Traditional Rag

1) Indexing: 정제되지 않은 데이터를 plain text로 바꾼 뒤, 더 작은 text chunk로 나눠 임베딩을 진행한다.
2) Retrival: 사용자의 쿼리를 벡터로 임베딩 한 뒤, 이 벡터와 위에서 임베딩 한 정보의 코사인 유사도가 높은 k개의 text chunk를 가져온다.
3) Generation: 쿼리 + 가져온 정보들을 prompt로 만들어 LLM의 response를 만드는 데 사용한다.
단점
retrieval challenges: 주게와 맞지 않거나 상관이 없는 데이터를 가져온다. 오로지 코사인 유사도를 기준으로 하기 때문에... 예를 들어, 자동차 엔진이 고장났어. 에 대한 해결책은 잘 찾지만, 여행계획을 짜줘- 와 같은 두리뭉실한 질문은 코사인 유사도로 가져오기 어려울 듯 하다.
generation difficulties: hallucination. retrieve된 context를 막상 대답할 때는 사용하지 않는다!
Augmentation hurdles: retrieve된 정보를 다양한 task와 결합하는 데 어려움을 겪는다. 반복되는 retrieve한 정보 사이에서 같은 말을 반복하는 답변을 할 수도 있다. 또한, 딱 한번 retrieve하기에 정보의 부족함이 있을 수도 있다.
또한, retrieve 한 정보에 추가적으로 정보를 제시하지 않고, 앵무새처럼 반복한다는 단점도 있다. 이러면 그냥 구글을 쓰지 왜 검색을 하나!
Advanced Rag
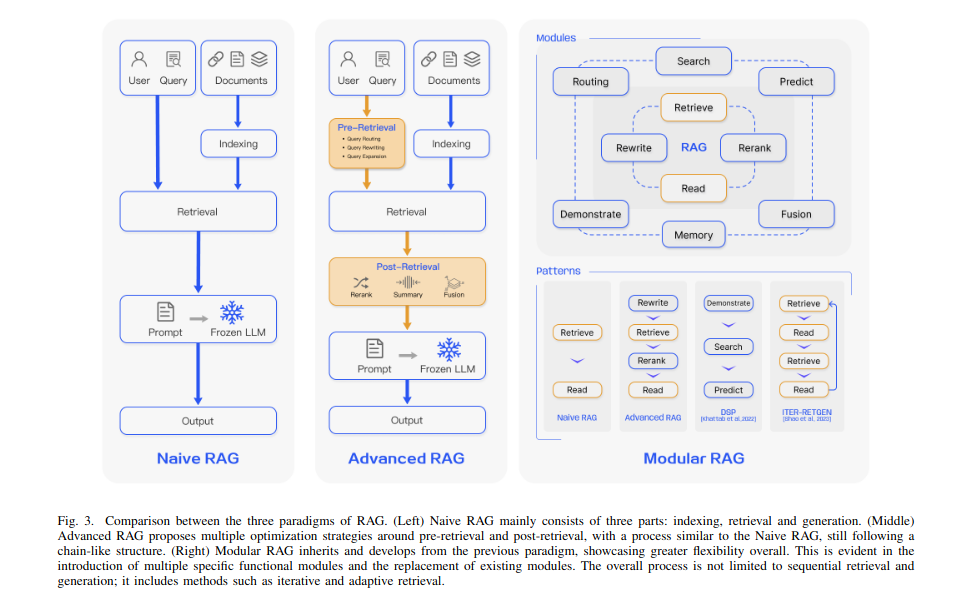
retrieval 퀄리티를 발전시키기 위해서, pre-retrieval과 post-retrieval 전략을 사용한다.
Pre-retrieval
enhancing data granularity: 데이터를 더 작은 단위로 만들어, retrieval 가 더 섬세한 디테일들과 일할 수 있게 한다.
Optimizing index structures: Indexing, 즉 관련있는 정보를 더 잘 retrieve하기 위해 데이터를 잘 정리한다. 여기서는 그냥 스치듯이 언급되지만, modular rag에서는 Knowledge Graph가 나오면서 더 자세히 언급된다.
