 연산
- 이 연산은 각 픽셀 위치에서 채널 간의 정보를 혼합하는 역할을 한다
- 이를 통해 네트워크가 채널 간의 상관 관계를 학습할 수 있다
- 또한, 1x1 합성곱 연산은 중간 단계에서 채널 수를 줄여 연산량을 감소시키는 역할한다
- 3x3과 5x5 합성곱 연산
- 이 연산들은 이미지의 다양한 스케일의 정보를 추출한다
- 작은 필터는 세밀한 정보를, 큰 필터는 넓은 범위의 정보를 학습할 수 있다
- 3x3 최대 풀링 연산
- 이 연산은 이미지의 공간적인 정보를 압축하고, 견고한 특징을 추출한다
문제점
- 연산량이 아주 많다
- Pooling layer 또한 문제를 악화시킨다. 왜냐하면 입력의 Depth를 그대로 유지하기 때문이다. 그래서 레이어를 거칠때마다 Depth가 점점 늘어만 간다
- Pooling의 출력은 이미 입력의 Depth와 동일하고 여기에 다른 레이어의 출력이 계속해서 더해지게 된다
해결
- "bottleneck layer"를 이용한다.
- Conv 연산을 수행하기에 앞서 입력을 더 낮은 차원으로 보낸다
- 주요 아이디어는 바로 입력의 depth를 줄이는 것이다
- 각 레이어의 계산량은 1x1 conv를 통해 줄어든다
- 1x1 conv는 각 spatial location에서만 내적을 수행하면서 depth를 줄일 수 있다(입려의 depth를 더 낮은 찾원으로 projection)
- 3x3/5x5 conv 이전에 1x2이 추가된다. 그리고 polling layer 후에도 1x1 conv가 추가된다. 1x1 conv가 bottleneck layers의 역할로 추가된다
ResNet
- ResNet 아키텍쳐는 152 레이어로 엄청나게 더 깊어졌다
- ResNet은 Residual Connection 라는 방법을 사용한다
- Residual Connection은 입력 데이터를 네트워크의 여러 계층을 건너뛰어 출력에 바로 더하는 구조를 말한다
- 이를 통해 네트워크는 입력 데이터의 '잔차'(Residual)를 학습하게 된다
- 이 구조는 네트워크가 깊어질수록 발생하는 그래디언트 소실 문제와 과적합 문제를 완화하는 데 큰 도움이 된다
- ImageNet 데이터를 분류하기 위해 ResNet은 152개의 레이어를 가지고 있다
- 기본적으로 ResNet은 residual block들을 쌓아 올리는 구조이다
- 하나의 Residual blocks는 두 개의 3x3 conv layers로 이루어져 있다. 이렇게 구성해야 잘 동작하는 것으로 알려져 있다
- 주기적으로 필터를 두배 씩 늘리고 stride 2를 이용하여 Downsampling을 수행한다
- 네트워크의 초반에는 Conv Layer가 추가적으로 붙고 네트워크의 끝에는 FC-Layer가 없다. 대신 Global Average Pooling Layer를 사용한다
- GAP는 하나의 Map 전체를 Average Pooling 한다
