✅ 스파크 애플리케이션의 아키텍처
- 스파크 드라이버
- 스파크 애플리케이션의 실행을 제어하고 스파크 클러스터(익스큐터의 상태와 태스크)의 모든 상태 정보를 유지한다.
- 물리적 컴퓨팅 자원 확보와 익스큐터 실행을 위해 클러스터 매니저와 통신할 수 있어야 한다.
- 스파크 익스큐터
- 스파크 드라이버가 할당한 태스크를 수행하는 프로세스
- 드라이버가 할당한 태스크를 받아 실행하고 태스크의 상태와 결과를 드라이버에 보고한다.
- 모든 스파크 애플리케이션은 개별 익스큐터 프로세스를 사용한다.
- 클러스터 매니저
- 스파크 애플리케이션을 실행할 클러스터 머신을 유지한다.
- 프로세스가 아닌 물리적인 머신에 연결되는 개념
- 클러스터 매니저는 '드라이버'와 '워커'라는 개념을 갖고 있다.
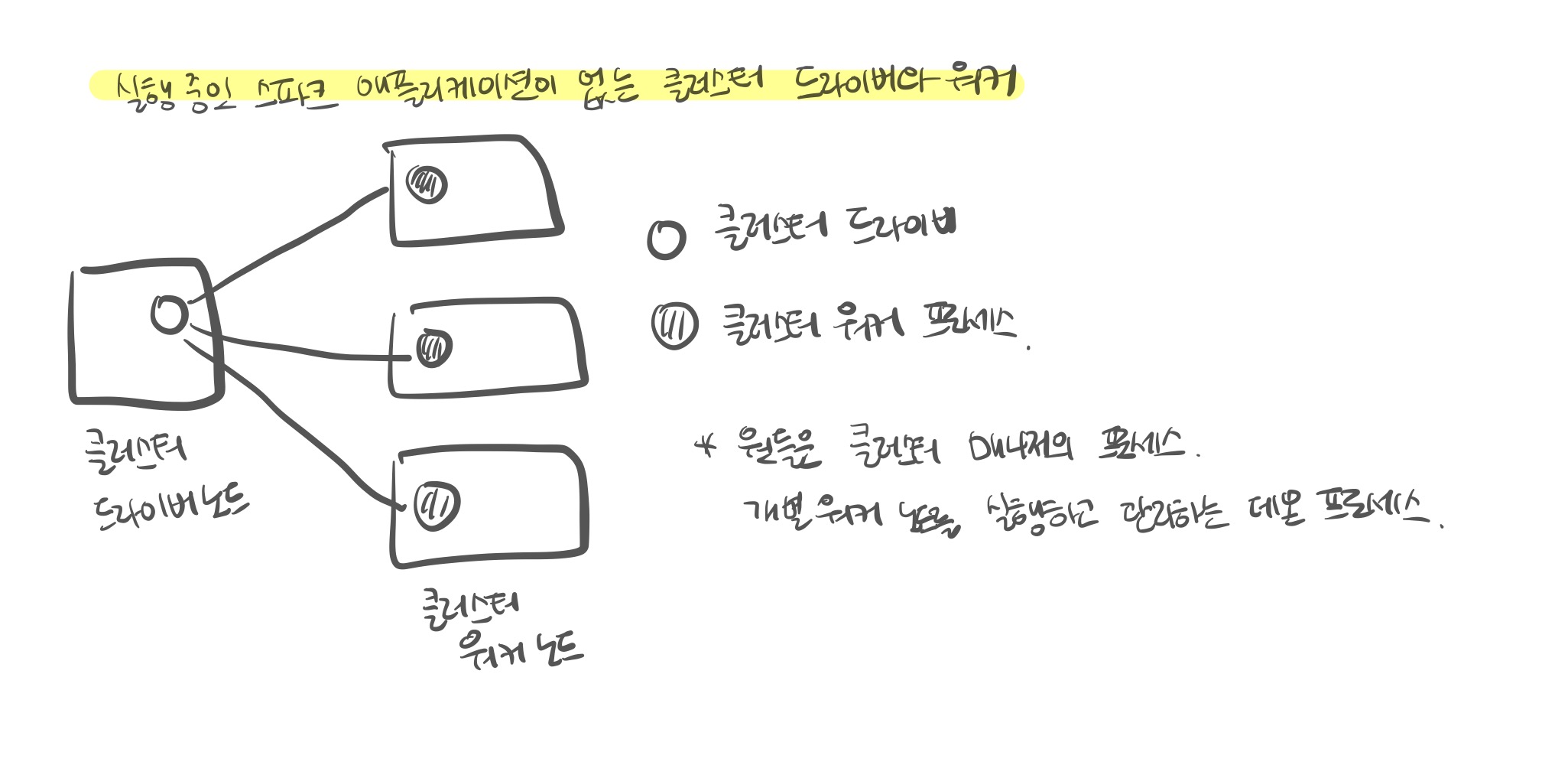
- 스파크 애플리케이션을 실제 실행할 때가 되면 클러스터 매니저에 자원 할당을 요청한다.