Adding Metadata: 데이터에 추가적인 정보( 태그, 키워드, 타임스탬프, 작가, ...) 를 넣어 targeted filtering을 가능하게 한다.
Alignment Optimization: retrieve data가 유저의 질문과 연관이 있는지 확인한다. 여기서는 어떻게 하는지 안나오지만, BERT와 같은 언어모델을 사용할 수도 있고, BM25와 같은 평가기준을 사용할 수도 있다.
Mixed retrieval: 여러가지 retrieval technique를 쓴다. keyword-based + semantic retrieval... (결국 메타데이터로 필터링 후 코사인 유사도 돌린다는 거 아닌가?)
Post-retrieval
연관됐다고 생각되는 데이터가 retrieve된 후, query와 효과적으로 합쳐져야 한다.(주요 전략: rerank(중요한 텍스트를 prompt 앞에 둔다) + context compressing) 필수적인 정보를 골라내고, 중요한 섹션을 강조하고, 정보를 요약하고(짧게하고).. 랭체인에 구현되었다고 한다.
Modular Rag
고정된 구조의 Naive RAG 또는 Advanced RAG와 달리, Modular RAG는 모듈 교체 및 재구성을 허용한다. 이는 시스템의 다양한 구성 요소(Retriever, Generator, Search Module 등)을 독립적으로 교체, 최적화 할 수 있다는 것이다.
RAG vs. Finetuning
RAG는 정보가 지속적으로 변화하는 동적인 환경에서, 외부 정보를 효과적으로 활용할 수 있다는 장점을 가지고 있다. 반면, 파인튜닝은 더 정적인 환경에 적합하며, 정보를 업데이트하려면 재학습이 필요하지만 모델의 스타일이나 행동을 맞춤화할 수 있다는 이점이 있다.
Knowledge-intensive 분야에서는 RAG가 비지도 학습 기반 파인튜닝보다 더 좋은 성능을 발휘한다. LLM은 비지도 파인튜닝만으로는 새로운 정보를 학습하는 데 한계가 있다는 연구결과가 있다. (그러면 Instruction tuning은?)
Retrieval
RAG는 쿼리와 연관된 데이터를 데이터소스로부터 효율적으로 가져오는 것이 중요하다. 데이터를 어디에서 가져오는지, 데이터를 얼마나 세부적으로 쪼갤지, 검색을 위한 전처리 과정,그리고 embedding model의 종류에 따라 RAG의 성능이 달라진다.
A. Retrieval
1) Data Structure
비정형 데이터인 텍스트가 데이터로서 가장 많이 활용된다. 그러나 최근에는 텍스트와 테이블이 조합된 반정형 데이터와 정형 데이터 또한 점점 많아지고 있다. 반정형 데이터는 청킹할때 테이블이 분리되면 아예 의미가 왜곡되거나, 의미적으로 유사한 검색이 어려워진다. 이때는 쿼리를 SQL언어로 바꾸어 retrieval을 실행하거나, 테이블을 아예 텍스트로 변환하는 방법을 사용할 수도 있다. 반면에 Knowledge Graph(KG)는 정보가 분산되어 있는 경우, 잘못됐거나 부족한 데이터를 retrieve할 수 있는 경우를 인지하여 node와 edge로 데이터를 구조화하여 다양한 곳에 분산되어 있는 정보를 통합해 정확한 답변을 할 수 있게 했다.
외부 정보에는 한계가 있기 때문에, LLM에 내재되어 있는 정보에 집중하기도 했다. SKR은 질문을 "알고 있는 질문" "모르는 질문"으로 분류하여 검색을 선택적으로 실시했다. GenREAD는 검색을 LLM 생성기로 대체하여, 참고할 논문을 검색하기보다 직접 생성하는 쪽을 택했다. 불필요한 정보, 모델이 학습된 결과 맞지 않는 정보를 검색하는 RAG와 달리 이미 충분한 데이터의 양으로 학습된 LLM의 성능을 신뢰하는 것이다. Selfmem은 모델이 답변을 생성하고 이를 메모리 풀에 저장한 다음, 원래 질문과 상호 보완적인 문제로 작용할 수 있는 메모리 항목을 선택하여 점진적으로 답변을 개선한다.
