Contrastive Explanation이 뭘까?
Why P rather then Q?에 대한 설명이다.
이를 프롬프트에 추가하여, 모델이 더 정확한 결과를 내는지 검증하는 게 이 논문의 주요 요지이다.
작동하는 방식
-
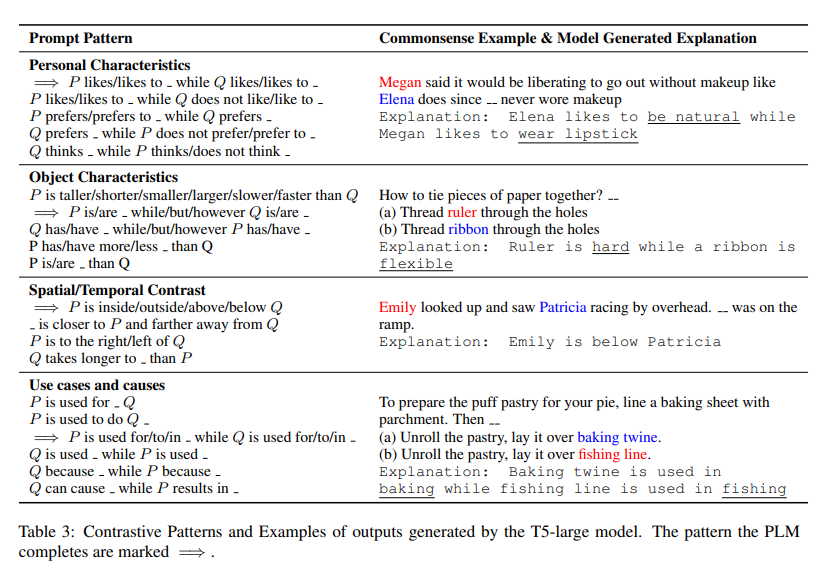
Explainer P_LM generates contrastive explanations by infilling present contrastive templates.
여기서 템플릿은 "P are --- while Q are ---" 아 주로 쓰인다. 이 빈칸을 채워넣는게 Explainer P_LM의 역할인 것이다.
-
Task Model P_LM selects the correct answer conditioned on both the context and the generated explanations.
컨텍스트와 1번에서 만들어진 설명을 바탕으로 올바른 답변을 고른다.

Task Model
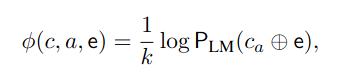
c는 문맥(context)을 나타낸다. ca는 문맥 c에 답변 a를 삽입한 형태이고, e는 설명이다.
PLM은 주어진 문맥과 답변을 설명과 함께 입력으로 받아 해당 문자열의 확률을 계산하는 언어 모델이다. 이 점수 ϕ는 문맥과 답변, 설명이 잘 맞아떨어질수록 높은 값을 가지며, 이를 사용해 이진 분류기(여기서는 로지스틱 회귀 모델)에 입력으로 제공된다. 로지스틱 회귀 모델은 이 점수들을 사용해 답변들 a 중 어느 것이 더 적절한지 판별한다.
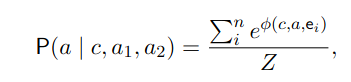
이후에 이 모든 경우의 수에 대한 점수를 합산하여 a가 답변으로 선택될 확률을 계산한다.
여기서 language model ϕ은 정답에 대한 cross entropy loss를 제일 줄이기 위해 fine-tuning되지만, decoder P_LM은 top-k beam decoding 방식(생성된 텍스트 중 가장 높은 확률을 가진 K개의 후보를 유지하면서 다음 단어를 생성하는 기법)을 적용하므로 역전파로 훈련시키기 어려우므로 훈련을 안한다고 한다!
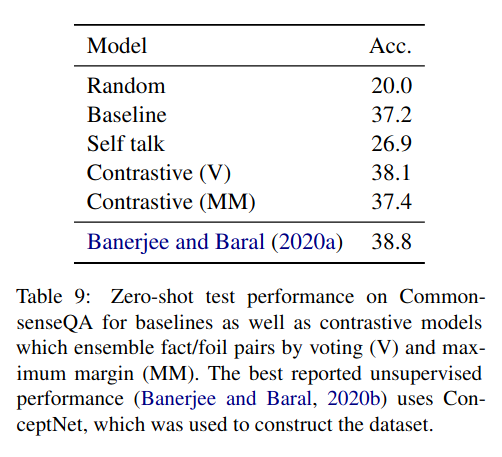
결과
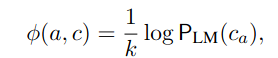
이렇게 설명이 없는 것보다 점수가 높게 나옴.
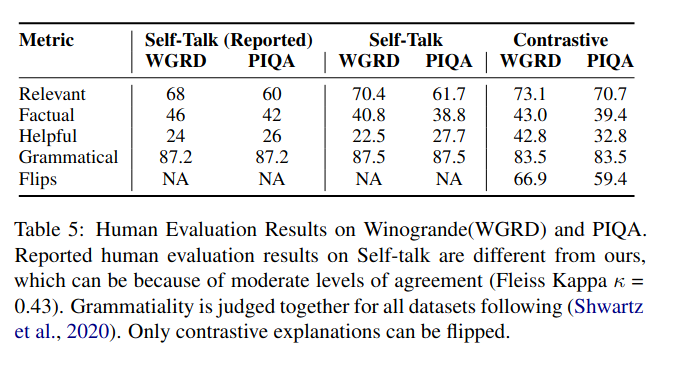
self-talk를 적용한 것보다 점수가 높게 나옴.
self-talk란?
1) completing clarification question prefixes such as “what is the definition of ...” conditioned on input context,
2) generating their corresponding answers (clarifications), and
3) conditioning on the clarification questions and answers to make prediction.
다만 상식문제와 같은 간단한 문제에서만 통할듯... 수학문제나 객관식 문제에서는 어떻게 프롬프팅할지도 문제임.
기타...