0. 들어가며
개발을 하다 보면 Spring과 MySQL을 함께 사용하는 경우가 많다.
나 역시 프로젝트를 진행하면서 DB와 연결해 데이터를 주고받는 작업은 익숙하지만 정작 내부적으로 어떻게 처리되는지에 대해서는 깊이 알지 못한 채 사용해왔다.
게다가 MySQL 8.0 이후 많은 구조적 변화가 있었고 스토리지 엔진별 차이나 쿼리 실행 흐름도 성능에 큰 영향을 줄 수 있다는 이야기를 자주 접하게 됐다.
하지만 정작 그 차이를 명확히 설명하거나 상황에 맞는 DB를 선택할 기준을 세우기는 쉽지 않았다.
이번 글에서는 단순한 사용을 넘어서 MySQL의 아키텍처 구조와 쿼리 실행 과정, 스토리지 엔진의 차이를 하나씩 정리해보려 한다.
이를 통해 DB를 더 잘 이해하고 설계와 선택에 자신감을 가질 수 있는 기반을 마련하고자 한다.
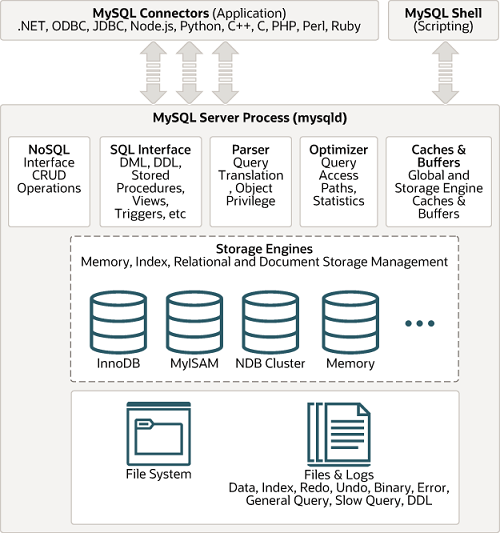
1. MySQL 아키텍처
MySQL은 크게 4가지 계층으로 구성되어 있다.
1.1 MySQL 접속 클라이언트
사용자가 MySQL 서버에 접근하기 위한 다양한 방식들을 담당한다.
MySQL은 다양한 언어와 플랫폼을 지원하기 때문에, 프로그래밍으로 작성된 코드도 이 계층을 통해 MySQL에 접속하고 쿼리를 실행할 수 있다.
- MySQL Connector: Java(JDBC), Python, PHP, Node.js 등 다양한 언어에서 MySQL에 연결할 수 있는 드라이버
- MySQL Shell / Workbench: SQL 명령을 직접 입력하거나 쿼리를 시각화할 수 있는 GUI/CLI 도구
- ODBC/.NET 드라이버: 윈도우 환경 또는 비즈니스 도구와 연결 시 사용
사용자의 SQL 요청을 받아 서버에 전달하는 역할로 클라이언트와 서버 간 통신은 TCP/IP를 기반으로 이루어진다.
1.2 MySQL 엔진
MySQL 엔진은 클라이언트로부터 전달받은 SQL 쿼리를 분석한다.
또한 어떻게 실행할지 결정하고 실행하는 중심 계층이면서 MySQL의 핵심 로직 대부분이 이 레이어에 존재한다.
우리가 작성하는 대부분의 SQL 쿼리는 이 계층에서 해석되고 실행된다.
1. NoSQL Interface
- MySQL은 일반적으로 SQL 쿼리를 사용하는 관계형 데이터베이스지만, 최근에는 SQL 없이 데이터를 다루는 방식도 일부 지원한다.
- 하지만 대부분 SQL 쿼리 기반 인터페이스(SQL Interface) 를 사용하기 때문에 이 기능은 보조적인 옵션으로 이해하면 된다.
꼭 SQL 문장을 쓰지 않아도 NoSQL처럼 간단한 명령으로 데이터를 다루는 유연한 방식도 가능하다는 의미
2. SQL Interface
- SQL 인터페이스는 우리가 평소에 작성하는 SELECT, INSERT, CREATE TABLE 같은 쿼리를 MySQL 서버가 처음으로 받아들이는 단계이다.
- 데이터를 조회(DML), 테이블 생성(DDL), 권한 설정(DCL) 등 다양한 쿼리를 보냄.
- 뷰(View), 트리거(Trigger), 저장 프로시저(Procedure) 같은 고급 SQL 기능 처리.
- 쿼리를 받아서 다음 단계인 Parser(파서)로 넘겨주는 역할.
3. Parser
- SQL 문장이 올바르게 작성됐는지 확인하는 단계
- 이 과정에서 테이블이나 컬럼이 실제로 존재하는지 사용자가 접근권한이 있는지도 확인한다.
- 문법 오류가 있거나 권한이 없으면 여기서 바로 에러가 발생
SQL 문장을 정리하고 검사하는 전처리 단계
4. Optimizer
- 가장 효율적인 쿼리 실행 방법을 찾는 역할
- 테이블을 어떤 순서로 읽을지, 인덱스를 쓸지 말지, 어떤 조인 방식을 쓸지 등을 결정한다.
- 이걸 실행 계획(Execution Plan)이라고 부르고 성능에 매우 큰 영향을 준다.
MySQL이 쿼리를 이해하고 실행 계획을 세우는 두뇌 역할
5. Caches & Buffers
- 속도 향상을 위한 메모리 최적화가 이뤄지는 부분
- 정렬, 조인, 임시 테이블 생성처럼 중간 결과를 다룰 때 메모리를 임시 저장소로 활용해서 성능을 높인다.
- 자주 사용하는 쿼리 결과나 임시 연산 결과도 메모리에 잠깐 저장돼 빠르게 다시 사용이 가능하다.
1.3 MySQL 스토리지 엔진
스토리지 엔진은 실제 데이터를 저장하고, 불러오고, 수정하는 역할을 맡는 계층이다.
사용자가 보낸 쿼리는 SQL 엔진을 거쳐 이곳까지 도달하고 스토리지 엔진이 최종적으로 데이터를 디스크에 저장하거나 조회함.