- 스파크가 지원하는 클러스터 매니저
- 스탠드얼론 클러스터 매니저
- 아파치 메소스
- 하둡 YARN
✅ 실행 모드
- 애플리케이션을 실행할 대 요청한 자원의 물리적인 위치를 결정한다.
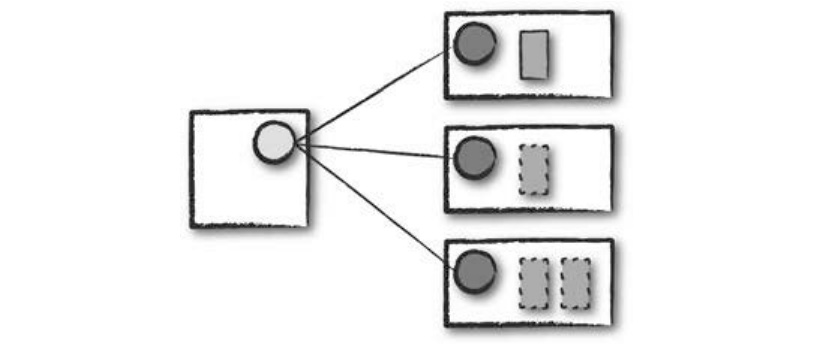
- 클러스터 모드
- 가장 흔하게 사용되는 방식
- 클러스터 매니저는 컴파일된 JAR 파일이나 파이썬 스크립트, R 스크립트를 받은 다음 워커 노드에 드라이버와 익스큐터 프로세스를 실행한다.
- 즉, 클러스터 매니저가 모든 스파크 애플리케이션과 관련된 프로세스를 유지하는 역할을 한다.
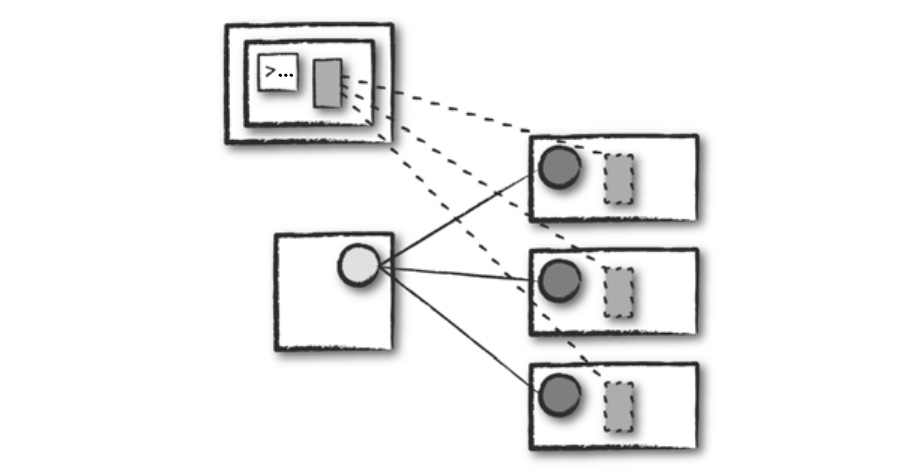
- 클라이언트 모드
- 애플리케이션을 제출한 클라이언트 머신에 스파크 드라이버가 위치한다는 것을 제외하면 클러스터 모드와 비슷하다.
- 클라이언트 머신은 스파크 드라이버 프로세스를 유지하고, 클러스터 매니저는 익스큐터 프로세스를 유지한다.