- 마지막에는 1000 개의 클래스분류를 위한 노드가 붙는다
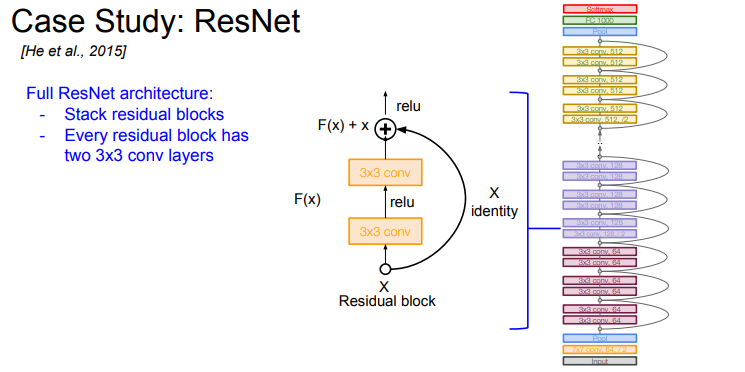
- ResNet 모델의 Depth는 34, 50, 100 까지 늘어난다
- ResNet의 경우 모델 Depth가 50 이상일 때 Bottleneck Layers를 도입한다. 이는 GoogLeNet에서 사용한 방법과 유사하다
- Bottleneck Layer는 1x1 conv를 도입하여 초기 필터의 depth를 줄여준다. 그리고 뒤에 다시 1x1 conv를 추가해서 Depth를 다시 256으로 늘린다
- ResNet은 모든 Conv Layer 다음 Batch Norm을 사용한다. 그리고 초기화는 Xavier를 사용하는데 추가적인 scaling factor를 추가한다 (2로 나눔)
- 이 방법은 SGD + Momentum에서 좋은 초기화 성능을 보인다
- learning rate는 learning rate 스케줄링을 통해서 validation error가 줄어들지 않는 시점에서 조금씩 줄여준다
- Minibatch 사이즈는 256이고 weight dacay도 적용한다. Dropout은 사용하지 않는다
- 네트워크가 깊어질수록 Training Error는 더 줄어든다

문제점
- 모델이 깊어짐에 따라 학습이 잘 되지 않는다
- 개발자들은 overfitting 문제가 아닌 Optimization에 문제가 생긴다는 것을 추측해 낸다
해결책
- 개발자들은 "모델이 더 깊다면 적어도 더 얕은 모델만큼은 성능이 나와야 하지 않은지"라고 추론했다
- 해결책은 다음과 같다. 우선 더 얕은 모델의 가중치를 깊은 모델의 일부 레이어에 복사한다
- 그리고 나머지 레이어는 identity mapping을 한다 (input을 output으로 그냥 내보냄)
- identitiy mapping : 입력을 그대로 출력으로 반환하는 함수나 매핑
- 이렇게 구성하면 Deeper Model의 학습이 제대로 안되더라도 적어도 Shallow Model 만큼의 성능은 보장된다
적용
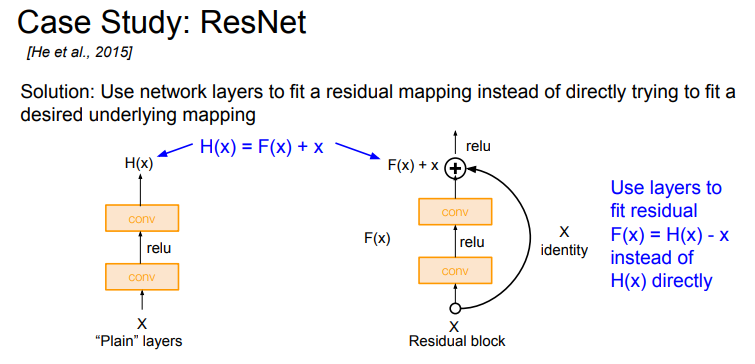
- 위 해결책을 모델에 적용하려면 어떻게 모델 아키텍처를 디자인해야 할지 고민했다
- 그들의 아이디어는 레이어를 단순하게 쌓지 않는 것이다
- Direct mapping 대신에 Residual mapping을 하도록 블럭을 쌓는 것이다
- 레이어가 직접 "H(x)"를 학습하기 보다 이런 식으로 "H(x) - x" 를 학습할 수 있도록 만들어 준다
- 이를 위해서 Skip Connection을 도입하게 된다
- Skip Connection은 가중치가 없으며 입력을 identity mapping으로 그대로 출력단으로 내보낸다
- 그러면 실제 레이어는 변화량(delta) 만 학습하면 된다. 입력 X에 대한 잔차(residual) 이라고 할 수 있다