추가로 MySQL은 하나의 DBMS 안에서 다양한 스토리지 엔진을 사용할 수 있는 구조로 설계되어있다. (MySQL의 특징)
| 엔진 | 설명 |
|---|---|
| InnoDB | MySQL의 기본 스토리지 엔진. 트랜잭션, 외래 키, 롤백 등 고급 기능 지원. 실무에서 가장 많이 사용. |
| MyISAM | 예전 기본 엔진. 빠른 읽기 성능이 강점이지만, 트랜잭션 미지원. |
| Memory | 데이터를 메모리에 저장해 속도가 빠르지만, 서버 재시작 시 데이터 유실됨. |
| CSV | 테이블을 CSV 파일처럼 저장. 외부 시스템과 연동할 때 사용됨. |
| Archive | 많은 양의 데이터를 압축해 저장. 주로 로그 데이터 보관 용도. |
1.4 운영체제, 하드웨어
MySQL의 마지막 단계는 결국 운영체제와 물리적인 저장소(Disk)다.
스토리지 엔진이 데이터를 처리하면, 그 결과는 결국 파일 시스템을 통해 디스크에 저장한다.
- 이 계층에서 다뤄지는 것들
- 파일 시스템:
- InnoDB의 경우 .ibd, ibdata1, Redo/Undo 로그 파일 등으로 데이터를 저장함
- MyISAM은 .MYD, .MYI, .frm 등의 파일로 관리함
- 디스크 I/O:
- 실제 디스크에 쓰는 작업은 운영체제가 처리함
- MySQL은 내부적으로 캐싱(Buffer Pool)을 사용해 디스크 접근을 최소화하고 성능을 높임
- OS 자원 관리:
- CPU, 메모리, 파일 디스크립터 수, 스레드 수 등도 OS에 의존
- 서버 튜닝 시 이 계층까지 고려해야 함
- 파일 시스템:
2. MySQL 쿼리 실행 과정
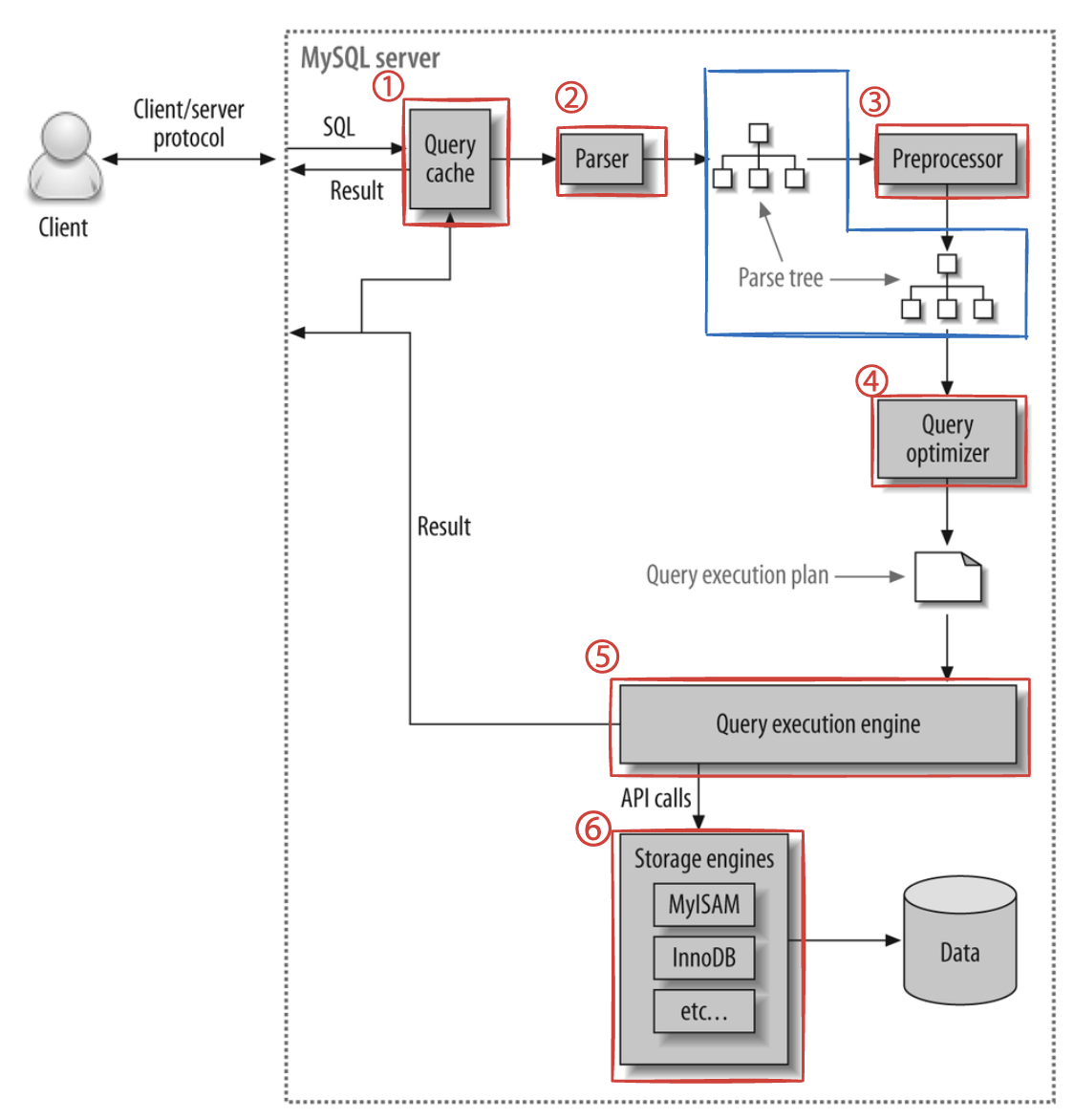
2.1 Query cache
- SQL 실행 결과를 메모리에 캐싱하는 역할
- 동일 SQL 실행시 이전 결과 즉시 반환
- 테이블의 데이터가 변경되면 캐싱된 데이터 삭제 필요
- 동시 처리 성능 저하
- MySQL 8.0 부터 완전히 제거됨
2.2 Parser
- SQL 문장을 토큰으로 쪼개서 트리로 만든다.
