GPT-1
Decoder
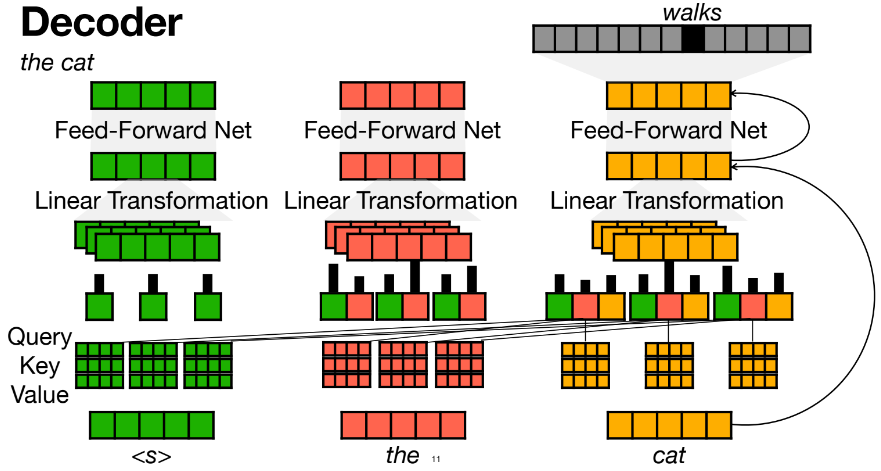
multi-head attention의 결과로 다음단어 예측하고, 예측한 단어로 stop token이 나올 때까지 계속 multi-head attention
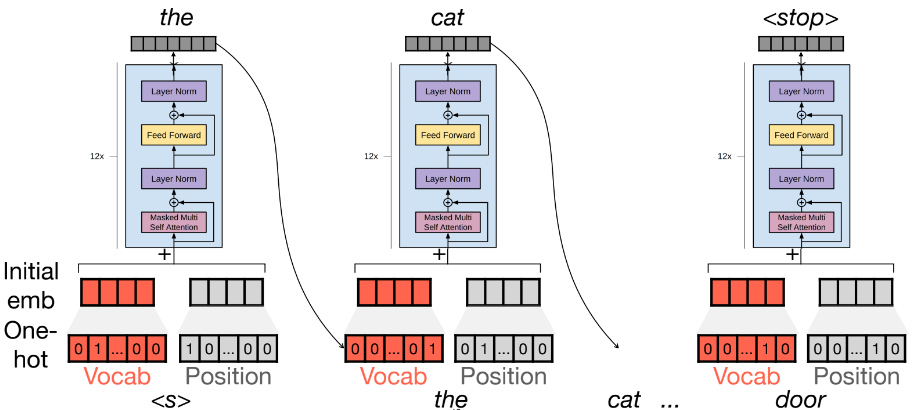
- position을 onehot vector로 나타냄
- vocab과 position을 transform해서 embedding으로 나타냄: pre-train에서 학습되는 부분
Encoder vs Decoder
[공통점]
- positional encoding, multi-head attention, feed-forward netis, residual connection
[차이점]
- sef attention:
- Encoder: bidirectional => encoder에 있는 모든 단어로 attention
- Decoder: 자기 앞에 있는 단어들과만 attention - Decoder
- predict an output token- cross attetion: encoder의 단어들과 attention, gpt에서 안씀
pre-training
next word prediction
- mask word prediction과 비슷
- Given a sentence, predict each word one by one sequentially
- "the cat walks to the door <stop>"
: <s>가 들어오면 the를 예측, the를 넣어서 cat을 예측...
: 앞에 있는 단어를 보고 뒷단어를 예측하기 때문에 앞단어들과만 attention
- "the cat walks to the door <stop>"
- next word prediction이 중요한 이유
- 다음단어를 예측할 수 있다
= a perfect understanding of the language
= understand the linguistic(syntactic, semantic, pragmatic, ...) information
ex) google search- memorize pre-traiing texts and can reproduce those texts
other details
- 12 layers, 12 attention heads, 768D word embeddings
- learned position embeddings
- Tokenization: Byte Pair encoding(BPE)
- A modified version of L2 regularization on all non bias or gain weights
- Activation function: Gaussian Error Linear Unit(GELU)
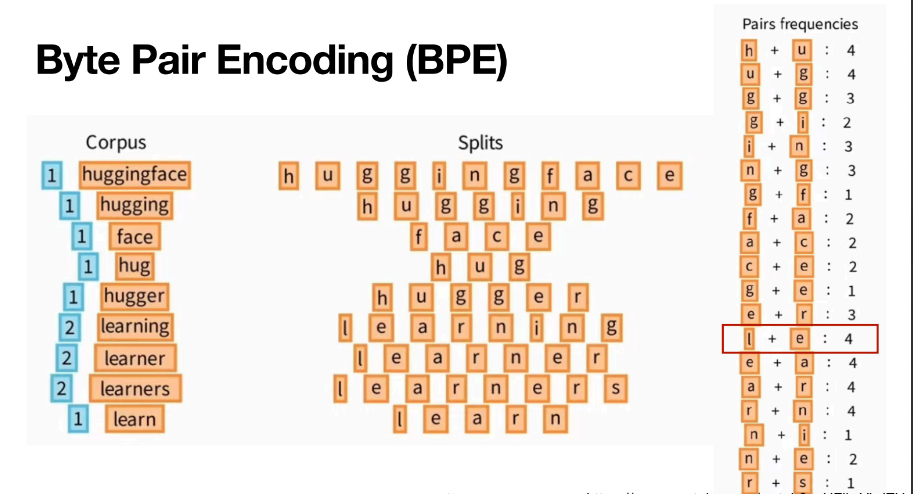
Byte Pair Encoding(BPE)
같이 나타나는 pair들의 frequency를 구하고 자주 같이 등장하는 token을 vocab에 추가한다.
wordpiece Tokenization vs BPE
| wordpiece Tokenization | BPE | |
|---|---|---|
| origin | part-of-speech tagging 단어의 품사가 무엇인가? | Data compression |
| Frequency Estimation | A, B token의 상대적인 freauency | A, B token의 절대적인 freauency |
| Prefix for Non-Start Tokens | ## | None |
| Application | BERT | GPT |

