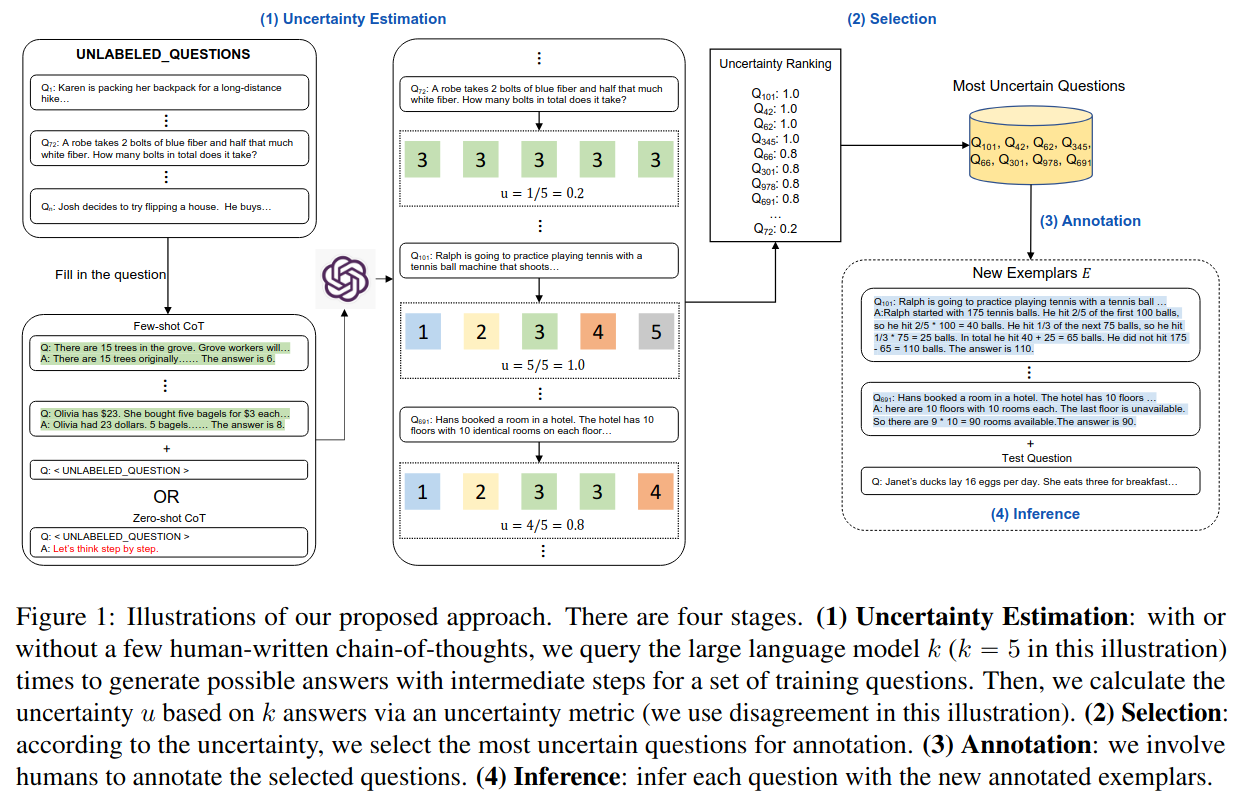
task specific한 질문들 중에서, 어떤 질문들에 annotate하는게 제일 모델에게 도움이 될지 결정하는 방법
구현 방법
- dataset D에서, 모델이 각 질문들을 k 번 답변하게 한다.
- 각 질문에 대한 답변을 모아 불확실성 U를 계산한다. (이때 불확실성은 답변의 일치도를 바탕으로 계산한다. 5번 질문했는데 5번 다 답이 다르면 5/5, 다 같으면 1/5, 2개는 같고 3개는 다르면 4/5로 계산한다.)
- 불확실성 U를 기준으로, 모델이 가장 불확실한 답변을 내놓은 n개의 질문을 뽑고, oracle(사람)에게 질문에 대한 CoT해설을 생성하도록 한다.