- 이 과정에서 쿼리 문장의 기본 문법 오류를 체크한다.
Parser Tree
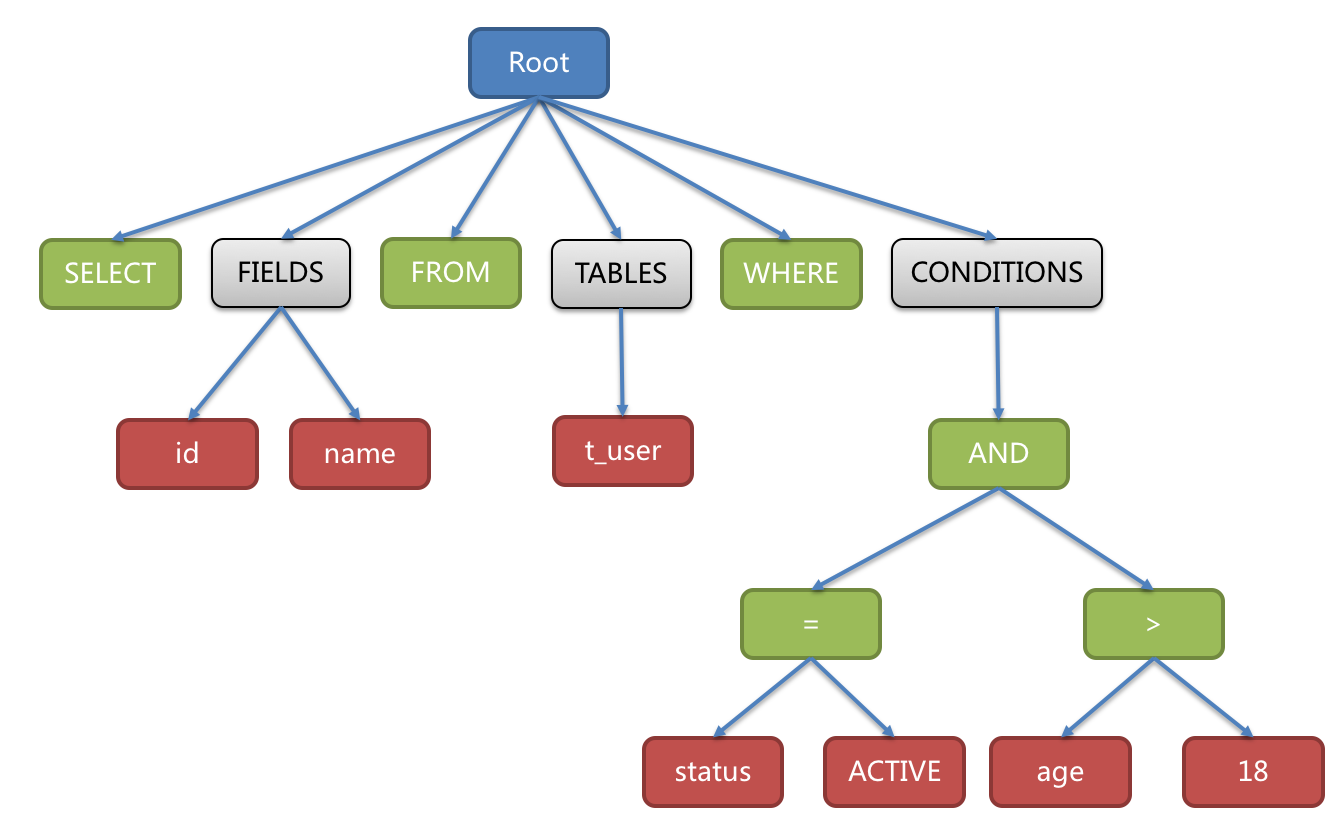
- 문법적으로 분석한 다음, 기계가 이해할 수 있도록 계층적으로 정리한 구조
- 다음 단계인 옵티마이저(Optimizer)가 실행 계획을 수립하는 데 기초 자료로 사용된다.
2.3 Preprocessor
- Parser Tree 를 기반으로 SQL의 문자 구조를 체크한다.
- Parser Tree 가 유효한지 확인
- 사용자의 접근 권한 확인
2.4 Query optimizer
- SQL 실행을 최적화 해서 실행 계획을 수립
- 크게 2가지 최적화 규칙이 있는데
- 규칙 기반 최적화
- 옵티마이저에 내장된 우선순위에 따라 실행 계획을 수립
- 비용 기반 최적화
- 작업의 비용과 대상 테이블의 통계 정보를 활용해서 실행계획 수립
- 규칙 기반 최적화
2.5 Query excution engine
-
옵티마이저가 만든 실행 계획대로 스토리지 엔진을 호출해서 레코드를 읽고 쓴다.
실행 엔진은 "무엇을 할지"가 아니라, "어떻게 할지"를 직접 실행하는 행동 주체다.
2.6 Storage engine
스토리지 엔진은 실제로 데이터를 저장하고 읽어오는 최종 계층이다.
쿼리 실행 엔진이 요청하면 스토리지 엔진은 그 명령에 따라 디스크에 접근해 데이터를 처리한다.
