
데이터 구성
총 4만 건의 예측 시점에서 과거 28일간의 활동 데이터 &
예측 시점 이후 70일간의 관측을 통해 집계된 실제 고객별 이탈 시점(생존 기간) 데이터
* 이탈 여부 판단 기간 7일을 감안하여 64일 동안 이탈하지 않은 유저는 잔존으로 처리
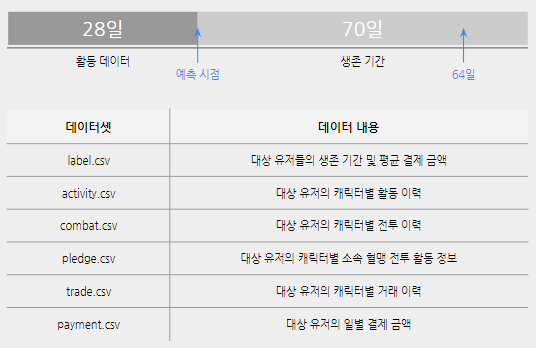
데이터 설명
다시 쓰려니 너무 많아서 그냥 발표자료 만든 ppt 페이지 캡쳐,,
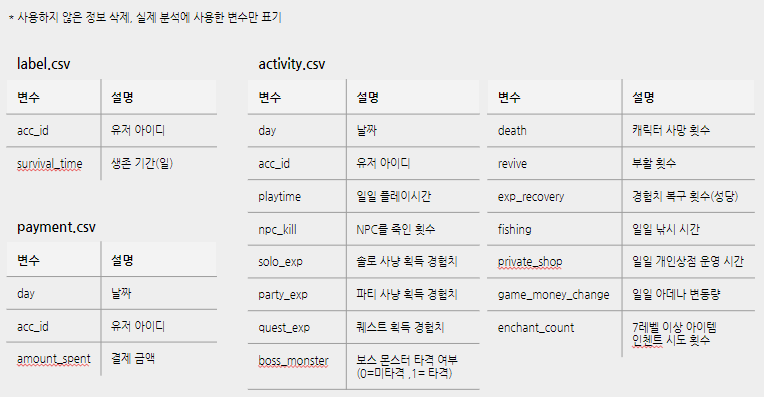
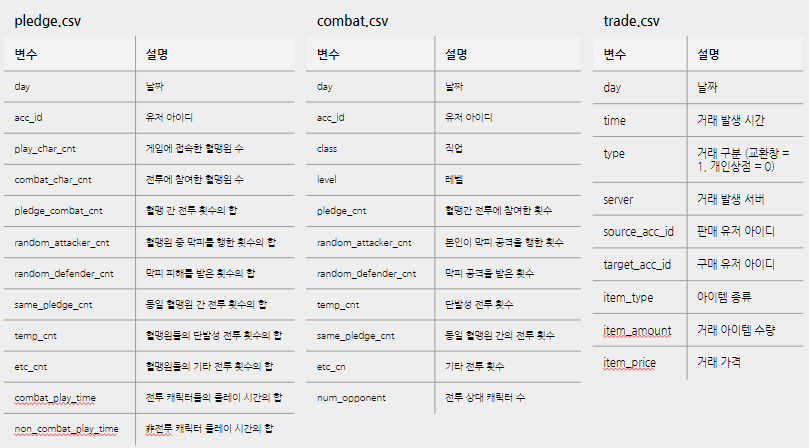
유저가 게임에서 활동한 내역들과 경제활동, 사회생활 등이 포함되어있다고 생각하면 됨.
변수 설정 & 전처리
-
종속변수
: ‘생존 기간(일)’ 컬럼을 이용하여, 63일 이하이면, 0(이탈) / 64일이면, 1(생존)으로 라벨링 -
독립변수
: 상관성 분석을 통해 변수 선택 (근데 최대한 많이 들어가는게 점수는 높게 나옴,, 그래서 대부분의 컬럼들이 들어갔다고 보면 됨)전체 기간 합산 데이터의 경우,
데이터.groupby(‘유저아이디’)[‘컬럼명’, ‘컬럼명’,,,,].sum().reset_index() 데이터.merge(데이터, how=’left’, on=’유저아이디’) 데이터.fillna(0, inplace=True)일자별 데이터의 경우,
데이터.merge(데이터, on= [‘day’,‘유저아이디’], how=’outer’) 데이터.fillna(0, inplace=True)이때 시계열 분석은 진도가 나가지 않아서, 일자별 데이터를 사용한 시계열 분석은 다루지 못함. 그래서 시간의 흐름을 무시하고 전체 기간에 있는 데이터를 합산해서 모델에 돌렸는데 (ex. 전체 기간 동안의 플레이 시간) 점수가 너무 낮아서 일자별로 데이터를 정리해서 다시 돌렸다. 근데 이렇게 해도 되는건진 모르겠음(?)
-
언더샘플링
-
스케일링