- 스파크 애플리케이션이 클러스터와 무관한 머신에서 동작하는데, 이런 머신을 게이트웨이 머신 또는 에지 노드라고 부른다.
- 드라이버는 클러스터 외부의 머신에서 실행되며 나머지 워커는 클러스터에 위치한다.
- 로컬 모드
- 단일 머신에서 실행된다.
- 애플리케이션의 병렬 처리를 위해 단일 머신의 스레드를 활용한다.
- 스파크 학습, 애플리케이션 테스트 등에 사용된다.
✅ 스파크 애플리케이션의 생애 주기
☀️스파크 외부☀️
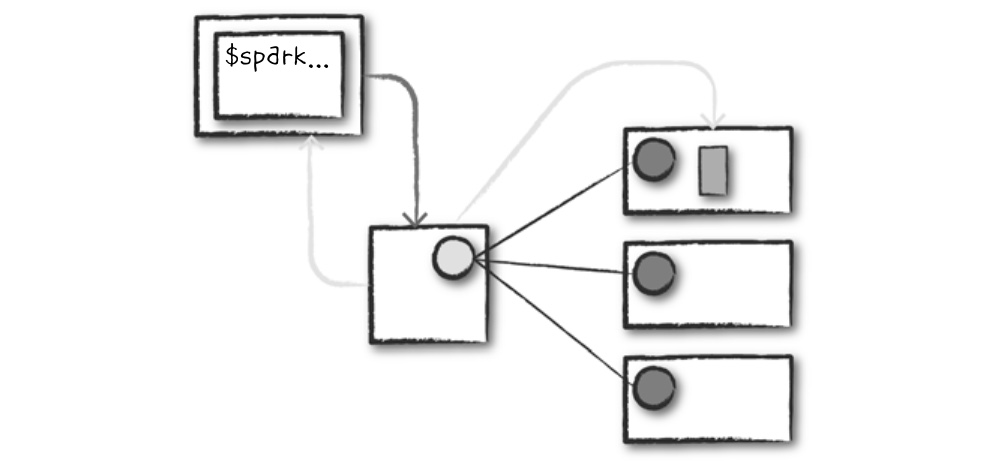
- 하나의 드라이버 노드와 세 개의 워커 노드로 구성된 총 네 대 규모의 클러스터가 이미 실행되고 있다고 가정한다.
- 클라이언트 요청
- 스파크 애플리케이션(컴파일된 JAR나 라이브러리 파일)을 제출한다.
- 스파크 애플리케이션을 제출하는 시점에 로컬 머신에서 코드가 실행되어 클러스터 드라이버 노드에 요청하며, 스파크 드라이버 프로세스의 자원을 함께 요청한다.
- 클러스터 매니저는 요청을 받아들이고 클러스터 노드 중 하나에 드라이버 프로세스를 실행한다.
- 스파크 잡을 제출한 클라이언트 프로세스는 종료되고 애플리케이션은 클러스터에서 실행된다.
- 시작
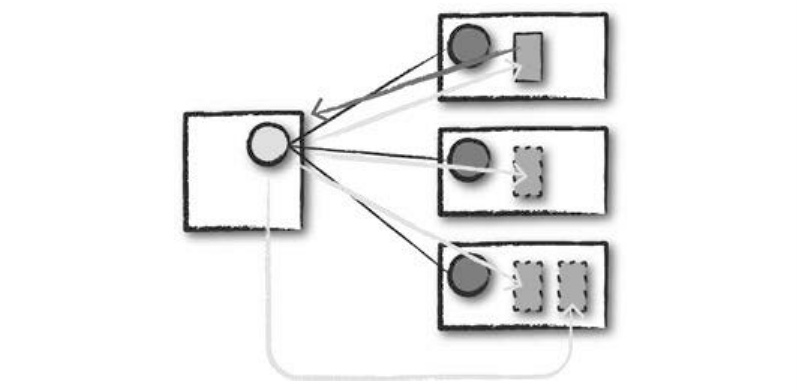
- 드라이버 프로세스가 클러스터에 배치된 뒤에는 사용자 코드를 실행한다.