- 레코드 저장, 조회, 삭제, 수정 등 데이터 관련 모든 실제 작업 수행
- 디스크 I/O, 인덱스 관리, 트랜잭션 처리 등 물리적인 저장소 관리를 책임짐
- 실행 엔진이 전달한 실행 계획에 따라 동작하며, 결과를 다시 상위 계층에 전달
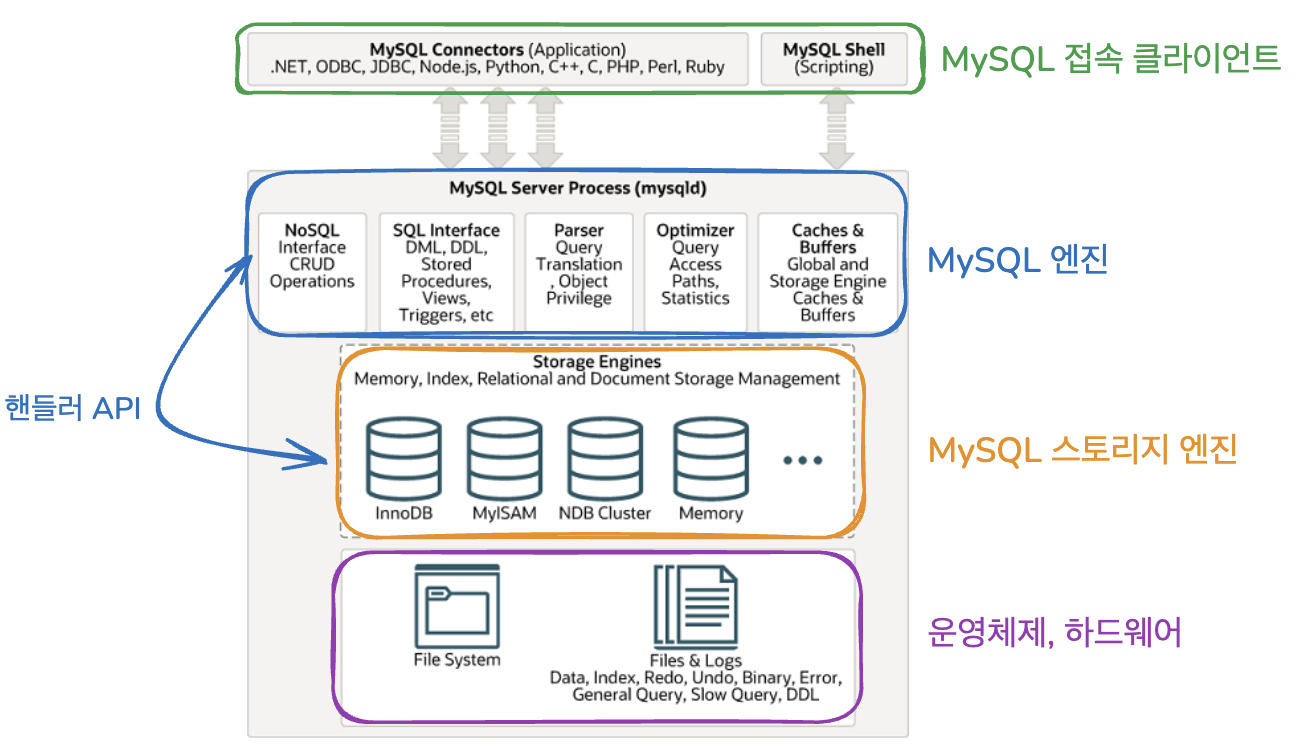
- 핸들러라고도 불린다.
핸들러(Handler)란?
스토리지 엔진은 Handler API라는 내부 인터페이스를 통해 SQL 엔진과 연결된다. MySQL 내부에서는 스토리지 엔진 자체를 핸들러(handler)라고 부르기도 한다.
3. InnoDB 스토리지 엔진
MySQL 8.0부터는 InnoDB가 기본 스토리지 엔진으로 채택되었으며 트랜잭션, 외래 키, MVCC, 충돌 제어 같은 고급 기능을 지원하는 강력한 저장 엔진이다.
단순히 데이터를 디스크에 저장하는 데 그치지 않고 메모리 관리, 로그 처리, 쓰기 최적화까지 수행하는 복잡한 내부 구조를 갖고 있다.
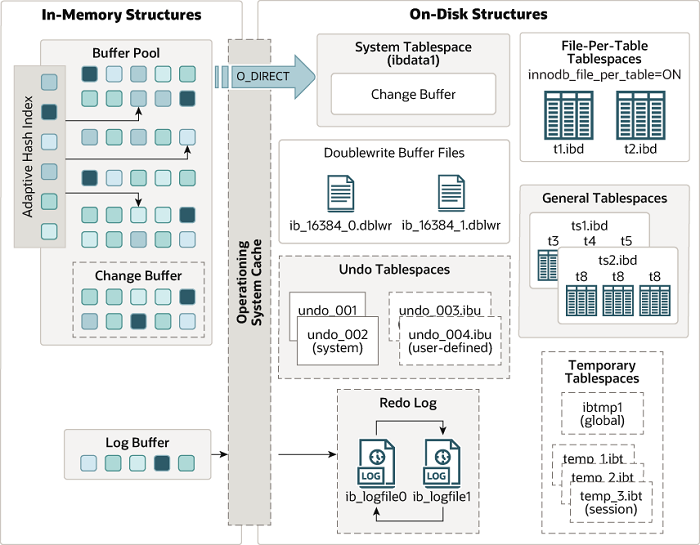
핵심 특징을 정리하면
3.1 PK 에 의한 클러스터링
InnoDB는 테이블의 데이터를 기본 키(Primary Key, PK) 순서대로 정렬하여 디스크에 저장한다.
이걸 클러스터링 인덱스 구조라고 부르며 InnoDB의 가장 큰 특징 중 하나다.
주요 특징
- 레코드를 PK 순으로 정렬해서 저장
- PK 인덱스 자동 생성
- PK를 통해서 레코드에 접근 가능
- PK를 통한 범위 검색이 매우 빠름
- 클러스터링을 쓰기 때문에 쓰기 성능 저하 (읽기에 최적화)
- 클러스터링 : 인덱스가 테이블의 데이터 자체와 함께 저장되는 방식
주의할 점
레코드를 정렬된 상태로 유지해야 하므로, 삽입/갱신 시 디스크 I/O 비용이 발생
→ 특히 중간 위치에 데이터를 삽입하거나 PK를 변경할 경우 쓰기 성능이 저하될 수 있음
PK를 자주 수정하거나, 랜덤한 값(UUID 등)을 PK로 사용하는 경우
→ 클러스터링의 장점을 제대로 활용하지 못하고 쓰기 병목이 발생할 수 있음
3.2 트랜잭션 지원
1. MVCC (Multi Version Concurrency Control)
MVCC는 동시에 여러 트랜잭션이 데이터를 접근할 수 있도록 허용하면서도, 데이터의 일관성을 유지하기 위한 기술이다.