- 3번의 해설들을 프롬프트에 추가한다.
Contributions
- 가장 해설을 덧붙이면 성능에 도움 될만한 문제들을 뽑음 -> 어떻게? 불확실성 metric 제작
불확실성 metric 실험한 방식들- disagreement: 구현방법에서 설명한 방법. 답변 일치도로 계산.
- self-confidence: 답변들을 reorganize한다음, 새로운 템플릿을 이용해서 모델에게 답변들의 confidence를 물음 -> LLM의 overconfidence로 제대로 작동하지 않음.
- entropy & variance: disagreement와 유사하게 잘 작동함. 작동방식은 아래서 설명할 것.
결론적으로 사용한 불확실성 metric
-
disagreement : h는 unique한 아이템 개수, k는 답변 수

-
entropy : 모델 Pθ가 각 질문 qi에 대해 각 가능한 답변 aj의 확률을 예측하며, 그 불확실성을 로그 함수 ln을 통해 가중 합산하여 계산
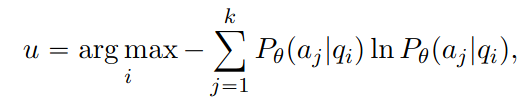
-
variance : 수학 문제에서는 각 답변의 분산을 계산함.
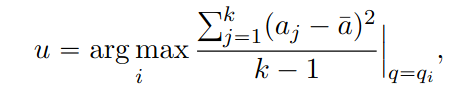