Downstream(Fine-Tuning) Tasks
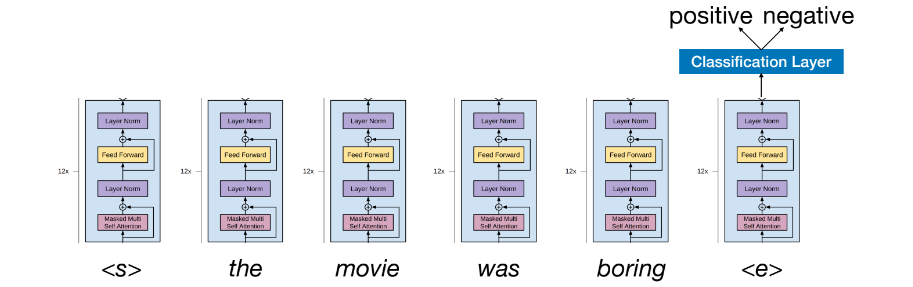
- GPT-1 does not gernerate an answer as text
- BERT처럼 input words를 한 번에 넣어서 parallel하게 self-attention함
- GPT-1는
- Attention heads attend only to previous words
- The classification layer is on top of the last token instead of the "[CLS]" token in BERT
- start token은 <s>이고 end token은 &lse>: &lse>는 모든 previous word와 attention되기 때문에 contextualize embedding
=> BERT는 [CLS] token을 앞에 붙이든 뒤에 붙이든 큰 상관이 없지만 GPT는 <e>를 뒤어 붙여야 context 정보를 저장 가능
Natural Language Inference
- Premise, Hypothesis가 주어졌을 때 label(entail, contradict, neutral)를 분류
- 이것을 가지고 fine tuning