InnoDB는 이 기능을 통해 트랜잭션 간 락(Lock) 없이 읽기 작업을 가능하게 만들어준다.
그림을 통해 이해해보자.
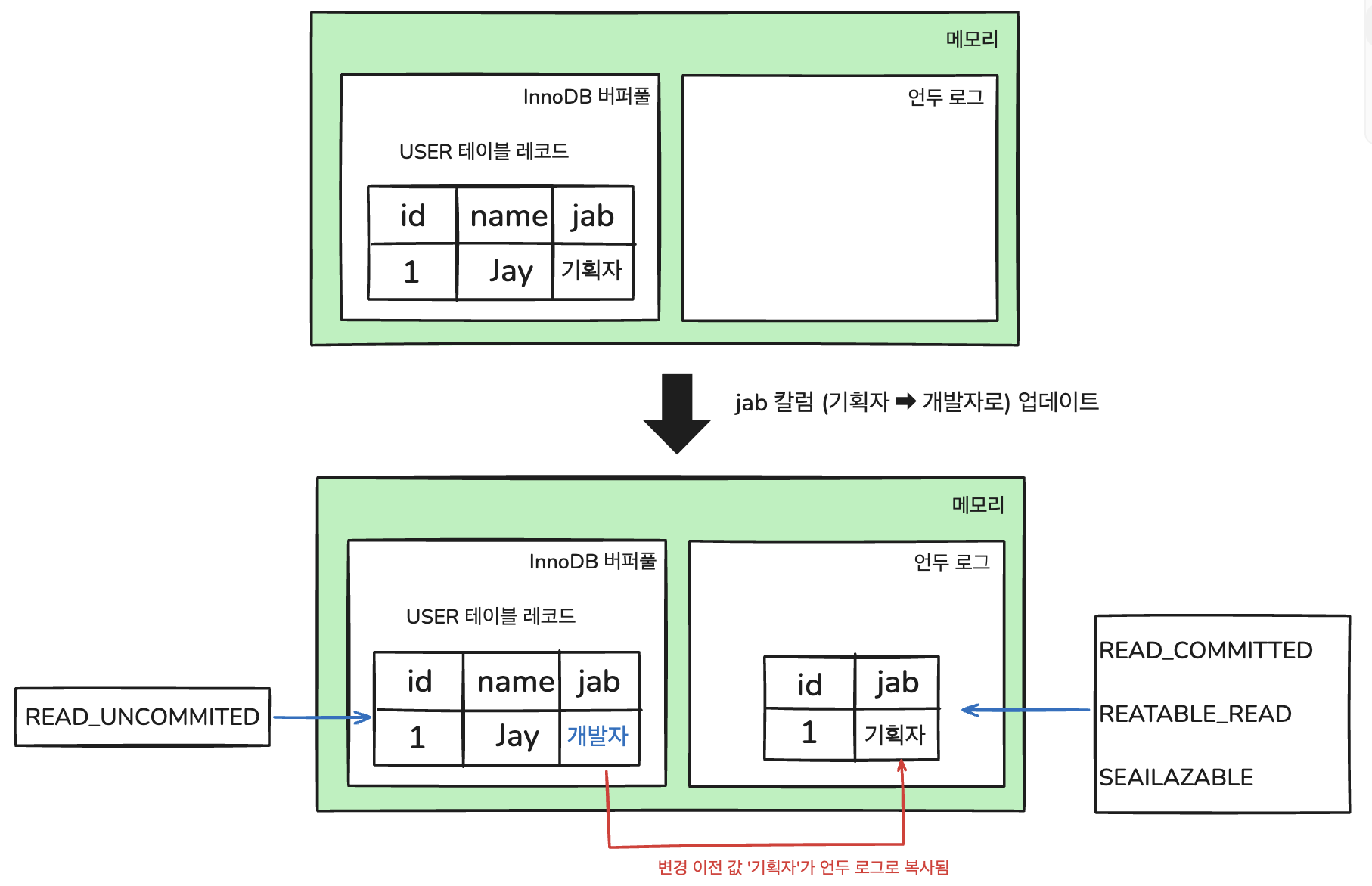
상황 요약
- USER 테이블: id, name, jab 컬럼 존재
- 기존 데이터 (커밋됨):
id: 1, name: Jay, jab: 기획자- 이후 트랜잭션 T2에서 다음과 같이 jab을 '개발자'로 수정함:
UPDATE USER SET jab = '개발자' WHERE id = 1;- 이 변경이 커밋되기 전/후에 따라 다른 트랜잭션(T1)이 어떤 값을 읽는지는 트랜잭션 격리 수준(Isolation Level)에 따라 달라짐
| 트랜잭션 격리 수준 | 커밋 전 읽기 결과 | 커밋 후 읽기 결과 | 설명 |
|---|---|---|---|
| READ UNCOMMITTED | '개발자' (변경값) | '개발자' | 커밋되지 않은 변경 내용도 읽을 수 있음 → Dirty Read 발생 가능 |
| READ COMMITTED | '기획자' (이전값) | '개발자' | 커밋된 내용만 읽음. 커밋 전엔 이전 값, 커밋 후엔 최신 값 읽음 |
| REPEATABLE READ (InnoDB 기본값) | '기획자' (이전값) | '기획자' (계속 동일) | 트랜잭션 시작 시점의 스냅샷을 유지 → 반복 조회 시 항상 같은 값 |
| SERIALIZABLE | '기획자' (이전값) | '기획자' (혹은 락 대기) | REPEATABLE READ처럼 보이지만, 실제론 읽기에도 락을 걸어서 완벽한 직렬화 보장 |
2. Undo Log & Redo Log
InnoDB는 ACID를 보장하기 위해 Undo Log와 Redo Log라는 두 가지 핵심 로그 시스템을 사용한다.
- Undo Log
- 변경되기 이전 데이터를 백업
- 트랜잭션 보장 (Rollback 시 언두 로그에 백업된 데이터 복원)
- 트랜잭션 격리 수준 보장(트랜잭션 격리 수준에 맞게, 백업된 데이터 반환)
- Redo Log
- 변경된 데이터를 백업(Commit이 완료된 데이터)
- 영속성 보장(서버 비정상 종료 시 리두 로그에 백업된 데이터 복원)
3. 레코드 단위 잠금
InnoDB는 데이터를 읽거나 수정할 때, 테이블 전체가 아닌 "해당 레코드(행)"만 잠그는 방식을 사용한다.
