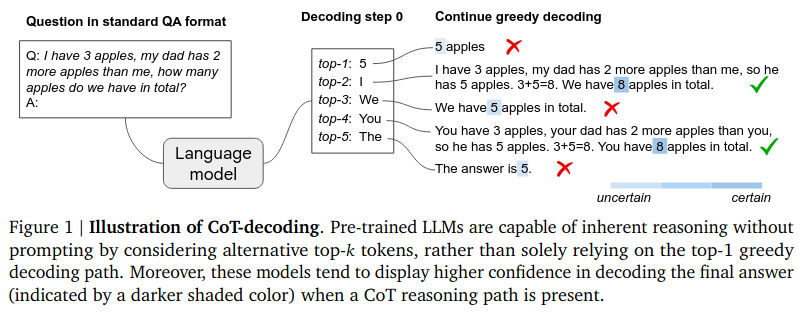
기존에 LLM은 greedy decoding이라고, 가장 높은 확률을 가지는 단어를 바로바로 다음 단어로 생성해버리는 방식으로 동작하였다.
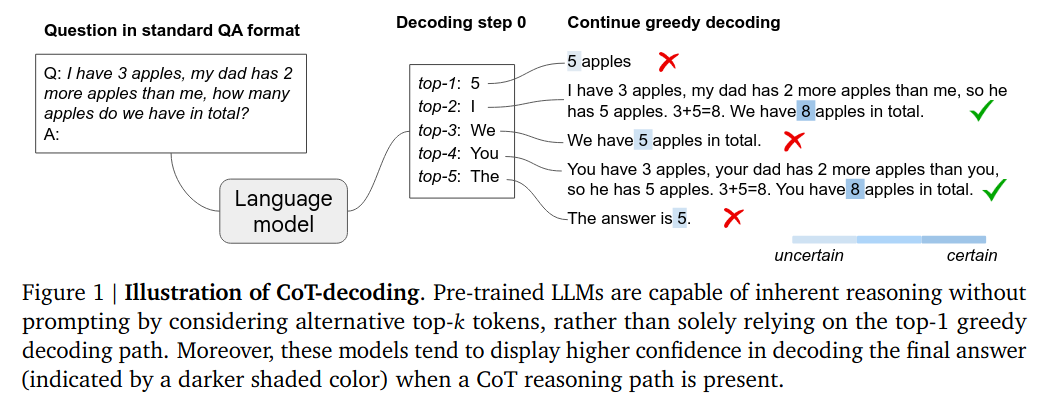
이것의 문제점은 모델이 고민할 여지를 안주는 것이다. 즉, 아래 예시에 보듯이 정답은 8임에도 불구하고 5 apples이 가장 확률이 높으니 바로 답으로 채택한다.
아래 예시는 temparature가 낮을수록 짧은 답변이 체택되는 것을 보여주는 것이다. 즉, 온도가 낮을수록 모델이 고민할 수 있는 여지는 줄어든다. 그러나 꼭 길게 답변하는 것이 정답인 것은 아니다. 위에서 볼 수 있듯, k=0일 때(단답)나 k=7일(CoT)때나 같은 답변($60) 을 보여준다.

그렇다면 어떤 기준으로 CoT가 더 나은 정답으로 가는 길에 가깝다는 것을 알 수 있을까? 구글은 logits을 분석하다가, CoT를 활용할 때 모델이 더 확신을 갖고 답변한다는 것을 알아냈다. 즉, 답변으로 생성된 제일 큰 확률과 두번째로 큰 확률의 차이가 CoT에서 더 도드라지는 것을 알아차린 것이다.
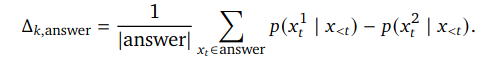
실제로 GMSAK 데이터셋 100문제에 대해 실험을 했다. 모델이 10개의 가능한 답변 경로(top-10 decoding paths)를 생성했을 때, 가장 확신을 가진 답변의 88%는 CoT로 생성된 답변들이었다.

위 실험에서 볼 수 있듯 CoT-decoding이 CoT-path 유무를 판별할 수 있는 가장 정확한 방법이었다.

또한, CoT-decoding + CoT-prompting이 제일 좋은 결과를 낸다는 것을 알 수 있다. 이 논문에서는 또한 top-k 토큰을 사용하여 다양한 추론 경로를 생성하고 탐색하였다.
