😒 Parquet(파케이)란?!
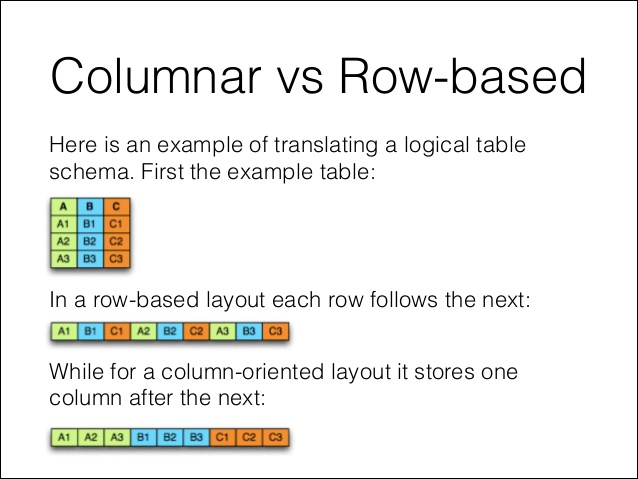
- 컬럼 기반 포맷
- 같은 종류의 데이터가 모여있어 압축률이 더 높고, 일부 컬럼만 읽어 들일 수 있어 처리량을 줄일 수 있다.
- 스파크에서는 parquet 파일을 손쉽게 읽고 쓸 수 있다.
- 데이터를 분석하기 전 json을 읽어 parquet으로 저장해두고 이후에는 parquet에서 데이터를 읽어 처리하는 것만으로도 저장용량과 I/O 면에서 어느 정도의 이득을 얻을 수 있다고 한다.
👍 파케이의 장점
- 압축률: 컬럼 단위로 구성하면 데이터가 더 균일하므로 압축률이 더욱 높아진다.
- 처리량 감소: 전체 컬럼 중 일부 컬럼을 선택해 가져가면 I/O가 줄어든다. 컬럼 단위로 데이터가 저장되어 선택되지 않은 컬럼의 데이터에서는 I/O가 발생하지 않기 때문이다.
- 컬럼에 동일한 데이터 타입이 저장되기 때문에 컬럼 별로 적합한(데이터형에 유리한) 인코딩을 사용할 수 있다.
☝️ 자료형
- 각 필드는 반복자(required, optional, repeated), 자료형, 이름으로 되어 있다.
- 파케이는 기본 문자열 자료형이 없다. 대신 기본 자료형에 대한 해석 방식을 정의한 논리 자료형을 정의한다.
- 논리 자료형을 반복자, 그룹을 사용해 논리적으로 구성한다.
- List, Map을 명세 수준과 반복 수준을 사용해 중첩 구조로 구현한다.
🦋 파일 구조
- 파케이 파일은 헤더, 하나 이상의 블록, 꼬리말 순으로 구성된다.
- 헤더: 파케이 포맷의 파일임을 알려주는 4바이트 매직숫자 (PAR1)
- 꼬리말: 파일의 모든 메타데이터. 포맷버전, 스키마, 추가 키-값 쌍, 파일의 모든 블록에 대한 메타데이터와 같은 정보를 포함
- 블록: 행 그룹을 저장. 행 그룹은 행에 대한 컬럼 데이터를 포함한 컬럼 청크로 되어 있다. 각 컬럼 청크의 데이터는 페이지에 기록된다. 각 페이지는 동일한 컬럼의 값만 포함하고 있으므로 페이지를 압축할 때 매우 유리하다.
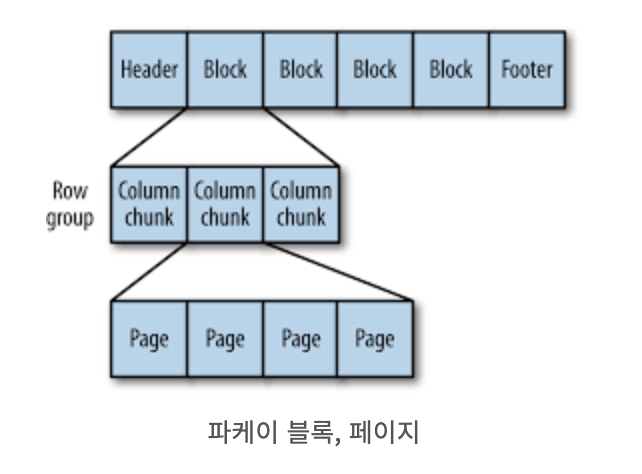
- 페이지: 데이터의 가장 최소 단위인 페이지에는 동일 컬럼의 데이터만 존재한다. 그래서 인코딩/압축을 할 때 페이지 단위로 수행하면 된다.
🙈 파케이 설정
- 블록
- 블록 크기를 설정할 때 스킨 효율성과 메모리 사용률 사이의 트레이드오프 관계를 고려해야 한다.
- 블록의 크기를 높이면 더 많은 행을 가지므로 순차 I/O 성능을 높일 수 있어 효율적으로 스캔할 수 있다.
- 그러나 개별 블록을 읽고 쓸 때 모든 데이터가 메모리에 저장되어야 하기 때문에 너무 큰 블록을 사용하는 것은 한계가 있다.
- 페이지
- 단일 행 검색은 페이지가 작을수록 효율적이다. 원하는 값을 찾기 전에 읽어야 하는 값이 더 적어지기 때문이다.
- 하지만 페이지의 크기가 작으면 필요한 페이지의 수가 늘어남으로써 발생하는 추가적인 메타데이터로 인해 저장 용량과 처리 시간이 증가하는 단점이 있다.
- 사전
- 데이터 인코딩 시에 사용한다. 값의 사전을 만들어 인코딩한 후 사전의 인덱스를 나타내는 정수로 그 값을 저장한다.
- 사전의 크기는 페이지의 크기와 관련이 있다. 한 페이지에 사전이 모두 들어가야 하는데, 페이지 크기보다 사전이 커지면 일반 인코딩(값을 그대로 기록)으로 대체된다.
[출처]

DCDI