이를 레코드 단위 잠금(또는 행 잠금, Row Lock)이라고 부른다.
예시 DB 설명
- 총 1000명 학생
- 학년은 1학년부터 4학년
- 2학년 학생 수: 600명
- grade(학년) 컬럼에 인덱스 생성
- id는 PK(Primary Key)
- 제주도에 사는 학생은 1명 밖에 없음.
3.3.1 보조 인덱스 (grade = 1)로 조회할 때의 잠금
address 가 제주도인 학생의 주소를 변경하는 쿼리를 작성할 때 grade(학년) 인덱스를 사용하게 되는데 이때 어떤 레코드가 잠기게 될까?
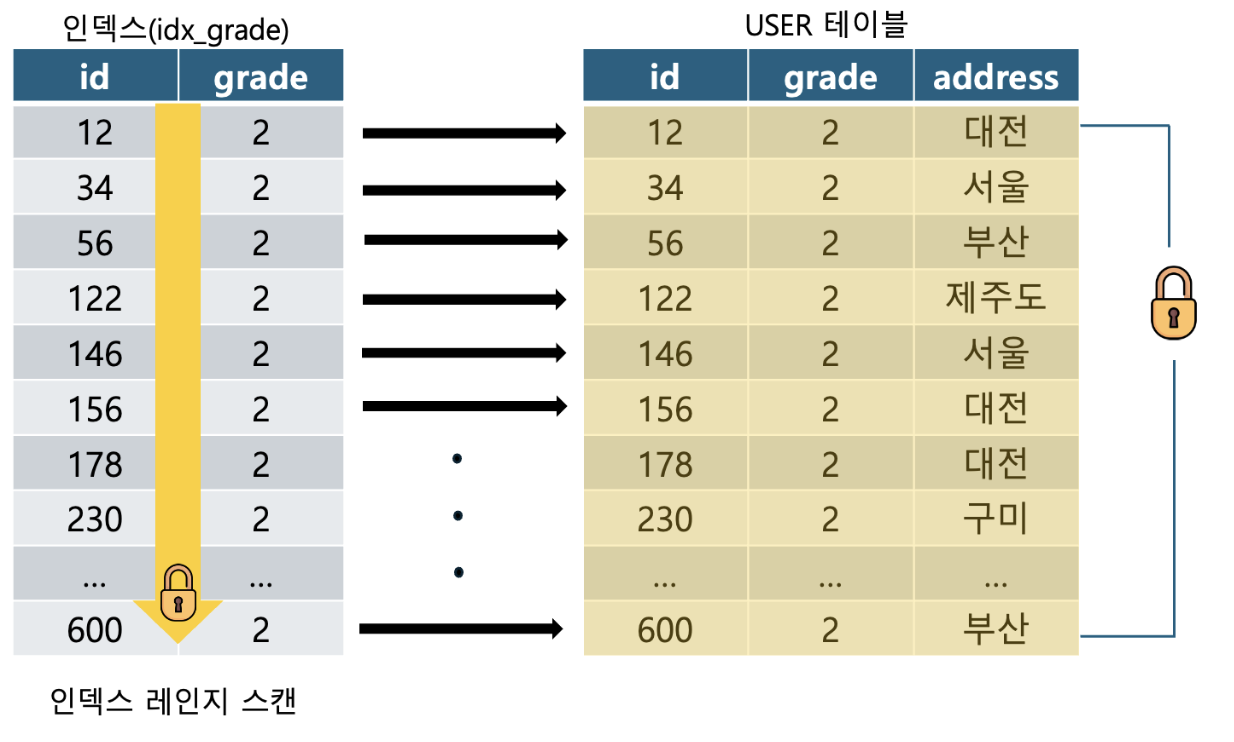
학년이 2학년이 모든 레코드를 잠그는 방식으로 처리된다.
3.3.2 인덱스 (id)로 조회할 때의 잠금
id 인덱스를 사용할 때는 어떤 레코드가 잠기게 될까?
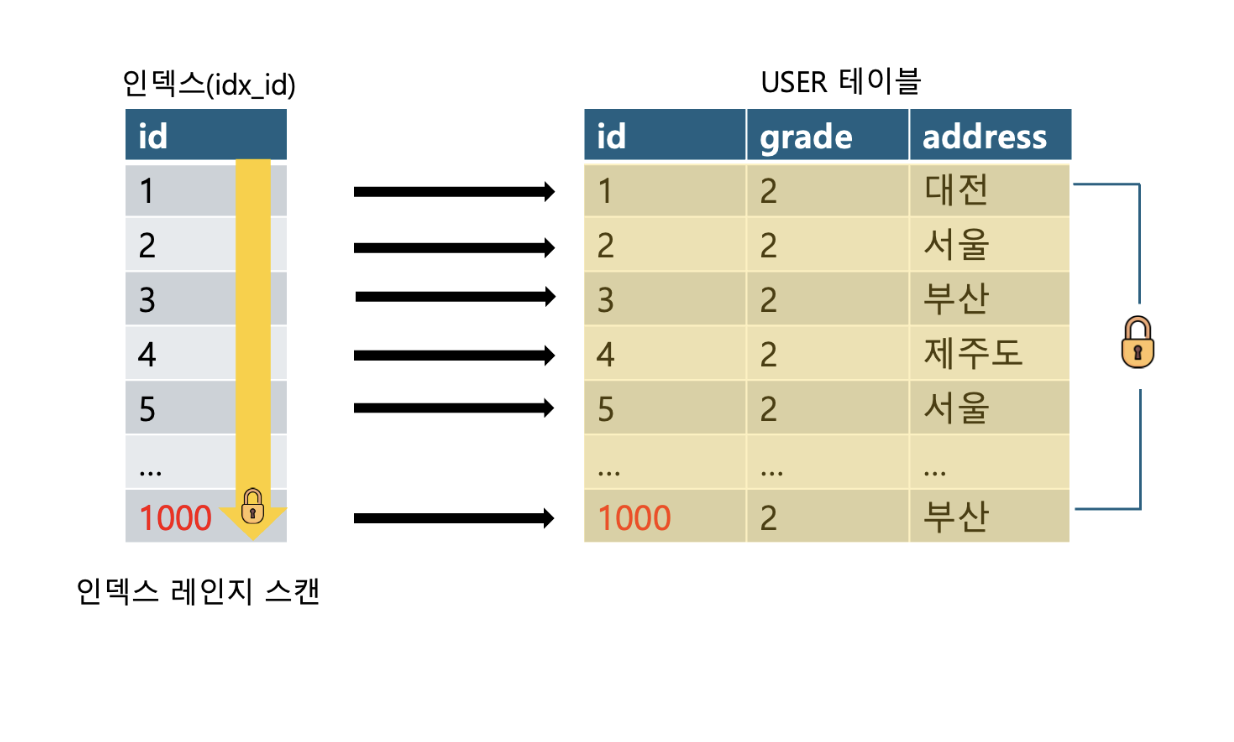
모든 데이터인 1000개의 레코드가 잠기게 된다. (풀스캔)
3.3.3 인덱스 (grade_address)로 조회할 때의 잠금
grade 와 address에 대한 복합 인덱스를 생성했다면?