2) Retrieval Granularity
데이터를 얼마나 세분화할 것인지도 중요하다. 큰 단위의 검색은 이론적으로 문제 해결에 더 관련성 있는 정보를 제공할 수 있지만, 동시에 불필요한 내용이 포함되어 LLM이 후속 작업에서 혼란을 겪을 수 있다. 반면에 세밀한 단위의 검색은 의미적 완전성을 보장하지 못하거나 답변 시 필요한 지식을 충족시키지 못할 수도 있다.
B.Indexing Optimization
인덱싱 단계에서는 데이터가 가공, 분할, 임베딩되어 벡터 데이터베이스에 저장된다.
1)Chunking Strategy
가장 흔한 방법은 고정된 단위로 데이터를 분할하는 것이다. 단위가 클수록 더 많은 정보가 담기지만, 노이즈도 커집니다. 반대로 작을수록 노이즈가 작아지지만, 필요한 정보가 담기지 않을 수도 있다. Chunking의 가장 큰 문제는 문맥이 중간에 짤릴 수도 있다는 것이다. 이를 해결하기 위해 재귀적 분할(우선 문단, 문장 별로 분할할 뒤 다시 나누는것) sliding window method를 활용하지만, 완벽한 해결책은 아니다.
2)Metadata Attachments
Chunk들에 파일 이름, 작가, 카테고리 등 metadata를 추가할 수 있고, 이를 토대로 검색 시 필터링을 진행 할 수 있다. 또한 타임스탬프에 weight를 부과하여 최신자료를 우선적으로 내보내는 등의 작업도 가능하다.
3)Structural Index
검색을 더 효율적이게 하는 한가지 방법은 데이터 간의 계층적 구조를 구축하는 것이다. 부모-자식 관계의 노드나 Knowledge Graph의 인덱스가 그 예시입니다.
C.Query Optimization
Naive RAG의 한가지 문제점은 사용자의 질문만을 기반으로 데이터 검색에 수행한다는 것이다. 그러나, 좋은 질문은 하기가 어렵다! 명확하고 간결한 질문은 만드는 것은 어렵고, 질문 그 자체가 불명확하거나 복잡한 경우, 시스템이 적절한 데이터를 찾기 힘들어질 수 있다.
1)Query Expansion
Multi query는 원본 질문을 여러개의 하위 질문으로 확장한 뒤,이를 병렬적으로 수행하는 방식이다. Sub query는 하나의 복잡한 질문을 다양한 작은 질문들로 나누는 것이다. CoVe란 질문을 확장한 후 LLM을 통해 검증을 수행하는 방식이다.
2)Query Transformation
Query rewrite: 사용자가 작성한 쿼리를 LLM에 더 적합한 형태로 재작성함으로써 검색의 정확성과 효율적을 높일 수 있다. RRR(Rewrite-Retrieve-Read)는 LLM이 아닌 작은 언어 모델을 사용하여 쿼리를 재작성 한 후 검색을 수행하는 방법이다. BEQUE는 타오바오에서 사용된 쿼리 재작성 방법으로, 타오바오는 이 방식을 사용해 롱테일 쿼리(즉, 자주 사용되지 않거나 특이한 쿼리)에서 검색 성능을 크게 향상시켰다. HyDE는 가설적 문서를 생성하는 기법으로, 이 방법은 사용자가 입력한 원래 쿼리에 대해 가상의 답변은 생성하고, 그 답변의 임베딩을 기반으로 검색을 했다. Step-back prompting에서는 원래 쿼리와 연관된 상위 개념의 질문을 먼저 생성한 후, 이를 기반으로 원래 쿼리와 함께 답변을 생성하는 방식이다.
