LLM논문리뷰
1.Active Prompting with Chain-of-Thought for Large Language Model
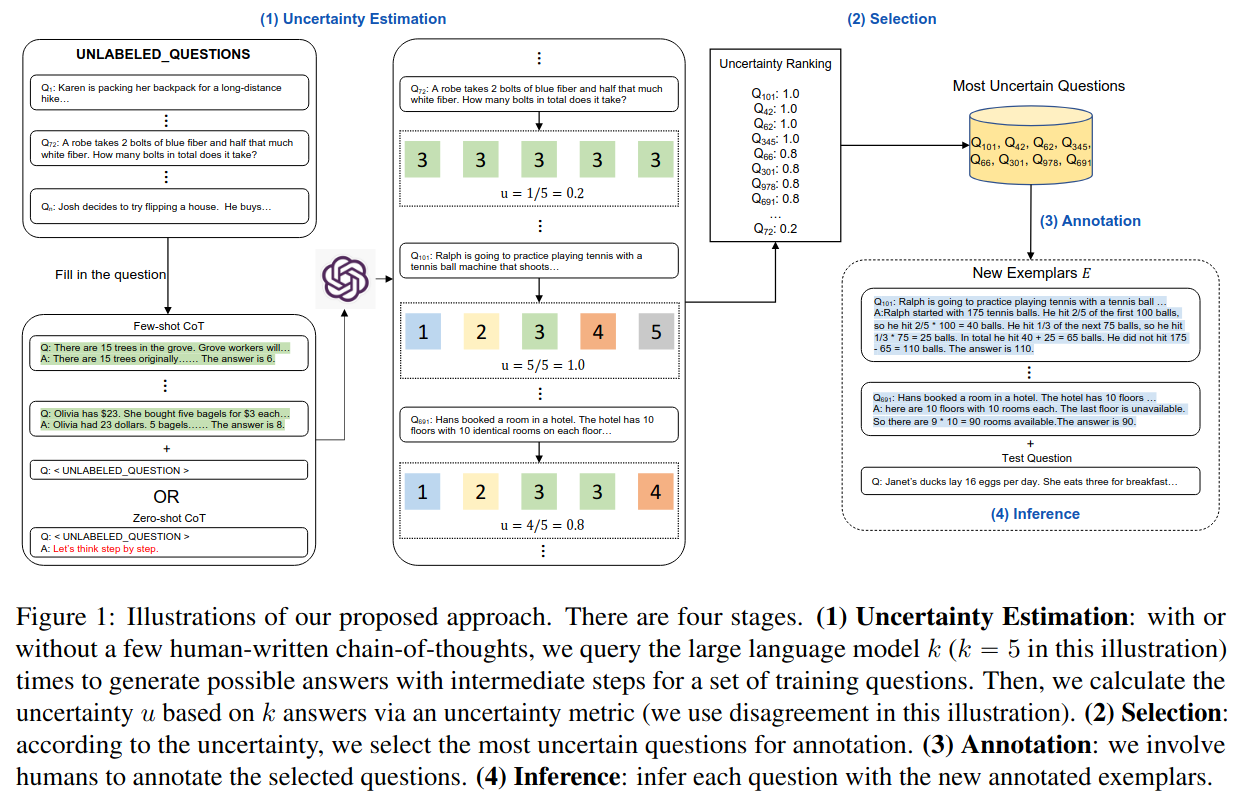
task specific한 질문들 중에서, 어떤 질문들에 annotate하는게 제일 모델에게 도움이 될지 결정하는 방법dataset D에서, 모델이 각 질문들을 k 번 답변하게 한다.각 질문에 대한 답변을 모아 불확실성 U를 계산한다. (이때 불확실성은 답변의 일치도를
2.Prompting Contrastive Explanations for Commonsense Reasoning Tasks
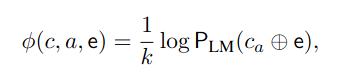
Contrastive Explanation이 뭘까? > Why P rather then Q?에 대한 설명이다. 이를 프롬프트에 추가하여, 모델이 더 정확한 결과를 내는지 검증하는 게 이 논문의 주요 요지이다. 작동하는 방식 Explainer P_LM generate
3.Chain-of-Thought Reasoning without Prompting
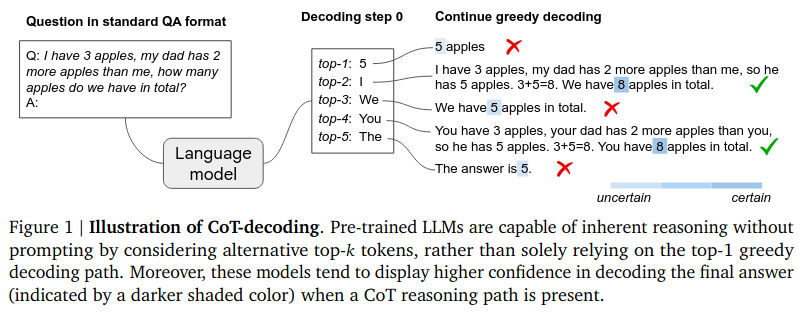
기존에 LLM은 greedy decoding이라고, 가장 높은 확률을 가지는 단어를 바로바로 다음 단어로 생성해버리는 방식으로 동작하였다.이것의 문제점은 모델이 고민할 여지를 안주는 것이다. 즉, 아래 예시에 보듯이 정답은 8임에도 불구하고 5 apples이 가장 확률
4.Retrieval-Augmented Generation for Large Language Models: A Survey

