오늘은 드디어 CNN에 대해 설명해보려고 합니다 !
CNN은 보통 이미지를 분석할 때 많이 사용하는데요.
그 이유는 Dense Layer로 하기에는 너무 빡세서...?
예를 들어서 500X500 짜리의 이미지를 분석하려고 해도 Flatten하면 무려 25만개로 늘어납니다...!
엄청난 계산량이 필요해지기 때문에 CNN을 사용하는 것이죠.
게다가 이미지의 위치가 중앙에 있는 것이 아니기 때문에, 즉. 정형화 되어 있지 않아서 CNN을 사용해야 합니다!
CNN 구조
딥러닝에서의 CNN에서 가장 중요한 것은 스스로 feature를 찾는 것입니다!
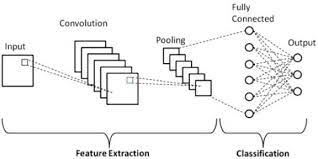
위의 그림이 딥러닝에서 CNN의 구조입니다.
Feature Extraction 부분에서 스스로 특징을 찾아내는 학습을 수행합니다.
입력층 근처에서는 보다 세밀하게 feature를 추출하면서 점점 layer를 지나갈수록 추상화 시킵니다!
(추상화를 시켜 학습시켜야 제대로 알아볼 수 있으니까요...?)
CNN은 이렇게 최적의 feature를 추출해내는 것이 중요합니다.
즉, 최적 Feature 추출을 위한 필터 값을 계산하는 것입니다.
이미지 필터 (Filter)
CNN에서 또 굉장히 중요한 것이 바로 filter입니다.
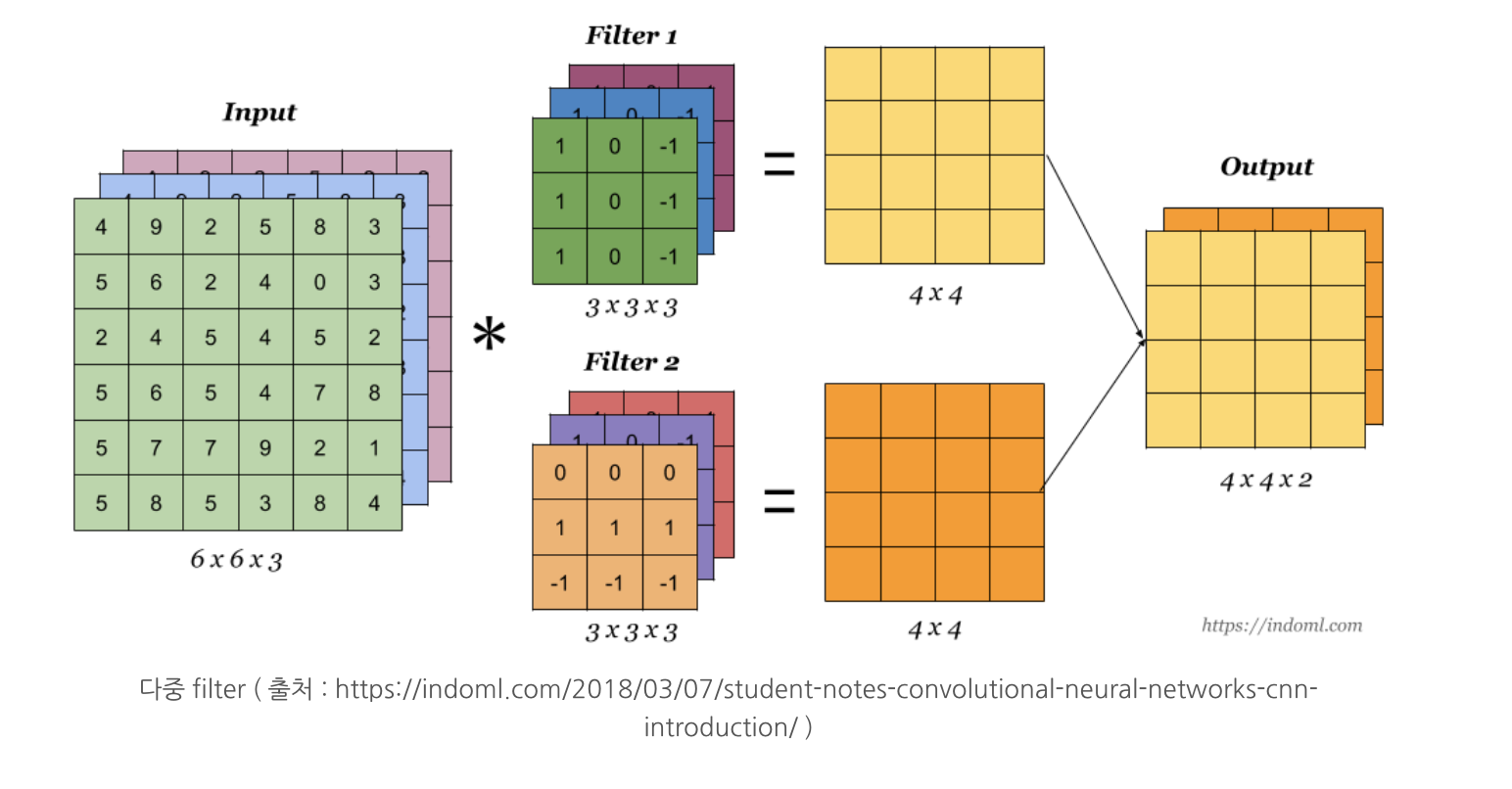
위의 사진을 보면 쉽게 이해하실 수 있습니다!
