
-
PromptTopic
- 전통적인 토픽 모델(ex- LDA, NMF 등)이 아닌, Large Language Model(LLM)을 사용하여 토픽을 찾는 방법
Why LLM?
- 전통적인 모델과 달리 LLM을 사용하면 hyper-parameter tuning에 많은 시간을 할애하지 않아도 됨
- 기존 토픽 모델보다 좋은 성능
오늘은 WSM, PBM 2가지 방법 중 Short Text에서 좋은 PBM 방법에 대해 정리!
PromptTopic
- PromptTopic Figure
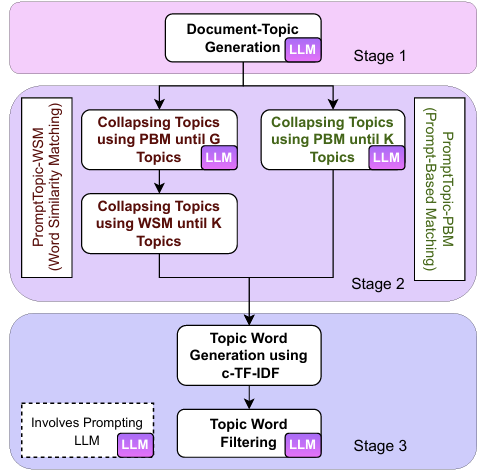
Stage 01. Topic Generation
-
LLM을 사용하여 입력 텍스트의 토픽을 생성하는 과정
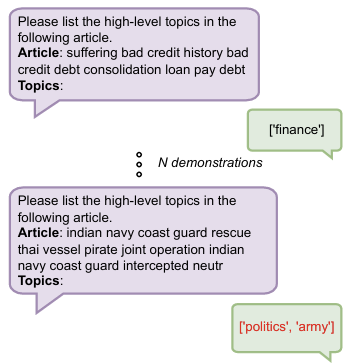
-
위 Figure는 Chat GPT에서 사용하는 프롬프트로, 보라색 블록은 사용자의 input, 연두색 블록은 샘플 응답(예시), 빨간색 글씨는 GPT의 응답을 의미
-
즉, N demonstrations는 GPT에게 응답 예시를 보여주는 것이고 최적의 예시 개수(N 값)은 2,4,6,8의 경우로 테스트 했지만 모델의 크기가 큰(파라미터 수가 많은) GPT의 경우, N값 변화에 대해 덜 민감한 결과를 보인다고 함!
Stage 02. Topic Collapse
-
LLM은 종종 문서에 대해 중복된 토픽을 생성함(예를들어- LLM이 생성한 토픽이 ‘film’, ‘actor’인 경우, ‘film’으로 합쳐질 수 있음)
-
위와 같은 중복 의미 토픽을 합치는 과정을 Collapse topics이라고 함
- 방법 1: WSM (Word Similarity Matching)
- 방법 2: PBM(Prompt-Based Matching)
(두 가지 방법 중 PBM이 Short Text에서 좋다는 결과가 있기 때문에 PBM 방법 정리)
PBM(Prompt-Based Matching) 과정
- unique topic을 포함하는 토픽 리스트 Tn을 생성 (Tn의 배열 순서는 빈도 기반 내림차순)
- Tn의 subset인 T(n-1) 생성 (첫 번째부터 n-1번째 순서까지 포함하는 subset. 즉, 빈도 수가 가장 작은 토픽만 제외한 토픽 set!)
- Tn의 각 토픽은 tn이라하고, 각 tn을 T(n-1) 중 한 토픽과 병합할 수 있도록 프롬프트 사용
- 만약, 병합 가능한 토픽이 T(n-1)에 없다면, tn은 ‘miscellaneous’와 병합한다.