Modular Rag Naive RAG 또는 Advanced RAG의 더 고정된 구조와 달리, Modular RAG는 모듈 교체 및 재구성을 허용합니다. 이는 시스템의 다양한 구성 요소(Retriever, Generator, Search Module 등)을 독립적으로
5.Direct Preference Optimization: Your Language Model is Secretly a Reward Model
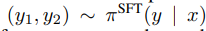
LLM에 강화학습을 왜 해야할까? 모델은 코딩 실수를 이해하지만 답변할 때는 실수를 하면 안되며, 잘못된 상식이라는 것을 인식해야 되지만 답변할 때는 올바른 상식만을 얘기해야한다. SFT는 인간이 제공한 데이터에서만 학습하기 때문에 특정 응답에 대한 세부 선호도를 반영
6.ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search
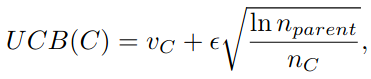
배경 언어 모델은 아이유의 엄마는 누구인가? 와 같은 질문에는 답을 잘하지만, ‘분홍신’을 부른 가수의 엄마는 누구인가? 와 같이 다양한 정보를 조합하여 추론해야 하는 질문에는 답변을 못한다. 모델의 크기와 관계없이! 그렇다면 어떻게 하면 모델이 추론(reasoni
7.MATH-SHEPHERD: VERIFY AND REINFORCE LLMS STEP-BY-STEP WITHOUT HUMAN ANNOTATIONS
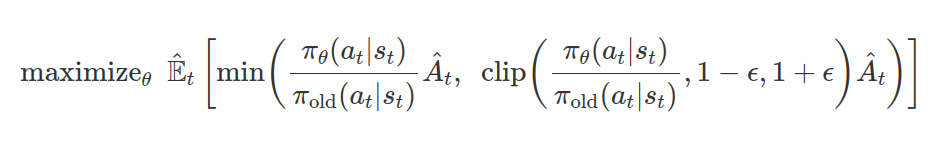
이 논문은 수학 문제 풀이 과정 채점해주는 PRM(progress reward model)모델 MATH-SHEPARD 제작기를 다루고 있다. 특히, human-annotated 데이터셋 없이 LLM을 이용해 PRM을 훈련시킬 데이터를 만든 과정을 설명한다. 복잡한 수학