기존 방식
CoT라고, LLM모델이 풀이과정을 단계적으로 생성하면서 답변을 내놓는 방식이다. 그러나 CoT로 학습시키려면 양질의 데이터가 많이 필요하고, 학습된 데이터보다 테스크가 어려우면 못푼다는 문제가 있다.
Quiet-STaR은 답변을 생성하거나 질문을 읽을 때, 근거(생각)를 암묵적으로 생성하여 더 나은 답변을 내놓는다.
1. Think: 병렬적으로 근거를 생성한다.
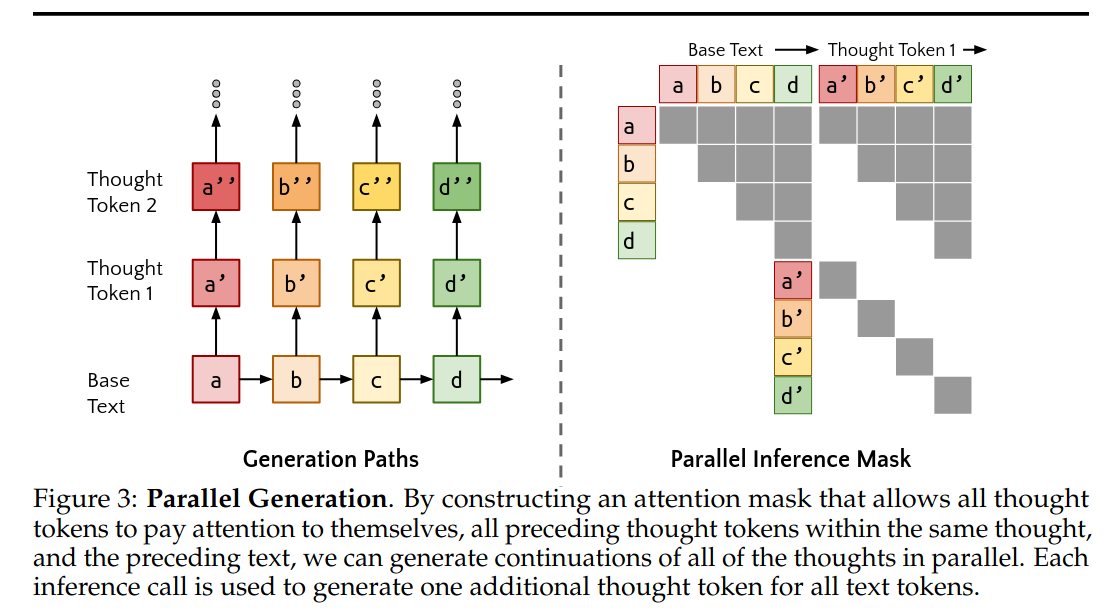
매 토큰마다 Thought Token, 즉 근거를 생성한다. 예를 들어 "< bos > the cat sat” 에서는 "yes orange saw down”을 생성한다. 이때 생성된 근거가 연속적으로는 의미가 없어 보인다. 그러나 Figure 3 에 보이는 parellel inference mask와 attention를 이용하여 불연속적으로 보이는 이 근거들에 내제된 생각을 이끌어낼 수 있다.
이때 근거의 끝과 시작을 표시하기 위해 <|startofthought|> 와 <|endofthought|> 메타토큰을 이용한다.
2. Talk: 근거가 있는 추론과, 근거가 없는 예측을 혼합한다
pre-training에서는 근거 없이 학습이 되었으니, 갑작스레 근거를 추가하여 모델의 혼란을 야기하지 않게 <|endofthought|> logits 와 원본 텍스트의 hidden state를 혼합하여(MLP layer)로 최종결과물을 학습한다.
3. Learn: 추론 과정의 최적화
<|startofthought|>은 '---'로 표현하므로서, 영어권 나라에서 생각하기 위해 멈추는 기호와 비슷하게 표현한다. 이는 pretrained된 모델이 '근거'라는 개념을 이해하도록 돕는다.
또한, 위에서 설명했듯이 매 토큰마다 병렬적으로 근거를 생성하므로, 각 토큰의 예측에 해당되는 근거만 학습이 된다. 즉 근거들은 전체적인 그림을 못본다.