결과
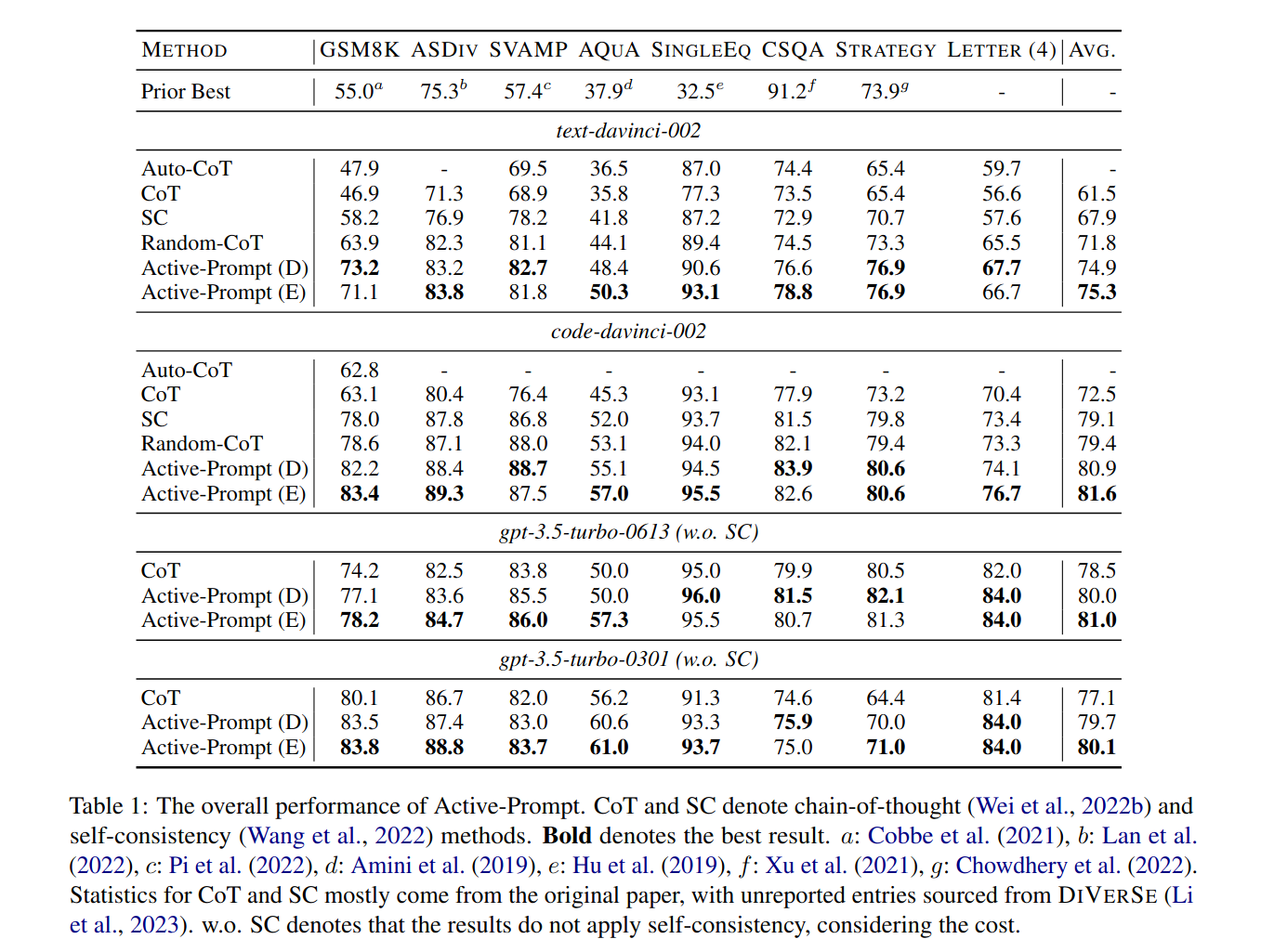
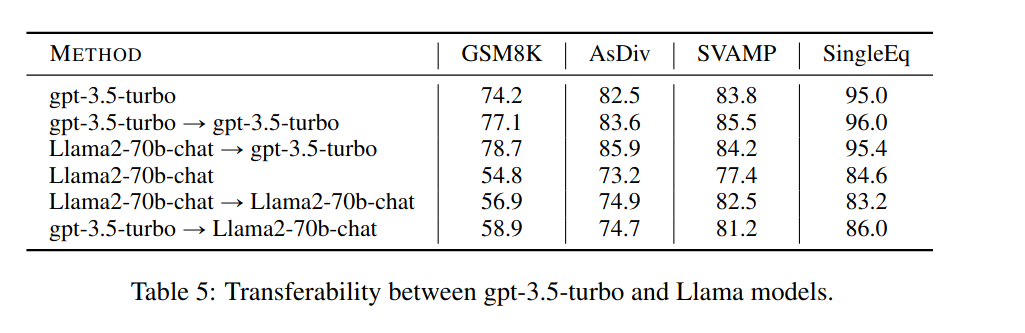
간단한 산술 문제(초등학생 수준), 일반 상식, 전략적 추론, 비유&유사성 활용, 영어 문자와 관련하여 특정 패턴이나 구조를 이해하는지에 대한 데이터셋으로 실험해본 결과, baseline은 물론이고 일반 CoT보다 나은 성능을 보임.여기서 Active-Prompt(D)는 disagreement, E는 entropy를 사용한 것을 의미함.
실험에서는 랜덤으로 문제를 골라 같은 갯수의 답변을 뽑는 것보다 논문에서 제시한 불확실성 Metric으로 문제를 뽑는 것이 더 효과적인 것을 보임.
또한, 실험에서는 불확실성을 계산할 답변을 생성하는 과정에서 CoT 예시를 주었는데, Think step by step 정도의 CoT 프롬프트를 주어도 효과적임.
Active-Prompt-Anno(A)와 (B)는 서로 다른 human anotator 해설들을 사용했는데, 결과가 다르게 나옴. Active-Prompting을 할 때 해설할 문제를 고르는 것도 중요하지만, 해설도 중요하다는 것을 보여줌.