Multiple Choice Question Answering
- given a question, a document, and multiple choices, choose the right answer
- context: Document+Question
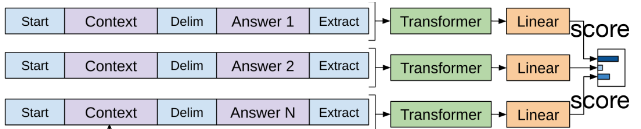
Classification
- grammatical/ ungrammatical 분류

Semantic Similarity
- equivalent/ not equivalent를 분류

Ablation studies
model의 여러 component의 중요성을 보기 위해 각각의 component를 하나씩 빼가면서 성능 측정
- full transformer model
- pretrain을 제외한 transformer model
- transformer 대신 LSTM 사용
Zero-Shot Ability
- 한 번도 training하지 않은 task를 주었을 때 model이 얼마나 잘 할 수 있는지 측정
- 여러 task를 langauge modeling으로 풀 수 있는 방식으로 바꿈
- text를 generate할 확률을 계산할 수 있다는 점을 활용해서 뒤에 나올법한 text를 정답으로 정함
GPT-2
- maximize zero-shot ability
- GPT-1 showed a promising zero-shot ability - use better data for pre-training and increase the model size
Pre-training Data
- 좋아요 많이 받은 post는 퀄리티가 보장되어 있다는 가정하에 data 수집
- wikipedia 제거(contamination)
performance
Langauge Modeling
- Perplexity
- model이 자연스럽게 text를 generate하는 능력을 평가하기 위함- generate할 확률을 모두 곱한것의 -1/N승
=> 작은게 좋음, generate할 확률이 커진다는 의미 - 여러 model에서 동일한 문장을 생성할 확률을 비교하기 위해
- generate할 확률을 모두 곱한것의 -1/N승
Reading Comprehension
- 질문했을 때 원하는 답을 얼마나 잘 생성하는지 평가하기 위함
Summarization
- 다른 model에 비해 GPT-2의 성능이 훨씬 떨어짐
Generalization vs Memorization
- GPT-2's performance come from its generalizability from langauge modeling to downstream tasks or by simply memorizing texts that appear in downstream tasks?
- 8-grams을 뽑아 pre-train data와 test data가 얼마나 겹치는지 확인
=> 매우 조금 겹침: generalization을 잘하는 것
summarize
- GPT-2 performs well on langauge modeling tasks and outperforms other unsupervised methods in some tasks.
- supervised model에 대해서는 성능이 안좋다
- zero-shot capabilities increas as the model size increases, implying that more scaling may achieve substantially better performance.
GPT-3
-GPT-2에서 model size가 커질수록 zero-shot ability가 상승하는 것 보여줌
- model size를 더 늘려보자
- larger ans more diverse data로 pre-train 해보자
shot learning
Few-shot
- The model is given a few demonstrations of the task at inference time as conditioning, but no weights are updated
- ex) [Question1][Answer1] [Question2][Answer2]... [Question]
One-shot - The model is given one demonstration
- ex)[Question1][Answer1] [Question]
Zero-shot - The model is given only natural langauge description of the task without examples
- ex) [Question]
Performance
Scaling Laws
- model size가 늘어날수록 zero shot 성능 증가
- 성능: Few-shot> one-shot> zero-shot
- BERT를 finetuning한 것 보다 잘함
Number of Examples
- example이 8개 이상부터는 성능이 많이 증가하지 않음
Generalization vs Memorization
- pretrain data에 있는 clean해서 13-gram dataset으로 다시 성능 측정
=> 정제된 데이터와 원래 데이터와 성능차이 없음: generalization을 잘하는 것
Stereotype Tests
- 편견을 얼마나 가지고 있나
- Gender Stereotypes: 특정 직업에 대해 성별에 대한 편견 가짐
- Racial Stereotypes: 인종 차별 편견 가짐
- Religious Stereotypes: 종교와 관련된 단어 생성에 편견
- 인터넷에 있는 data로 학습시켰기 때문에 internet scale을 가지고 있는 것이 당연하다
- 특별한 환경에서 실험한 결과이기 때문에 편견을 가지고 있는 것으로 오해하면 안된다

hello world