- 사용자 코드에는 반드시 스파크 클러스터를 초기화하는 SparkSession이 포함되어야 한다.
- SparkSession은 클러스터 매니저와 통신해 스파크 익스큐터 프로세스의 실행을 요청한다.
- 클러스터 매니저는 익스큐터 프로세스를 시작하고 결과를 응답받아 익스큐터의 위치와 관련 정보를 드라이버 프로세스로 전송한다.
- 모든 작업이 정상적으로 완료되면 '스파크 클러스터'가 완성된다.
- 실행
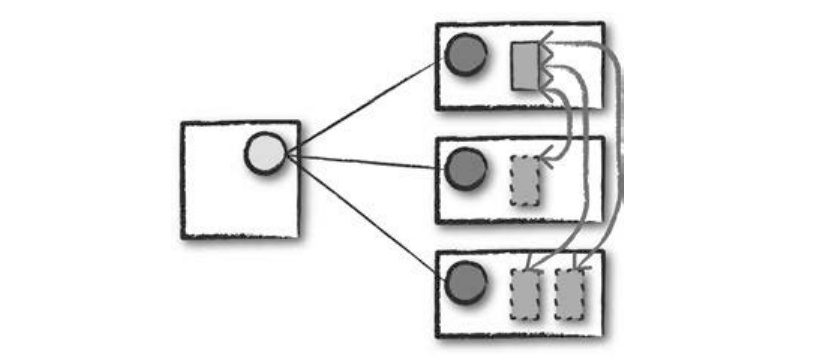
- 코드를 실행한다.
- 드라이버와 워커는 코드를 실행하고 데이터를 이동하는 과정에서 서로 통신한다.
- 드라이버는 각 워커에 태스크를 할당하며, 태스크를 할당 받은 워커는 태스크의 상태와 성공/실패 여부를 드라이버에 전송한다.
- 완료
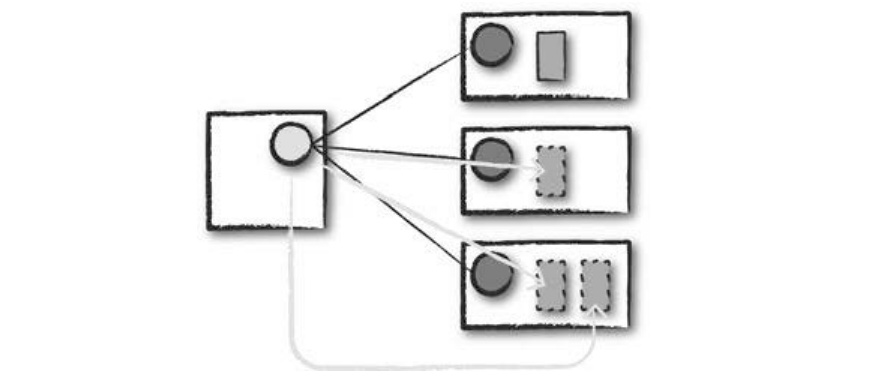
- 드라이버 프로세스가 성공이나 실패 중 하나의 상태로 종료된다.
- 클러스터 매니저는 드라이버가 속한 스파크 클러스터의 모든 익스큐터를 종료시킨다.
- 스파크 애플리케이션의 성공/실패 여부를 클러스터 매니저에 요청해 확인할 수 있다.
☀️스파크 내부☀️
- 스파크 애플리케이션은 하나 이상의 스파크 잡으로 구성되며, 스레드를 사용해 여러 액션을 병렬로 수행하는 경우가 아니라면 애플리케이션의 스파크 잡은 차례대로 실행된다.
-
SparkSession
- 모든 스파크 애플리케이션은 가장 먼저 SparkSession을 생성한다.
- SparkSession을 생성하면 스파크 코드를 실행할 수 있으며, 이를 사용해 모든 저수준 API, 기존 컨텍스트, 관련 설정 정보에 접근할 수 있다.
- SparkSession이 초기화되었다면 코드를 실행한다. 모든 스파크 코드는 RDD 명령으로 컴파일된다.
👉 SparkContext
- 스파크 클러스터에 대한 연결을 나타낸다.
- SparkContext를 이용해 RDD 같은 스파크의 저수준 API를 사용할 수 있다.
