자료구조를 왜 쓰지?
데이터를 저장, 조작을 용이하게 하기 위해서~
백엔드는 데이터 처리를 잘 해야 하는데, 데이터 가지고 연산해야 하는데, 이 데이터를 담는 무언가가 필요한데, 이런 것을 용이하게 하는 것이 자료 구조이다.
예를 들어, 사과를 어떻게 하려는 목적에 따라 바구니가 다르듯이? 사과를 금방 먹을 거면, 작은 sac이 필요하고 나중에 갈아서 먹을 거면 믹스기가 있어야 하고 오랫동안 가지고 다닐꺼면 백팩 등 이라고 생각하자.
사과 = 데이터
sac, mixer, backpack = 자료 구조
어떤 자료 구조를 선택하냐 따라, 그 시스템의 코드량, 서비스 등이 완전 달라진다.
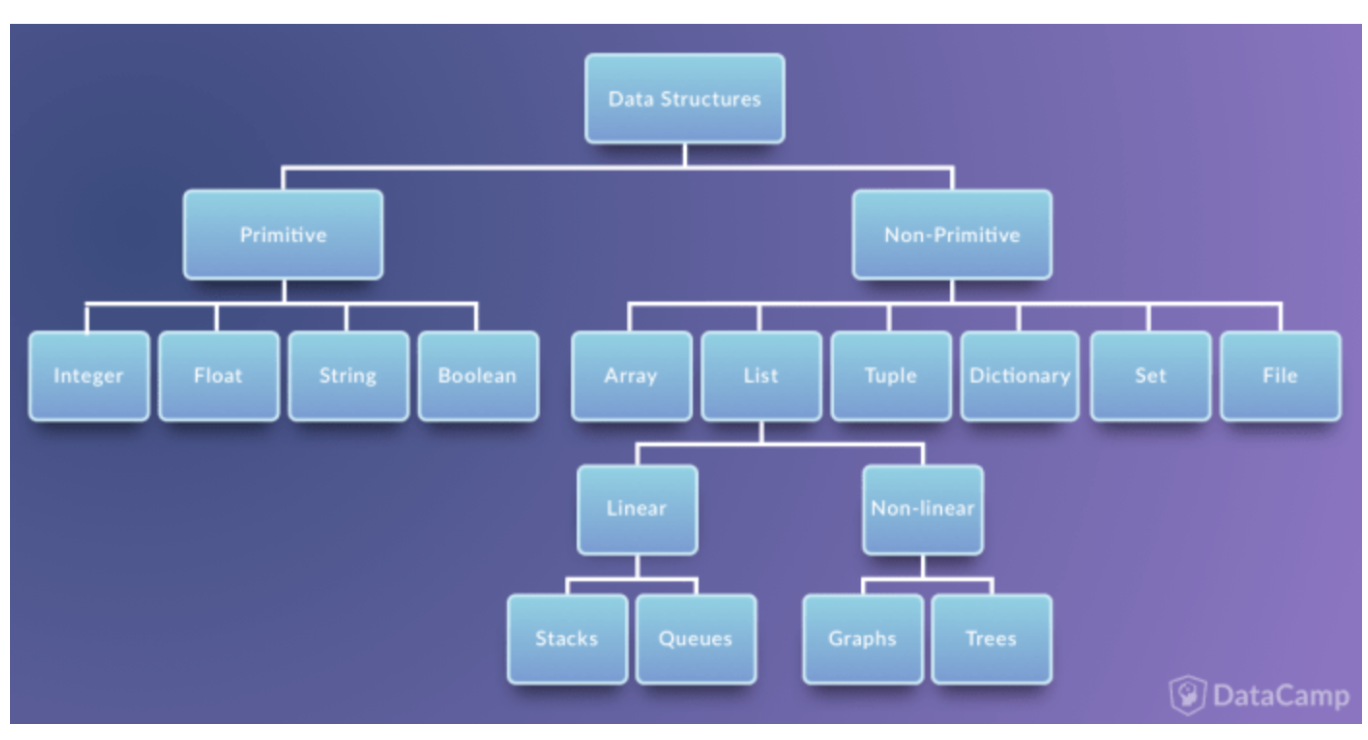
일반적인 자료구조는 Non-Primitive이다. Primitive는 자료구조이긴 한데,우리는 type으로 알고 써왔을 뿐.
가장 자주 사용하는 자료 구조인 Array를 먼저 보자!!
- Array
데이터 순서가 있다! (= index가 있다.)
실제로 메모리에 순서대로 저장된다.
[0,1,2,3,4]
*여기서 메모리의 반대는 하드 디스크이다. 하드 디스크는 데이터 베이스 형식으로 저장된다.
순서가 있기 때문에 우리는 특정 순서의 element를 바로 access할 수 있다.
[0,1,2,3,4,5] arr[2]하면 2로 바로 나온다.
순서가 있기 때문에 slice도 할 수 있다.
[0:4] 하면 [0,1,2,3,4] 배열을 본다.