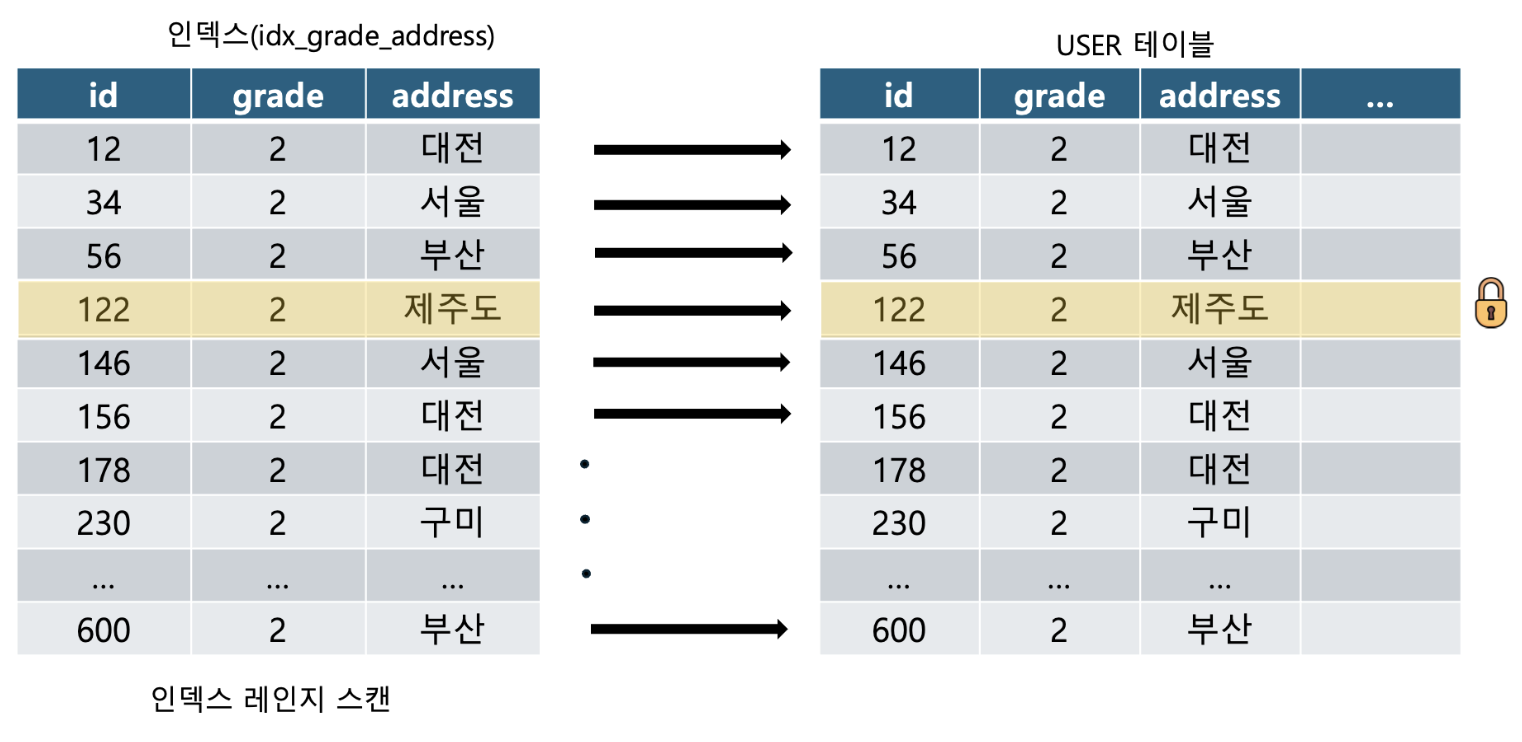
제주도에 사는 학생은 1명 밖에 없기 때문에 그림과 같이 1개의 레코드만 잠기게된다.
이렇게 인덱스를 어떻게 설정 하는지에 따라 레코드의 잠금 범위가 달라질 수 있다.
3.3 InnoDB 버퍼풀 & 어댑티브 해시 인덱스
InnoDB는 디스크 기반 스토리지 엔진이지만, 성능을 최대한 높이기 위해 메모리 캐시 계층을 적극적으로 활용한다.
대표적인 구조가 버퍼 풀(Buffer Pool)과 어댑티브 해시 인덱스(Adaptive Hash Index, AHI)다.
