
오늘은 워드 임배딩의 대표적인 모델인 GloVe에 대해서 알아보고,
이미 학습된 GloVe를 이용하여 임배딩을 생성하는 코드에 대해 알아보고자 한다
1. Vector Representation
- 모델을 보기 앞서 먼저
벡터 표현이란?- 연속 또는 범주형 데이터로 변환하여 데이터를 숫자 또는 일련의 벡터로 나타내는 것을 의미
- 전통적으로 one-hot encoding, label encoding, BoW, tf-idf 등 방법이 사용되었지만 최근에는 벡터 공간을 사용한 Dense Embedding으로 표현하는 모델이 많이 사용됨
- Dense Representation은 의미적으로 유사한 단어들을 실제 벡터 공간에서 가까운 위치에 매핑됨으로써 일련의 벡터로 의미 유사성을 발견할 수 있는 장점이 있다.
2. GloVe
- Global Vectors for word representation
- 단어를 벡터 형태로 표현하는 워드 임베딩 모델로, 2014년 스탠포드 대학에서 개발된 모델
- 단어의 의미, 구문 관계를 효과적으로 파악하기 위해 전역(Global)적인 단어 동시 발생(co-occurrence)를 기반으로 한다.
- Word2Vec, ELMo, Fasttext와 더불어 GloVe는 지금도 많이 쓰이는 모델 중 하나
- 또한 Static Embedding의 대표적인 모델 중 하나
3. GloVe Mechanism
-
GloVe는 전역에서의 단어 동시 발생 수치와, 문맥 정보를 모두 고려하여 단어 임베딩을 생성한다.
-
co-occurrence matrix생성- co-occurrence matrix란, 코퍼스 내에서 각 단어 간 동시 발생 빈도를 기반으로 생성한 행렬이다
- 문장 1: I can play soccer
문장 2: I can play gameI can play soccer game I 0 2 2 1 1 can 2 0 2 1 1 play 2 2 0 1 1 soccer 1 1 1 0 0 game 1 1 1 0 0 - 동시 발생 빈도의 기준은
window라는 일정 간격 부여하여 단어 동시 발생 행렬을 생성한다. (window = 2 → 중심 단어 전후로 2개 단어 씩 고려)
-
co-occurrence ratio 사용
-
또한, 단어의 의미 관계를 파악하기 위해, 동시 발생 비율을 사용
-
여기서 동시 발생 비율이란, P_ik / P_jk를 의미
-
즉, 서로 관련이 있는 단어라면 동시에 등장할 비율이 더 높게 나올 것이고, 이를 나타내기 위해 동시 등장 비율을 사용(
= 상대적 중요성 확인)
-
-
co-occurrence matrix와 co-occurrence ratio사용
-
위에서 구한 두 정보를 사용한 목적함수를 구성하여 표현을 생성
-
목적함수
- - X_ij 동시 발생 행렬 값 W_i.T * W_j - 중심 단어 i의 벡터와 주변 단어 j의 벡터 간 inner product 결과,
두 벡터 간 유사성을 측정b_i, b_j bias(편향) f(X_ij) 가중치 역할의 함수
(동시 발생 횟수가 너무 많거나 너무 작은 경우에 영향을 줄이는 역할)
중심 단어 벡터 W_i와 주변 단어 벡터W_j는 초기에 난수로 초기화 되었다가 훈련 과정으로 통해 업데이트 된다.
즉, 모든 단어가 중심 단어이면서 주변 단어이기 때문에 모든 단어는 2개의 임배딩으로 표현되어 있는 상태다.
따라서, 이 두 벡터를 더하거나 평균 등 후처리를 통해 최종 단어의 임배딩을 생성한다.