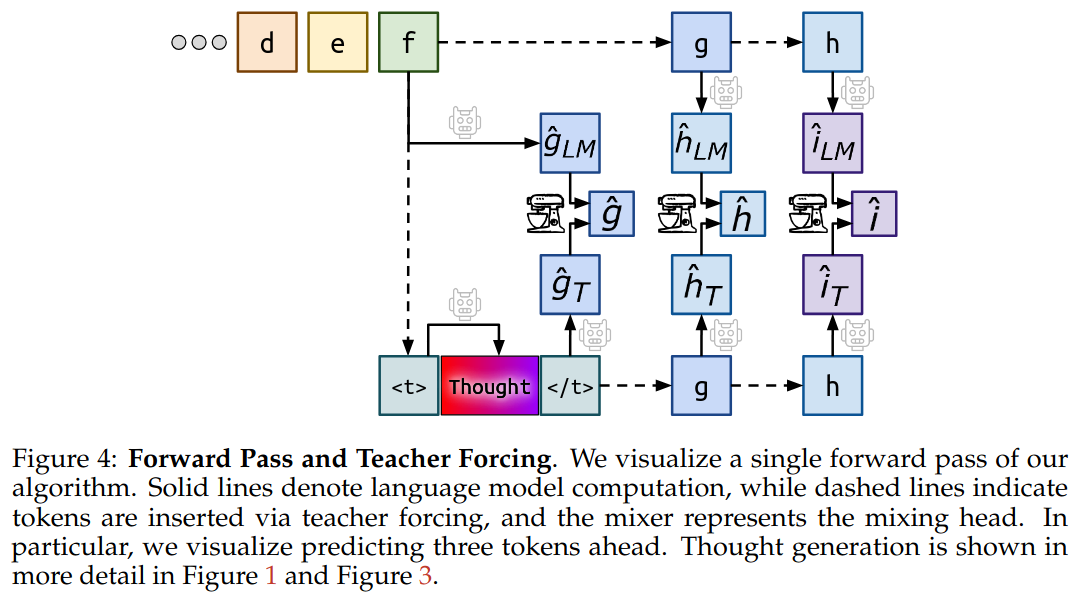
이때 teacher forcing을 사용하여 각 토큰 예측에 대해 모델이 실제 정답 토큰(ground-truth)을 사용하게 함으로써 예측이 매번 문장 전체의 정답 흐름에 맞춰지도록 유도한다.
학습에는 강화학습을 사용한다.
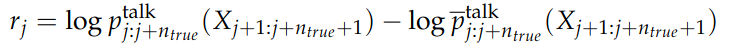
각 추론 T_j에 대한 보상 r_j는 해당 토큰에 대한 추론 평균 확률과의 차이를 계산하여 정의된다. 여기서 p_talk는 특정 추론에 기반한 예측 확률을 의미하고, p_talk의 평는 해당 토큰에 대한 평균 확률이다.
그러므로 특정 추론이 평균보다 더 나은 성능을 보일 때 보상이 높아지도록 설정되었다.
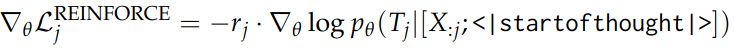
loss function에는 보상이 높은 추론에 더 많은 기울기(gradient)가 전달되도록 설정하여, 모델이 더 유용한 추론을 생성할 수 있도록 한다.
성능 측정
성능 측정은 추론이 필요한 테스크에서 진행하였다. 대부분 웹에서 크롤링된 데이터는 생각없이 내뱉기만 하면 되는 경우가 많아서...
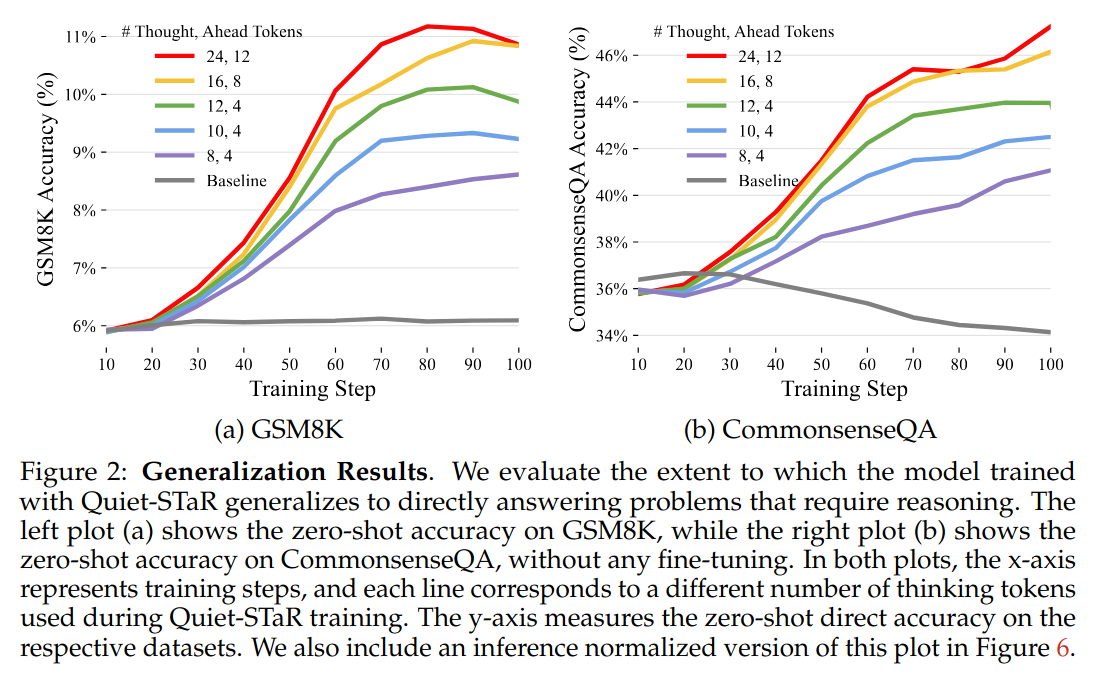
baseline보다 성능이 월등히 높고, thought token이 많아질수록 성능이 올라가는 것을 알 수 있다.