- 이러한 과정을 Tn이 K개가 될 때까지 수행
(만약 데이터 셋 크기가 너무 커서 unique topic의 수도 커지고, 이로인해 작성 가능한 프롬프트 최대 토큰 수를 초과하는 경우라면 사이즈 M의 sliding window를 사용하여 해결)
Stage 03. Topic Representation Generation
- PrompTopic 모델의 성능을 평가하기 위해 토픽 모델에 많이 사용하는 평가지표 사용
- 그러나, 토픽 모델링 결과를 평가하기 위해선 word mixture로 표현 해야함
- PromptTopic 모델의 경우 바로 topic-word distribution을 생성할 수 없어, c-TF-IDF를 사용
- c-TF-IDF 가중치 기준 Top_100 단어를 얻고, 이에 다시 LLM을 사용하여 top 10 단어로 필터링
실험 결과
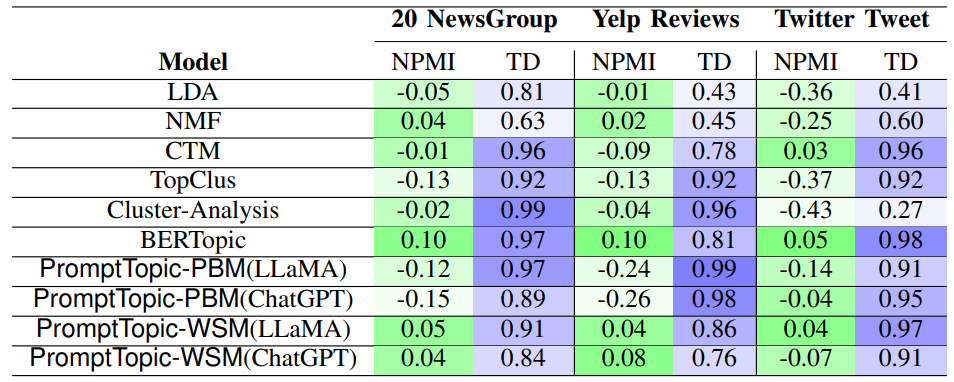
- 결과 1. NPMI, TD(Topic Diversity)
Baseline 모델(LDA, NMF, CTM, Cluster-Anlaysis, BERTopic)과 PromptTopic 모델 비교
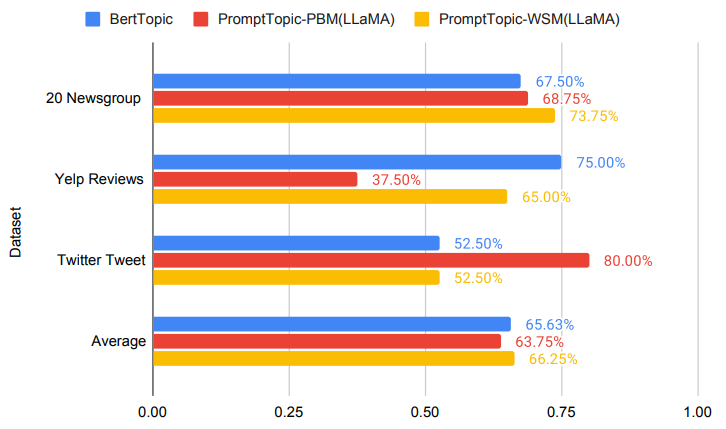
- 결과 2. Word intrusion task
BERTopic과의 성능 비교 (Accuracy)
- Word Intrusion Task란,
주어진 n개 단어에서 의미가 다른 단어를 뽑는 방법! 이를 통해 Topic Quality를 판단한다. - 4개 단어는 동일한 토픽의 단어, 1개 단어는 다른 토픽에서 임의로 선택
- 다른 토픽에서 선택한 임의 단어를 Intruder라고 칭함
- 만약, 사용한 모델이 토픽 모델링을 잘 수행했다면, Intruder를 찾기 수월할 것!
즉, 토픽 간 단어의 의미가 얼마나 잘 구분되는지 판단함으로써 모델의 토픽 모델링 품질 평가
- word intrusion task는 비용 소모가 크지만, 굳이 이 task를 하는 이유는 NPMI만으로 토픽 품질을 평가하기엔 단지 NPMI가 낮다는 게 토픽 퀄리티 낮음을 의미하지 않기 때문(약한 상관관계)
| Is automated topic model evaluation broken? the incoherence of coherence. A. Hoyle,2021
정리
-
결과 1, 결과 2를 보면 전체적으로 기본 모델보다 PromptTopic 모델이 더 좋은 성능을 보이긴 하나, 데이터 셋에 따라 상이한 결과를 보임
-
데이터의 특징(Long? Short? 등) 또는 성능 VS 소모되는 리소스(시간, 비용 등) 우선순위를 고려하여 Baseline 모델 대신 PromptTopic를 적용할 필요가 있다.
-
추가로, Twitter Tweet 데이터 셋에서 PromptTopic-PBM 모델이 좋은 결과를 보임!
일반적으로 토픽 모델에서는 short text에서 정보량이 적어 토픽 품질이 저하되는 단점이 있는데, Twitter Tweet와 같은 짧은 텍스트가 많은 데이터에서 PromptTopic 성능이 좋은 것으로 보아, 활용 가능성이 많은 모델일 것 같다. -
또한 LLM이 전통 토픽 모델보다는 파인튜닝, 개선의 여지가 커, 활용 가능성 측면에서도 훨씬 좋을 것으로 생각한다.