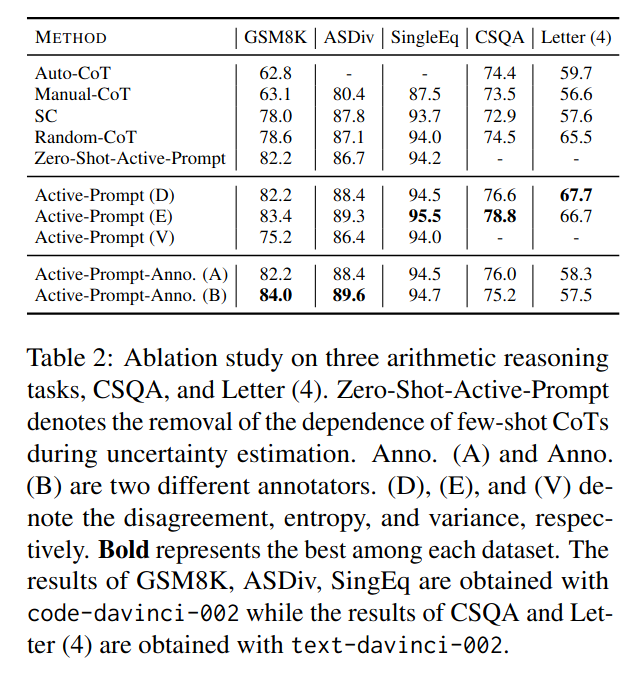
k개의 답변을 생성하여 불확실성 U를 계산하는데, k개의 개수가 올라갈 수록 성능이 올라감. -> 더 의미있는 문제들을 뽑음.
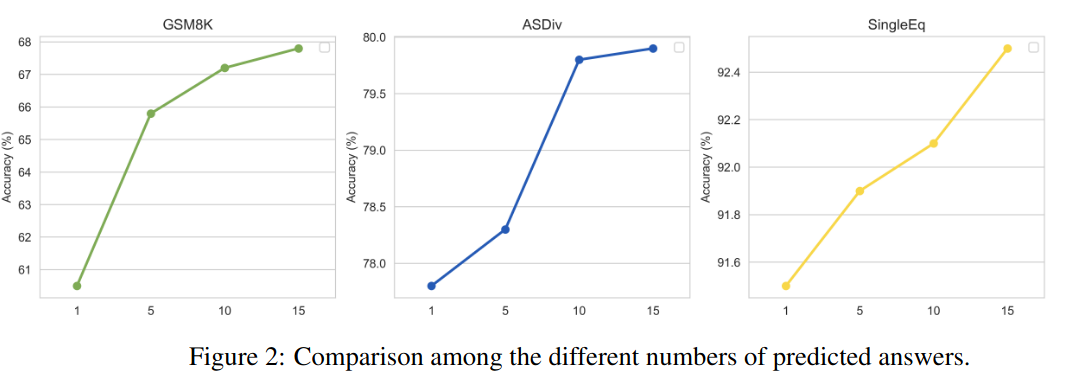
비교적 약한 모델에서도 Active prompt가 효과적이라는 것을 알 수 있음.
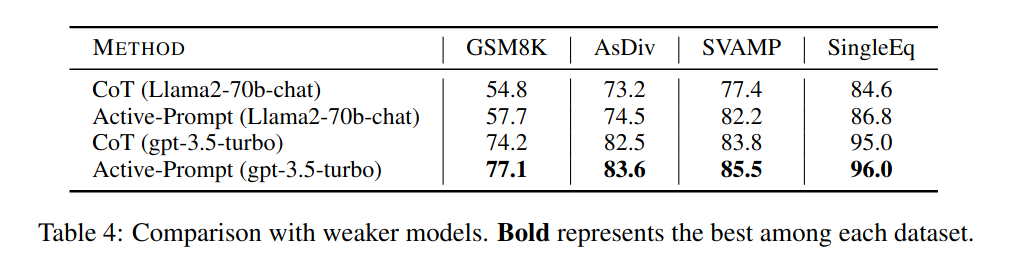
강한 모델로 질문을 고르고, 약한 모델로 inference하면 약한 모델의 성능이 올라감! 근데 gpt-3.5-turbo랑 gpt-3.5-turbo-> gpt-3.5-turbo의 차이는 뭐지?
의의
그동안 나온 CoT는 복잡한 task에는 잘 적용했지만 다양한 task에 적용할 수 없다는 문제가 있었다. 이거는 다양한 task에 쉽게 적용할 수 있다는 장점을 지님.
