
- 오늘은 Support Vector Machine에 대해 알아보자!
SVM(Support Vector Machine)
-
SVM은 회귀, 분류 task에 사용하는 머신러닝 모델 중 하나로, NLP, 신호 처리 등 다양하게 사용 가능한 모델
-
회귀는 SVR,분류는 SVC를 사용 -
sklearn 패키지에 내장
from skalern.svm import SVC, SVR 1. SVC(Supprt Vector Classifier)
-
먼저 분류 task에 사용하는 SVC의 목적은
label에 있는 데이터 중 서로 다른 label을 갖는 데이터 포인트를 가장 잘 구분하는결정 초명면(Decision Hyperplane)을 찾는 것! -
결정 초평면의 후보는 여러 개이고, 그 중
마진(margin)을 최대화 하는 평면을 찾는다.- 마진이란?
- 결정 초평면과 가장 가까운 데이터 포인트 간의 거리를 의미하며, 마진이 최대화 되는 평면이 데이터를 가장 잘 구분하는 결정 초평면을 의미
- 즉, 클래스 사이에 가장 넓은 안전지대를 확보하는 것과 같다.
- 마진이란?
-
마진이 최대화 되는 지점은
일반화 성능 향상,robustness 최대화,노이즈, 이상치에 강건을 의미 -
결정 초명면은 하나의 회귀식처럼
으로 나타낼 수 있고,
와 같이 나타낼 수 있다.
- SVC 예시
|출처: 위키피디아
2. SVR(Supprt Vector Regressor)
-
SVR은 회귀 task에 사용하는 모델로,SVC와 달리 회귀선에 가깝게 위치하도록 예측하는 게 주요 목적
(SVC의 결정 초평면 = SVR의 예측 회귀선) -
SVC에 마진(margin)이 있었다면, SVR에서는 -Tube가 사용된다.
- -Tube란,
- 예측 오류를 허용하는 일종의 안전 지대 역할
- 예측 함수 f(x)를 기준으로 ±만큼 떨어진 두 경계선으로 구성된 영역을
epsilon-Tube라고 한다. - -Tube에 속하면
무손실 영역으로, loss = 0이 되고, 튜브 바깥 쪽에 있을 때만 손실이 계산된다. - 사용자가 정해야 하는 하이퍼 파라미터로, 너무 작으면 over-fitting, 너무 크면 under-fitting이 발생하여 적절한 값이 중요하다.
- -Tube란,
- SVR 예시
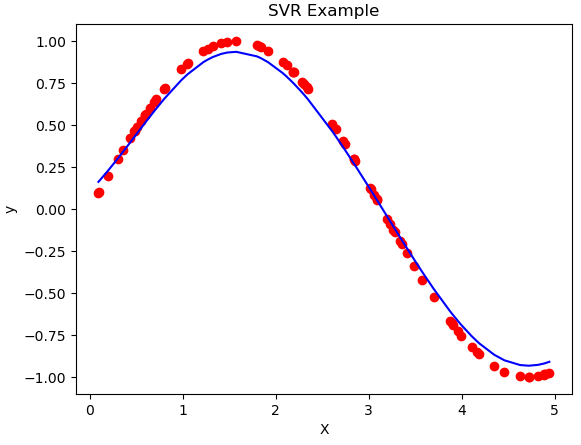
3. SVM Parameter
-
SVC, SVR 파라미터
parameter SVC SVR C O O kernel O O gamma O O epsilon X O
- 각 파라미터에 대해 살펴보자
C- 오류에 대한 패널티의 크기 파라미터(규제 역할)
- 값이 클수록 강하게 규제하여 Over-fitting 유발 가능성도 커짐
- 값이 작아지면 약하게 규제하여 Under-fitting 가능성 증가
- default = 1.0 (로그 스케일로 탐색)
Kernel- 커널 파라미터는
kernel trick에 사용되는 파라미터kernel trick이란,
선형 분류가 어려울 때 데이터를 가상의 고차원 공간으로 변환하여 이 공간에서 선형 방식으로 분류 or 예측을 가능하게 하는 방법
- 커널의 유형으로는
linear,poly(다항식 차수로 확장),rbf(무한 차원으로 데이터를 매핑)을 사용!
- 커널 파라미터는
gamma- gamma는 커널 트릭을 사용한 경우 사용
- 결정 경계(분류), 예측 함수(회귀)의 굴곡을 조절하는 파라미터
- gamma가 크면 굴곡이 심해짐 -> Over fitting 위험 높아짐
- gamma가 작아지면 굴곡이 덜해지고 일반화 성능이 좋아짐
C파라미터와 복합적으로 작용하여,gamma도 크고C도 크다면 (복잡성 강화 + 오류 허용 x)이 되니 Over fitting 주의!- scale, auto 값을 부여할 수 있고 상수로도 부여할 수 있다.
- 로그 스케일로 탐색
epsilon- SVR에만 사용하는 파라미터로, 앞서 설명한 -Tube의 범위를 설정하는 파라미터
- 0일 때 -Tube가 0이므로 양수 값만 사용
Kernel의 옵션은 poly, rbf를 제외하고도 sigmoid 또는 사용자가 정의한 커널을 사용하는 precomputed도 사용할 수 있지만 대부분 rbf를 많이 사용하니 참고하면 좋을 것 같다.
또한 본 포스팅에서는 다루지 않았지만 사용할 kernel마다 적용할 파라미터가 다르므로 사용자의 필요에 따라 공식 홈페이지를 참고하여 적용해야 한다.
(ex - poly(kernel) + degree 파라미터)
| https://scikit-learn.org/stable/modules/svm.html