Query Routing:사용자가 입력한 쿼리를 다양한 RAG 파이프라인 중 하나로 분배하는 작업이다. 즉, 입력된 쿼리의 종류나 특성에 맞는 파이프라인으로 쿼리를 보내어 가장 적합한 방식으로 처리하도록 하는 것이다.
Metadata Router은 쿼리의 키워드를 추출하고, 추출된 키워드와 데이터 청크의 메타데이터를 비교하여 검색 범위를 좁히는 과정이다. Semantic Router는 그와 반대로, 쿼리의 의미를 기반으로 찾는 방식이다. Hybrid Routing은 둘 다 이용하는데, 쿼리의 키워드와 메타데이터를 이용해 검색 범위를 좁히고 의미적 정보를 활용하여 찾는다.
D.Embedding
RAG는 질문의 임베딩과 정보의 임베딩 간의 코사인유사도로 어떤 정보를 가져올지 결정한다. 이때, 임베딩 모델이 얼마나 글의 의미를 포착하는지가 중요하다. 주로 sparse 인코더(BM25/ 키워드 검색)와 dense 인코더(BERT) 가 사용되는데, 그 외에도 다양한 임베딩 모델이 사용된다.
1) Mix/hybrid Retrieval
Sparse 임베딩과 Dense 임베딩은 서로 다른 특징들을 포착하고, 이는 서로를 보완하기 위해 사용될 수 있다. 예를 들어, sparse 검색 모델이 일차적으로 검색하고, 그 검색 결과를 바탕으로 dense 검색 모델이 코사인 유사도 검색을 진행할 수 있습니다. 또는 pre-training language models(PLMs)은 단어 가중치를 학습하는 사용되어, 검색 문맥에서 특정 단어나 구에 더 많은 중요도를 부여할 수 있다. 이렇게 하면 sparse 검색 모델이 쿼리 내 용어의 중요성에 따라 관련 문서를 더 잘 식별할 수 있다.
2) Fine-tuning Embedding Model
의료, 법률 등 잘 사용되지 않는 용어들이 포함된 분야는 모델이 사전 학습된 코퍼스와 크게 다를 수 있다. 이러한 차이를 줄이기 위해, 해단 분야의 자체 데이터셋으로 임베딩 모델을 파인 튜닝하는 것이 좋다.
E. Adapter
모델을 파인 튜닝할 때 API를 통한 기능 통합이나, 제한된 컴퓨팅 자원을 이용하는데서 오는 제약이 생길 수 있습니다. 그러므로, 외부적인 adapter를 도입해 문제를 해결할 수 있습니다. LLM의 멀티태스킹 기능을 최적화하기 위해, UPRISE는 가벼운 프롬프트 검색기를 훈련하여 사전 구축된 프롬프트 풀에서 주어진 제로샷 작업 입력에 적합한 프롬프트를 자동으로 검색할 수 있게 했습니다.
Generation
검색 후에 나온 모든 정보를 LLM에 넣는 것은 좋은 방법이 아니다. 검색된 컨텐츠의 조정과, LLM을 조정하는 방법이 있다.
A. Context Curation
중복된 정보는 LLM의 최종 생성 과정에 방해가 될 수 있으며, 지나치게 긴 문맥은 모델이 중간 부분을 잊어버리는 문제가 생길 수 있다. 인간과 마찬가지로, LLM도 긴 텍스트의 처음과 끝 부분에만 집중하고 중간 부분을 잊어버리는 경향이 있다. 따라서 RAG 시스템에서는 검색된 콘텐츠를 추가로 처리할 필요가 있습니다.
1) reranking
가져온 정보를 다시 정렬함으로서 가장 관련성이 높은 부분을 먼저 강조한다. 이때, 정렬하는 규칙은 Diversity, relevance, MRR과 같은 지표에 따르거나 BERT의 인코더-디코더 규칙에 따를 수도 있다.