- Multi Dimentional Array
Array의 요소가 Array가 될 수 있는데 이를 Multi Dimentional Array라고 한다.
A= [[11,12,13],[21,22,23],[31,32,33]]
이런거
2D Array이다.
보통 Matrix에서 많이 쓰인다. 바둑판 같은 거~
Array는 메모리에 바로 순서대로 저장되니 빠르게 연산이 가능하다.
단점!!!
만약, [0,1,2,3,4,5]의 배열 데이터를 저장하려고 하는데 3과 4 사이에 다른 데이터인 'a'가 있다고 하면 연속성에 어긋난다. 그러니
메모리는 연차적으로 저장하므로, Array를 사용할 때 일단 5만큼의 default 공간을 확보하고 시작한다.
0부터 100까지의 데이터 양이 필요하다면, 100 만큼의 공간을 확보해서 메모리에 넣는데, 101이 갑자기 추가 되면 0부터 200까지의 공간을 메모리에 가져와서 0부터 100까지의 데이터를 복사 붙여넣기 한 뒤 101을 넣는다. 공간이 갑자기 2배 커지고 복사 붙여 넣기 하니 과정이 비싸다. 이것을 resizing이라고 한다.
또한 중간에 있는 데이터를 지우는 것도 힘들다. 3을 없애려고 하면, 단순히 3만 없애는 것이 아니라 3을 없애고 4와 5를 옆으로 재배치 해야 하기 때문에 힘들다.
그럼 Array를 사용하면 좋은 경우는 무엇이 있을까?
등수, 학생 번호, 주식 가격등
- Tuple
List와 마찬가지로 순차적인데 다만, element가 2개~5개 정도만 사용 가능하다. 그리고 수정이 불가하다.
좌표 같은 것을 사용할 때, 사용 가능하다. [(1,0),(2,0),(3,1)] 이렇게
List로도 표현이 가능한데, 메모리가 조금 더 적다.
또한 test =() =>{return ("a",7) 이렇게 2개를 동시에 return하려면 좀 더 편하다.
단점은 (1,2) (3,4)이 중에 1과 3이 x좌표고 2와 4가 y좌표인지 모른다. 상식적으로 그렇게 여기겠지만..... 그래서 field name을 주기 위해 named Tuple도 python에서 제공한다. class처럼 사용 가능~
- Set
순서가 존재하지 않다. 그리고 중복된 값이 허용되지 않는다.
my_set = {1,2,3,4,5,1,2}이렇게 하면 {1,2,3,4,5}이렇게 출력된다.
주민번호, 자동차 번호판, 휴대번호 같은거가 여기 set의 데이터 시스템일 수 있다.
중복 되면 안되고 순서는 상관 없는 경우
예를들어, 내가 선거를 하기 위해서 100명의 아르바이트생에게 100개의 휴대폰 번호를 가져와 달라고 부탁했다. 그러면 10,000의 번호가 있을 텐데, 중복 될 가능성이 30%가 있다. 선거법상 홍보 광고 문자를 보내면 위반이기 때문에 중복 번호를 빼는 데이터 배이스를 만들어 달라고 했다. List를 쓰면 1부터 10,000의 데이터를 for 한번 돌고 중복되는지 안 되는지 한번 더 for을 돌아야 하기 때문에 for을 두번 돌아야 한다. 그런데 set을 쓰면 바로 걸러지기 때문에 쓰면 훨씬 좋다. List를 쓰면 최대 10,000^2만큼 돌아야 할 수 있다. 느리다.
Set은 왜 순서가 없을까? list와는 다르게 메모리에 1을 저장할 때, 1을 hash해서 2345라는 임의의 값에 해당하는 빈 메모리(버켓)에 저장한다. 2를 저장할 때, 2를 hash해서 3542라는 임의의 값에 해당하는 빈 메모리에 또 저장한다. 빈 메모리는 순서가 없다.
사진 참조!
set은 숫자 찾기 편하다.
0부터 n까지의 set 중에서 45를 찾고 싶다 하면 for을 돌려서 45가 나올 때까지 봐야한다. 그것을 o(N)이라고 한다. 이것이 LookUp이다. 특정 전화번호가 전화번호부에 있는지 없는지 확인할때.
- Dictionary(object, Hash map)
key,value를 저장하는 형식
class형식이다.
my_dict = ( 1: "one", 2: "two", 3: "three")
key는 1,2,3이고 value는 one two three이다.
key또한 hash기반으로 set과 동일하다. 중복이 안 되며 순서가 상관 없다.
key를 hash로 바꿔서 해당 bucket list에 넣는다.
- stack/ Queue
데이터를 먼저 넣은 것을 나중에 꺼낸다.
브라우저의 뒤로가기 버튼은 stack
Queue는 레스토랑 예약
Priority Queue는 OS같은거? 운영체제에서 cpu를 가지고 multitasking을 돌리는데, 운영체제 업그레이드에 우선순위가 있어서 내가 게임을 실행 먼저 시켜도 운영체제가 먼저 실행 되는 형식
- Tree