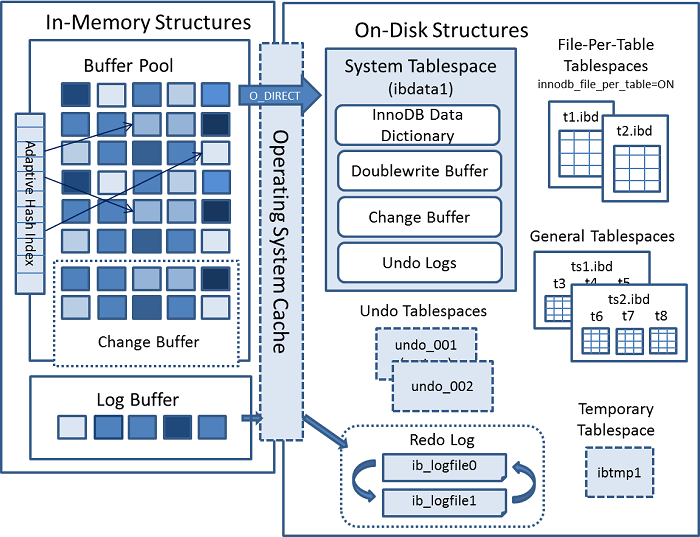
InnoDB 버퍼풀
버퍼 풀은 InnoDB의 핵심 메모리 캐시 영역으로 디스크의 데이터를 페이지 단위(기본 16KB)로 불러와 메모리에 저장하고 관리한다.
- 주요 기능
- 데이터 & 인덱스 캐싱
- 테이블의 데이터뿐 아니라 B+Tree 인덱스 페이지도 함께 캐싱됨
- 디스크 접근 없이 메모리에서 바로 데이터를 조회할 수 있음 (읽기 성능 대폭 향상)
- 페이지 단위 관리
- InnoDB는 모든 데이터를 16KB 단위의 페이지(Page)로 관리
- LRU 알고리즘 사용
- Least Recently Used 방식으로 오래 사용하지 않은 페이지부터 제거
- 자주 접근되는 페이지는 메모리에 남아 성능 유지
- 쓰기 지연
- 데이터를 변경하면 디스크에 바로 쓰지 않고 버퍼 풀 내의 페이지를 먼저 변경한 뒤 일정 시점에만 디스크로 플러시(쓰기)
- 데이터 & 인덱스 캐싱
어댑티브 해시 인덱스
InnoDB는 자주 접근되는 인덱스 페이지를 더 빠르게 접근하기 위해 해시 테이블 기반의 인덱스를 자동으로 만들어 사용한다.
주요 특징
| 항목 | 설명 |
|---|---|
| 자료구조 | <인덱스 키, 페이지 주소> 쌍으로 구성된 해시 테이블 |
| 생성 방식 | 자주 사용되는 인덱스 키 범위에 대해 InnoDB가 자동 생성 |
| 역할 | B+Tree 탐색 없이, 해시 탐색만으로 해당 페이지에 빠르게 접근 |
| 동작 시점 | 조회가 반복되는 특정 인덱스 키에 대해 동적으로 생성됨 |
주의점
너무 많은 해시 인덱스가 생성되면 오히려 해시 테이블이 커져서 관리 비용 증가한다. 서버에 따라 자동 생성이 부담되면 설정으로 끌 수도 있음
4. MyISAM 스토리지 엔진
MyISAM은 MySQL 5.5 이전까지의 기본 스토리지 엔진이었으며 빠른 읽기 성능과 단순한 구조로 인해 한때 많이 사용됐다.
하지만 트랜잭션 처리나 데이터 무결성 지원이 부족하기 때문에 요즘은 정적 데이터, 로그, 읽기 위주 시스템 등에서 제한적으로만 사용된다.
- 1. 트랜잭션 미지원
- COMMIT, ROLLBACK 같은 기능이 없음
- 데이터 정합성이 중요한 환경에는 적합하지 않음
- 2. 테이블 단위 잠금 (Table-level Locking)
- 하나의 레코드를 수정해도 전체 테이블이 잠김
- 다중 사용자가 동시에 쓰기 작업을 하기에 매우 비효율적
- 3. 빠른 읽기 성능
- 구조가 단순하고, 추가적인 무결성/로그 관리가 없기 때문에 읽기 속도가 빠름
- 정적 데이터(예: 게시판 조회, 통계 페이지 등)에는 적합
- 4. 전체 텍스트 검색 지원 (Full-Text Index)
- InnoDB보다 먼저 FULLTEXT 인덱스 기능을 지원함
- 검색이 중요한 시스템에서는 MyISAM이 더 편했던 시절도 있음
InnoDB vs MyISAM 비교
| 항목 | InnoDB | MyISAM |
|---|---|---|
| 트랜잭션 | ✅ 지원 (COMMIT, ROLLBACK 등) | ❌ 미지원 |
| 잠금 방식 | ✅ 레코드 단위(Row Lock) 동시성 우수 | ❌ 테이블 단위(Table Lock) 쓰기 충돌 많음 |
| 외래 키(Foreign Key) | ✅ 지원 | ❌ 미지원 |
| MVCC (다중 버전) | ✅ 지원 (REPEATABLE READ 기본) | ❌ 미지원 |
| 데이터 무결성 | ✅ 강력 (제약조건 + 복구 메커니즘) | ❌ 약함 (제약 조건 없음) |
| 장애 복구 | ✅ Redo/Undo 로그를 통한 복구 가능 | ❌ 복구 기능 거의 없음, 데이터 손상 시 취약 |
| 읽기 성능 | 🔼 빠르지만 구조가 복잡 (쓰기와 동시성 고려) | 🔼 매우 빠름 (구조 단순, 경량화) |
| 쓰기 성능 | ⚠️ 레코드 단위 락으로 상대적으로 느릴 수 있음 | ❌ 테이블 락 때문에 쓰기 동시성 매우 낮음 |
| 전체 텍스트 검색 (FULLTEXT) | ✅ MySQL 5.6부터 지원 | ✅ 원래부터 지원 (빠름) |
| 스토리지 구조 | .ibd 파일 (데이터+인덱스 통합) | .MYD(데이터), .MYI(인덱스), .frm(메타) |
| 권장 용도 | 대부분의 OLTP 시스템, 일반적인 웹/앱 서비스 | 읽기 위주 정적 테이블, 임시 테이블, 로그 등 |
| 현재 위치 | ✅ MySQL 기본 스토리지 엔진 (8.0 기준) | ⚠️ 레거시 / 특수한 경우만 사용 |