2) Context Selection/Compression
너무 많은 정보는 오히려 LLM 모델에게 혼란을 야기할 수 있다. 이때, sLM을 이용해 필요 없다고 느끼는 토큰을 제거하여, 인간은 이해하기 어렵지만 LLM은 이해하기 쉬운 정보로 압축할 수 있습니다. 또한, 정보의 양을 줄이는 것도 도움이 된다. sLM이 먼저 관련없는 정보를 필터링 한다음, LLM을 이용해 reranking을 진행하는 것입니다. 또는 LLM이 제공된 정보를 평가하여 관련없는 정보를 필터링하는 방법도 있다.
B. Fine-tuning
모델을 파인튜닝하면, 도메인에 대한 추가적인 정보를 제공하고 주어진 형식으로 답변하도록 학습시킬 수 있다.
강화학습을 통해 LLM의 출력을 인간의 선호도에 맞게 학습시킬 수도 있다.
Augmentation Process in RAG
RAG 분야에서는 일반적으로 한 번의 검색 단계를 거친 후 생성이 이루어지는 방식이 사용된다. 이는 비효율적일 수 있으며, 다단계 추론을 요구하는 복잡한 문제에는 보통 충분하지 않다.
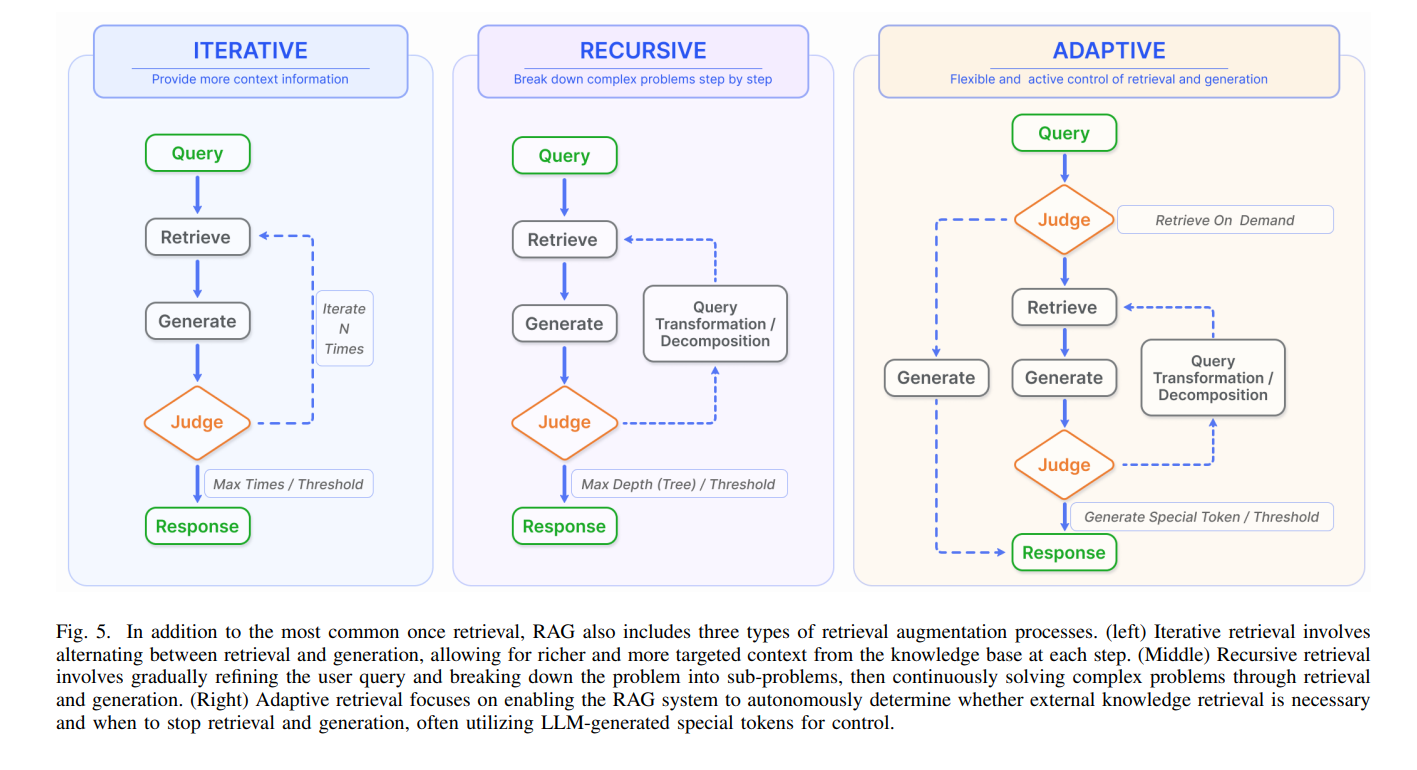
A.Iterative Retrieval
초기 쿼리와 지금까지 생성된 텍스트를 기반으로 지식 베이스를 반복적으로 검색하여 LLM에 더 포괄적인 지식을 제공하는 과정이다. 그러나 이는 의미적 불연속성이 있을 때, 또는 관련없는 정보의 누적이 있을 때 오히려 결과가 안좋게 나타날 수 있다. ITERRETGEN은 유저의 질문에 답변하기 위해 필요한 콘텐츠를 맥락을 활용하여 관련 지식을 검색하여, 이를 통해 다음 반복에서 향상된 응답을 생성한다.