-
논리적 명령
- 스파크 코드는 트랜스포메이션과 액션으로 구성된다.
- 논리적 명령은 물리적 실행 계획으로 변환되며, 이를 기반으로 스파크가 클러스터에서 동작한다.
- 액션을 호출하면 개별 스테이지와 태스크로 이루어진 스파크 잡이 실행된다.
-
스파크 잡
- 액션 하나 당 하나의 스파크 잡이 생성되며 액션은 항상 결과를 반환한다.
- 스파크 잡은 일련의 스테이지로 나뉘며 스테이지 수는 셔플 작업이 얼마나 많이 발생하는지에 따라 달라진다.
-
스테이지
- 스테이지는 다수의 머신에서 동일한 연산을 수행하는 태스크의 그룹을 나타낸다.
- 스파크는 가능한 한 많은 태스크(잡의 트랜스포메이션)를 동일한 스테이지로 묶으려 한다.
- 셔플(= 데이터의 물리적 재분배 과정) 작업이 일어난 다음에는 반드시 새로운 스테이지를 시작한다.
- 셔플이 끝난 다음 새로운 스테이지를 시작하며 최종 결과를 계산하기 위해 스테이지 실행 순서를 계속 추적한다.
- 최종 스테이지에서는 드라이버로 결과를 전송하기 전에 파티션마다 개별적으로 수행된 결과를 단일 파티션으로 모으는 작업을 수행한다.
-
태스크
- 스테이지는 태스크로 구성된다.
- 각 태스크는 단일 익스큐터에서 실행할 데이터의 블록과 다수의 트랜스포메이션 조합으로 볼 수 있다.
- 태스크는 데이터 단위(파티션)에 적용되는 연산 단위를 의미하며, 파티션 수를 늘리면 더 높은 병렬성을 얻을 수 있다. (최적화를 위한 가장 간단한 방법)
✅ 세부 실행 과정
☝️ 스테이지와 태스크의 특성
- 스파크는 map 연산 후 다른 map 연산이 이어진다면 함께 실행할 수 있도록 스테이지와 태스크를 자동으로 연결한다. → 파이프라이닝
- 스파크는 모든 셔플을 작업할 때 데이터를 안정적인 저장소(예: 디스크)에 저장하므로 여러 잡에서 재사용할 수 있다. → 셔플 결과 저장
🎋 파이프라이닝
- 스파크는 메모리나 디스크에 데이터를 쓰기 전에 최대한 많은 단계를 수행한다. → '인메모리 컴퓨팅 도구'
- 파이프라이닝 기법은 노드 간의 데이터 이동 없이 각 노드가 데이터를 직접 공급할 수 있는 연산만 모아 태스크의 단일 스테이지로 만든다.
- 따라서 파이프라인으로 구성된 연산 작업은 단계별로 메모리나 디스크에 중간 결과를 기록하는 방식보다 훨씬 더 처리 속도가 빠르다.
- 스파크 런타임에서 파이프라이닝을 자동으로 수행한다.
🔀 셔플 결과 저장
- 스파크가 reduce-buy-key 연산과 같이 노드 간 복제를 유발하는 연산을 실행하면 엔진에서 파이프라인을 수행하지 못하므로 네트워크 셔플이 발생한다.
- 노드 간 복제를 유발하는 연산은 각 키에 대한 입력 데이터를 먼저 여러 노드로부터 복사한다.
- 그리고 소스 태스크의 스테이지가 실행되는 동안 셔플 파일을 로컬 디스크에 기록한다.
- 그 다음 그룹화나 리듀스를 수행하는 스테이지가 시작되는데, 이 스테이지에서는 셔플 파일에서 레코드를 읽어 들인 다음 연산을 수행한다.
- 만약 잡이 실패한 경우 셔플 파일을 디스크에 저장했기 때문에 소스 태스크를 재실행할 필요 없이 해당 스테이지부터 처리할 수 있다.
- 동일한 데이터를 사용해 여러 잡을 실행하는 워크로드의 시간을 절약할 수 있다.
- 더 나은 성능을 얻기 위해 DataFrame이나 RDD의 cache 메서드를 사용할 수 있다.
[출처] 스파크 완벽 가이드 (빌 체임버스, 마테이 자하리아 지음)

DCDI