마치 종이필터를 통해 보는 듯한 느낌이라고 생각하시면 쉬울 것 같은데요!
Filter 1의 3X3X3 필터가 Input 이미지를 가장 왼쪽 상단에서부터 쭈욱~ 합성곱을 합니다.
왼쪽에서 오른쪽으로 합성곱을 하고난 뒤, 한 칸(stride가 1일 때) 밑의 가장 왼쪽부터 다시 오른쪽으로 쭈욱~ 합성곱을 합니다!
그렇게 해서 나온 결과 값은 4X4의 행렬이 됩니다!
이렇게 여러가지의 필터를 씌워 학습을 진행합니다. 필터의 값은 딥러닝 스스로 결정하는 것이구요!
stride
위에서 살짝 언급한 stride는 filter가 얼마나 움직이는 것인가 입니다.
만약 stride가 2라면 위의 6X6의 이미지가 3X3의 필터를 만났지만, 한번 움직일 때마다 2칸씩 움직이므로
2X2가 됩니다.
- stride를 키우면 공간적인 feature 특성을 손실할 가능성이 높습니다.
- 그러나, 불필요한 특성을 제거하는 효과를 가져올 수도 있습니다!
- Convolution 연산 속도를 향상시키기도 합니다.
padding
Filter를 여러 번 적용하여 Layer가 길어지다보면, 위에서 보시다시피 출력 Feature map이 입력 Feature map보다 계속 작아지는 것을 확인할 수 있습니다.
따라서 Filter 적용 전 보존하려는 Feature map 크기에 맞게 입력 Feature map의 좌우 끝과 상하 끝에 0으로 값을 채워, Feature map의 size를 키웁니다!
- padding을 설정하면, 노이즈가 생길 순 있지만 큰 영향은 없습니다.
- 모서리 주변 feautre들의 특징을 보다 강화하는 장점이 있습니다.
- Conv2D()에 인자로
padding = 'same'을 설정하면, 자동으로 입력 feature map과 출력 feature map의 크기가 같게 적용됩니다.
pooling
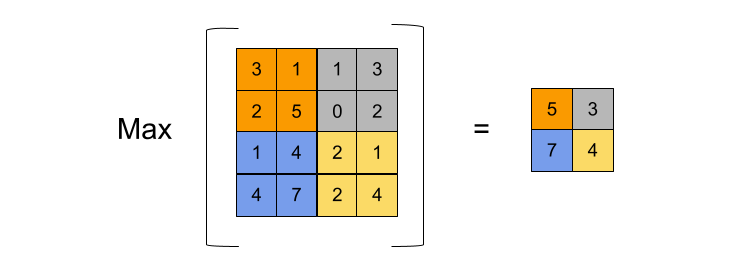
출처 : https://androidkt.com/explain-pooling-layers-max-pooling-average-pooling-global-average-pooling-and-global-max-pooling/
pooling은 위의 그림과 같이 stride 크기와 pool size를 동일하게 하여, pool size 내에서 특정 값만 가져오는 것입니다.
위의 그림과 같은 Max Pooling같은 경우는 2X2의 pool size를 가지고 stride는 2로 (pool size와 stride가 같아야 하므로) 하여, 2X2씩 중에 가장 큰 값을 뽑아내서 출력해냅니다.
- pooling은 비슷한 feature들이 서로 다른 이미지에서 위치가 달라지면서 다르게 해석되는 현상을 중화해줍니다.
- Feature Map 크기가 줄어 계산 속도가 향상됩니다.
Max Pooling을 하면Sharp한 feature 값추출,Average Pooling의 경우Smooth한 feature 값추출 가능- 최근에는 Pooling을 많이 사용하지 않는다고 합니다! (손실되는 것이 생겨서)
이렇게 CNN에 사용되는 기법에 대해 여러가지 간략하게나마 알아보았습니다!
틀린 부분은 얘기해주시면 수정하겠습니다~ 감사합니다.