B. Recursive Retrieval
Recursive Retrieval(재귀적 검색)은 이전 검색에서 얻은 결과를 기반으로 검색 쿼리를 반복적으로 수정하는 방식으로 진행된다. 재귀적 검색의 목표는 피드백 루프를 통해 점진적으로 가장 관련성 높은 정보에 수렴하여 검색 경험을 개선하는 것이다.
IRCoT는 CoT를 사용하여 검색 과정을 안내하고, 검색 결과를 바탕으로 이 연결된 사고 과정을 정제한다. ToC는 쿼리의 모호한 부분을 체계적으로 최적화하는 clarification tree를 생성한다. 이는 사용자의 요구가 처음부터 명확하지 않거나, 찾고자 하는 정보가 매우 전문적이거나 미세한 차이를 가진 복잡한 검색 시나리오에서 특히 유용할 수 있다.
긴 pdf나 문서들이 주어진 경우에는, 재귀적 검색과 멀티홉 검색을 결합할 수 있다.
 위는 챗지피티가 만든 멀티홉의 예시... 지금 생각해보니 위의 예시는 쿼리 확장에 좀 더 가깝겠다.
위는 챗지피티가 만든 멀티홉의 예시... 지금 생각해보니 위의 예시는 쿼리 확장에 좀 더 가깝겠다.
재귀적 검색은 긴 문서를 요약하여 재검색하고, 멀티홉 검색이 그 요약된 정보를 바탕으로 서로 연결된 세부적인 정보를 추출한다. 이렇게 하면 복잡한 자료에서 중요한 정보에 더 효과적으로 접근할 수 있다.
C. Adaptive Retrieval
LLM이 최적의 시점에서 검색할 콘텐츠를 능동적으로 결정할 수 있게 하여, 정보 검색의 효율성과 관련성을 향상한다.
예를 들어, Graph-Toolformer는 검색 과정을 명확한 단계로 나누어 LLM이 능동적으로 검색기를 사용하고, Self-Ask 기술을 적용하며(지금 이 정보가 필요한지,) , few-shot 프롬프트를 통해 검색 쿼리를 시작한다(예시를 주되 자유롭게 생성할 수 있게끔). 이러한 능동적인 접근 방식은 LLM이 필요한 정보를 언제 검색할지 결정하게 하며, 이는 마치 에이전트가 도구를 활용하는 방식과 유사하다.
WebGPT는 GPT-3 모델이 텍스트 생성 중에 검색 엔진을 자율적으로 사용할 수 있도록 강화 학습 프레임워크를 통합한다. 이 과정에서 검색 엔진 쿼리 생성, 검색 결과 탐색, 출처 인용과 같은 작업을 수행할 수 있도록 특별한 토큰을 사용하여 탐색한다. 이를 통해 GPT-3는 외부 검색 엔진을 활용하여 자체 능력을 확장할 수 있다.