-
4. GloVe 사용 코드
- 사전에 학습된 GloVe 모델 사용
# 필요한 라이브러리 임포트
import os
import zipfile
import urllib.request
import numpy as np
# GloVe 모델 다운로드
glove_file_path = "glove,twitter.27B.100d.txt"
if not os.path.exists(glove_filt_path):
print('Glove 임배딩 모델 다운로드 중...')
zip_path = "glove.twitter.27B.zip"
if not os.path.exists(zip_path):
urllib.request.urlretrieve("GloVe 모델 다운로드 경로", zip_path)
print("임배딩 추출 중...")
with zipfile.Zipfile(zip_path, 'r') as zip_ref:
zip_ref.extract("glove.twitter.27B.100d.txt")
print("모델 다운로드, 추출 완료")
def load_glove_embeddings(glove_file_path):
embedding_idx = []
with open(glove_file_path, 'r', encoding = 'utf-8') as f:
for line in f:
values = line.split()
word = values[0] # 단어 추출
vector = np.array(values[1:], dtype = np.float32)
embedding_idx[word] = vector
return embedding_idx
def create_embedding_matrix(bow_list, embedding_idx, embedding_dim):
vocab_size = len(bow_list)
embedding_matrix = np.zeros((vocab_size, embedding_dim), dtype=np.float32)
for i, word in enumerate(bow_list):
if word in embedding_idx:
embedding_matrix[i] = embedding_idx[word]
else:
embedding_matrix[i] = np.random.normal(scale = 0.6, size = (embedding_dim))
return embedding_matrix
-
코드 설명
-
모델 다운로드 과정에서는 해당 디렉토리에 괄호 안 path의 파일(file_name) 또는 디렉토리(dir_name)이 존재하는 지 확인한다.
os.path.exists(file_name) → True - > 파일 존재
즉, 해당 코드에서는 일치하는 파밀명이 없을 경우 다운로드 진행
-
load_glove_embedding 메서드는 지정된 경로에 있는 파일을 ‘읽기 모드’로 열고, UTF-8 인코딩을 사용하는 구문을 사용한다. (with 구문 이외 코드는 단순 분리, 저장하는 코드)
-
UTF-8
- UTF-8은, 유니코드(unicode)를 표현하는 가장 흔히 사용하는 문자 인코딩 방식 (유니코드는 단순히 말해 세계 여러 언어를 하나의 체계에서 정의한 표준이라고 할 수 있다.)
- 인코딩이란?
- 컴퓨터는 모든 데이터를 0 또는 1로 저장하는데, 문자를 저장하기 위해서는 숫자로 변환하는 방식이 필요하고, 이를 ‘문자 인코딩’이라고 함
- 대부분의 파일을 저장 또는 읽을 때, encoding 방법은 utf-8을 사용하는 게 무난함
-
create_embedding_matrix 메서드를 사용하여 단어 임배딩 행렬을 np.zeors로 초기화 한 후, embedding_idx.에 있는 단어(row)는 이미 추출된 임배딩으로 다시 저장하고, 만약 추출한 임배딩에 bow_list에 없는 단어(= Out of vocabulary, OOV)라면 정규분포(normal)을 따르는 난수로 초기화 한다.(np.random.normal)
-
ex) 만약, bow_list에 4개 단어가 들어 있다면 아래와 같은 결과를 얻을 수 있다.
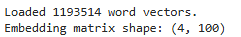
학습된 단어 개수, 사용한 데이터셋 등 여러 버전을 다운로드 받을 수 있으니 목적에 따라 적절하게 선택하면 된다!
정리
-
GloVe는 정적 임베딩 모델로, 지금도 baseline 모델 또는 토픽을 벡터로 바꾸는 모델로서 자주 사용된다.
-
정적 임베딩(static embedding)이란, 한 가지 단어에 대해 고정된 벡터를 갖는 것을 의미 -
정적 임베딩 모델의 경우 동음이의어에서 문제가 발생
- 왜냐면 학습 방향에 따라 한 가지 의미만 내포할 수 있기 때문에 bank와 같이 은행 또는 강둑이라는 여러 의미를 담고 있는 단어라면 아예 다른 표현이 생성될 수 있는 문제가 발생
-
따라서 최근에는 BERT와 같은 Dynamic embedding model을 사용하여 같은 단어여도 문맥마다 다르게 임베딩을 생성하는 방법을 사용한다.
-
하지만 그렇다고 정적 임베딩 모델이 안 좋은 게아니라, 앞서 언급했듯, 내가 수행하는 task에 따라 선택하는 게 중요하다.
