간혹 ResNet의 skip-connection이 Vanishing gradient 문제를 해결하기 위해 나온 방법이라고 알고 있는 분들이 있다. 이는 사실이 아니다.
왜냐하면 Vanishing gradient 문제는 ReLU 라는 활성화 함수를 통해 해결되었기 때문이다.
ReLU 이전
ReLU가 세상에 나오기 이전, 활성화 함수로 sigmoid를 대부분 사용해왔다.
그러나 sigmoid는 큰 문제점이 있다.
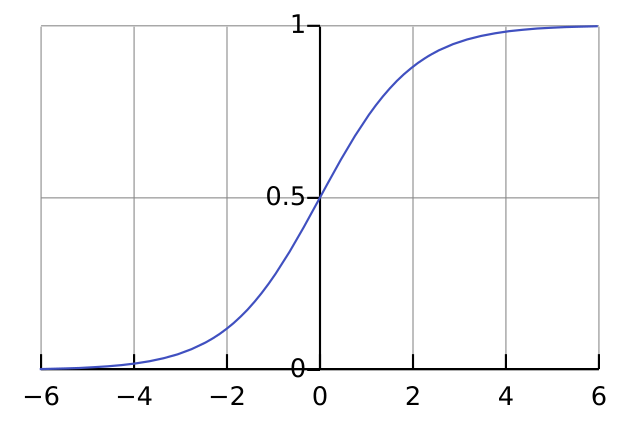
Sigmoid는 backpropagation을 통해 gradient descent를 하여 가중치를 업데이트할 때, 입력에 가까운 노드에서는 gradient 값이 매우 작아진다.
왜냐하면, sigmoid 함수에서 기울기가 가장 큰 부분이 약 1/4 정도밖에 되지 않기 때문이다.
이렇게 몇 번의 기울기들이 곱해지기만 해도 0에 가까운 gradient를 갖게 될 것이다.
그렇기 때문에 제대로 된 학습이 불가능하다는 문제점이 있다.
ReLU의 등장
그렇게 해서 나온 활성화 함수가 ReLU(Rectified Linear Unit)이다.
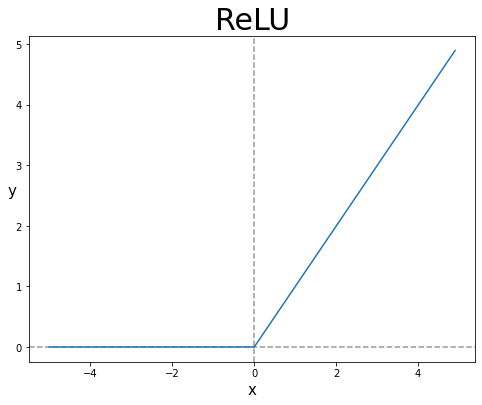
- ReLU는 0보다 클 때 그대로의 미분값을 전달하여 gradient가 소실되는 것을 방지한다.
- 그렇다면 0보다 작을 때는?
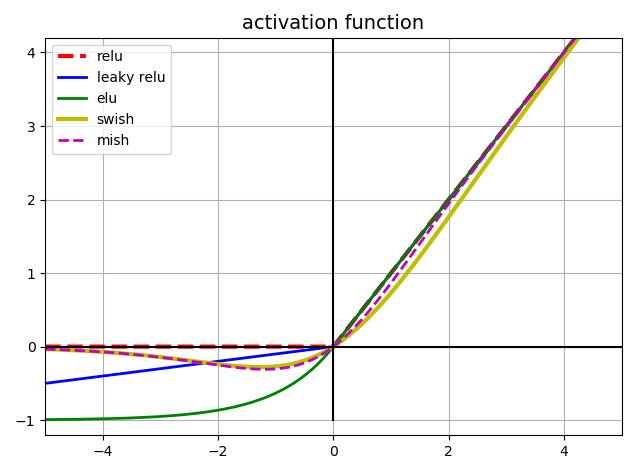
- 0보다 작을 때에도 gradient가 생길 수 있도록 ReLU를 변형한 다양한 활성화 함수들이 소개되었다.
- 그렇다면 음수 부분도 똑같이 y=x로 진행하면 안될까하는 의문이 들 수 있다. - 만약 음수 양수 전체에 걸쳐 y=x 그래프라면, 해당 활성화 함수는 선형 함수이다.
- 즉, 비선형적인 특징을 학습할 수 없으므로 활성화 함수로써의 가치가 없다고 볼 수 있다.