- 최종 출력 값은 "input X + 변화량(Residual)" 이다
- 이 방법을 사용하면 학습이 더 쉬워진다. 가령 Input = output 이어야 하는 상황이라면 레이어의 출력인 F(x)가 0 이어야 하므로(residual = 0) 모든 가중치를 0으로 만들어주면 그만이다. 손쉽게 출력을 Identity로 만들어 줄 수 있는 것이다
- 이 방법을 사용하면 앞서 제시한 방법을 손쉽게 구성할 수 있다. 네트워크는 Residual만 학습하면 그만이다. 출력 값도 결국엔 입력 입력 X에 가까운 값이다. 다만 X를 조금 수정한 값이다. 레이어가 Full mapping을 학습하기 보다 이런 조금의 변화만 학습하는 것이다
Skip Connection
- 특정 레이어의 입력을 그 레이어의 출력에 바로 더하는 방식으로 동작한다
- 이러한 방식은 네트워크가 깊어질수록 발생하는 문제, 예를 들면 Vanishing Gradient 문제를 완화하는 데 도움을 준다
- 네트워크가 깊어질수록, 기울기는 점차 작아져서 오차 역전파 시에 각 레이어를 통과하면서 계속해서 소멸되는 현상이 발생하는데, 이를 Vanishing Gradient 문제라고 한다
- Skip Connection은 이 문제를 해결하기 위해 도입된 개념으로, 이를 통해 입력 신호가 깊은 레이어로 직접 전달되어 그래디언트가 쉽게 전파될 수 있도록 돕는다
Comparing complexity
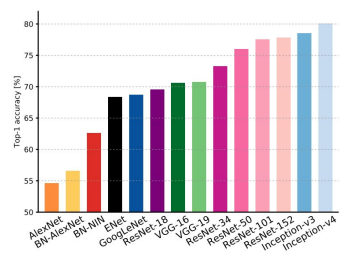
- Top-1 Accuracy가 기준이고 높을수록 좋은 모델이다
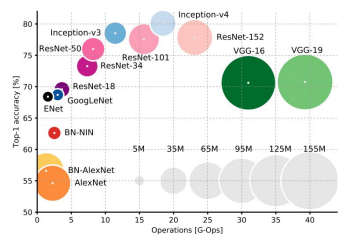
- Y축은 top-1 Accuracy이고 높을수록 좋다
- X축은 연산량을 나타낸다. 오른쪽으로 갈수록 연산량이 많다
- 원의 크기는 메모리 사용량이다. 원이 클수록 덩치가 큰 모델이다
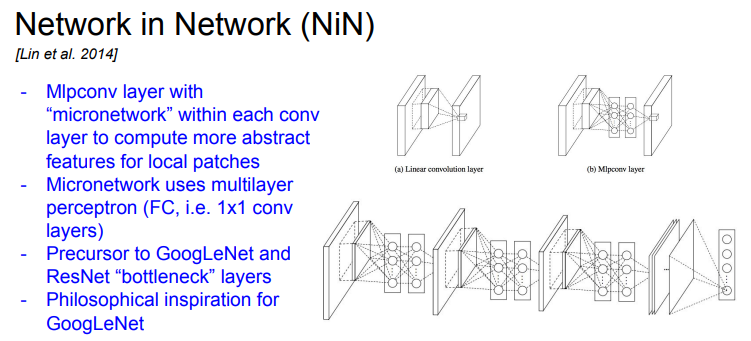
Network in Network (NiN)
- Network in Network의 기본 아이디어는 MLP conv layer이다. 네트워크 안에 작은 네트워크를 삽입하는 것이다
- 컨볼루션 레이어와 풀링 레이어 사이에 1x1 크기의 컨볼루션 레이어를 추가하여, 복잡한 추상화를 가능하게 하는 것이 특징이다
- 각 Conv layer 안에 MLP(Multi-Layer Perceptron)를 쌓는다. FC-Layer 몇 개를 쌓는 것이다
- 맨 처음에는 기존의 Conv Layer가 있고 FC-Layer를 통해 abstract features를 잘 뽑을수 있도록 한다
- 단순히 conv filter만 사용하지 말고, 조금 더 복잡한 계층을 만들어서 activation map을 얻어보자는 아이디어이다
- NIN에서는 기본적으로는 FC-Layer를 사용한다. 이를 1x1 conv layer 라고도 한다
- 전통적인 CNN은 컨볼루션 레이어에서 공간적 정보를, 완전 연결 레이어에서 추상적 정보를 학습하는 반면, NiN은 1x1 컨볼루션 레이어를 이용하여 컨볼루션 레이어에서도 추상적 정보를 학습한다
- 이를 통해 공간적 정보와 추상적 정보를 동시에 학습하면서 효과적인 특징 추출이 가능하다
- NiN은 마지막에 완전 연결 레이어 대신에 글로벌 평균 풀링 레이어를 사용하여 과적합을 방지하는 것이 특징이다
- Network in Network는 GoogLeNet과 ResNet보다 먼저 Bottleneck 개념을 정립했기 때문에 아주 의미있는 아이디어이다
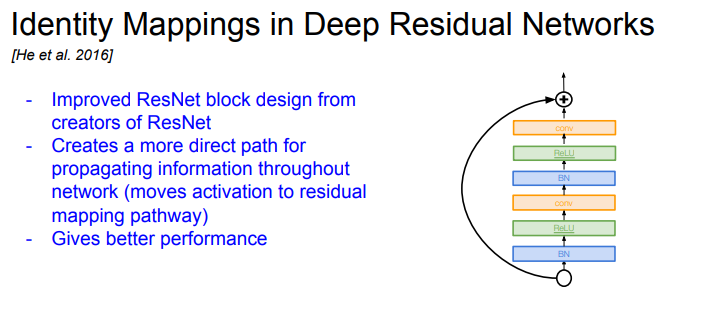
Idetity Mapping in Deep Residual Networks
- ResNet block path를 조절하였다
- 새로운 구조는 direct path를 늘려서 정보들이 앞으로 더욱 더 잘 전달되고 Backprob도 더 잘 될 수 있게 개선했다
Wide Residual Networks
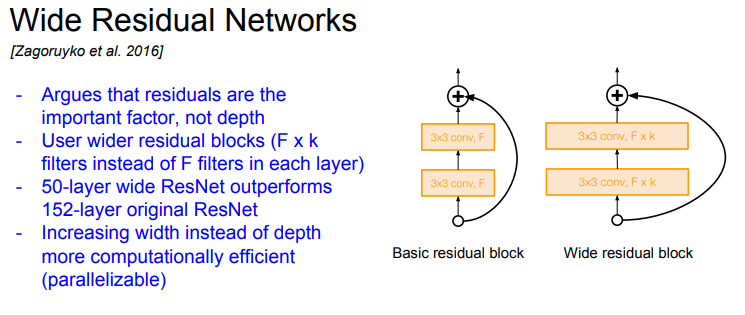
- Residual Connection이 있다면 네트워크가 굳이 더 깊어질 필요가 없다고 주장했다
- residual block 을 더 넓게 만들었다. 즉 conv layer의 필터를 더 많이 추가했다
- 가령 기존의 ResNet에는 Block 당 F개의 filter만 있었다면 대신에 F * K 개의 필터로 구성했다
- 각 레이어를 넓게 구성했더니 50 레이어만 있어도 152 레이어의 기존 ResNet보다 성능이 좋다는 것을 입증했다
- 그리고 네트워크의 Depth 대신에 filter의 Width를 늘리면 추가적인 이점이 있는데, 계산 효율이 증가한다. 왜냐하면 병렬화가 더 잘되기 때문이다. 네트워크의 Depth를 늘리는 것은 sequential한 증가이기 때문에 conv의 필터를 늘리는(width) 편이 더 효율적이다
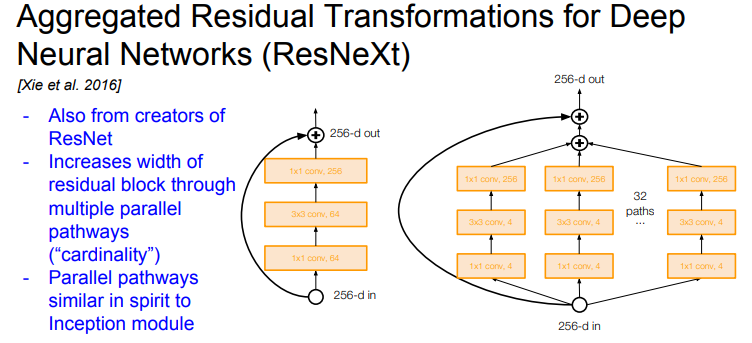
ResNeXt
- 여기에서도 계속 residual block의 width를 파고든다. filter의 수를 늘리는 것이다
- 각 Residual block 내에 "다중 병렬 경로" 추가한다. 이들은 pathways의 총 합을 cardinality라고 불렀다
- 하나의 bottleneck ResNet block은 비교적 작지만 이런 thinner blocks을 병렬로 여러개 묶었다
- 여러 Layers를 병렬로 묶어준다는 점에서 Inception Module과도 연관있다. ResNeXt 라는 이름 자체가 이를 내포하고 있다 (ResNet + inEXeption)
Stochastic Depth
- 네트워크가 깊어지면 깊어질수록 Vanishing gradient 문제가 발생한다. 깊은 네트워크에서는 그레디언트를 뒤로 전달할수록 점점 그레디언트가 작아지는 문제가 있다
- 기본 아이디어는 Train time에 레이어의 일부를 제거한다. short network면 트레이닝이 더 잘 될 수 있기 때문이다
- 일부 네트워크를 골라서 identity connection으로 만들어버린다
- 이렇게 shorter network를 만들어서 Train하면 그레디언트가 더 잘 전달될 수 있다
- Dropout과 유사하다
- Test time에서는 full deep network를 사용한다

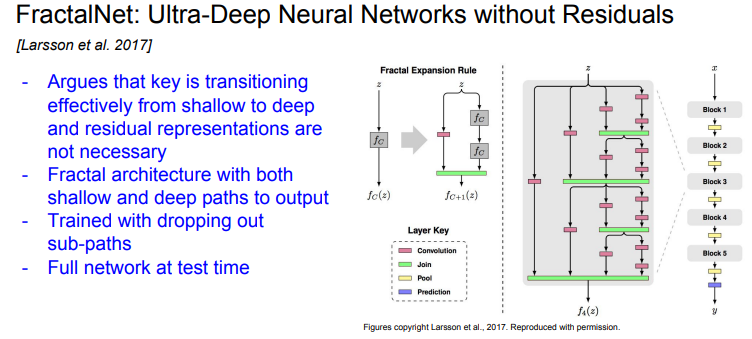
FractalNet
- residual connection이 쓸모없다고 주장한다
- FractalNet 아키텍쳐에서는 residual connection이 전혀 없다
- 그들은 shallow/deep network의 정보 모두를 잘 전달하는 것이 중요하다고 생각했다
- 그래서 FractalNet은는 아래 그림에서 보이는 바와 같이 fractal한 모습이다
- FractalNet에서는 shllow/deep 경로를 출력에 모두 연결한다
- FractalNet에는 다양한 경로가 존재하지만 Train time에는 Dropout처럼 일부 경로만을 이용해서 Train 한다. 그리고 Test time에는 full network를 사용한다
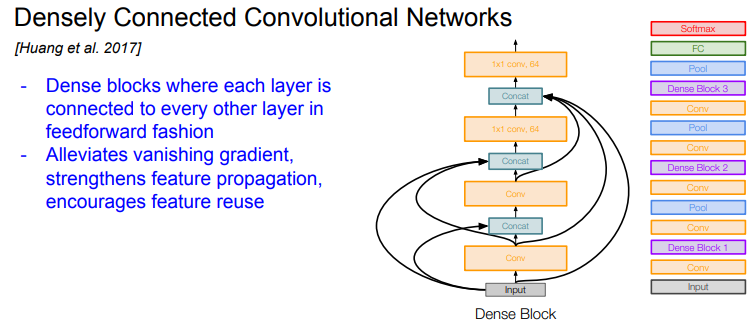
DenseNet (DENSEly Connected Convolutional NETworks)
- DenseNet에는 Dense Block 이란 것이 있다. 한 레이어가 그 레이어 하위의 모든 레이어와 연결되어 있다
- Network의 입력이미지가 모든 Layer의 입력으로 들어간다. 그리고 모든 레이어의 출력이 각 레이어의 출력과 Concat 된다. 이 값이 각 Conv layer의 입력으로 들어간다. 이 과정에서 dimention을 줄여주는 과정이 포함된다
- 이들은 Dense Connection이 Vanishing gradient 문제를 완화시킬 수 있다고 주장한다
- Dense connection은 Feature를 더 잘 전달하고 더 잘 사용할 수 있게 해준다. 각 레이어의 출력이 다른 레이어에서도 여러번 사용될 수 있기 때문이다
SqueezeNet
- 아주 효율적인 네트워크이다
- fire modules 이라는 것을 도입했다. fire modules 의 "squeeze layer"는 1x1 필터들로 구성되고, 이 출력 값이 1x1/3x3 필터들로 구성되는 "expand layer"의 입력이 된다
- SqueezeNet는 ImageNet에서 AlexNet 만큼의 Accuracy를 보이지만 파라미터는 50배 더 적었다
- 그리고 SqueezeNet을 더 압축하면 AlexNet보다 500배 더 작아지게 된다
- SqueezeNet의 용량은 0.5Mb 밖에 안 된다

출처 및 참조

공부 기록