Main idea
- NLP task를 text input, text output으로 바꾸자
- unified model을 다양한 task에 사용가능
transformer model architecture
- Encoder + Decoder: T5, BART
- Encoder-only: BERT, RoBERTa
- Decoder-only: GPT
T5
Multi-head self-attention
- input token attention 하기
Multi-head cross attention - deocoder 첫번째 step: special token
- decoder step 현재 단어와 input token간의 관계
- decoding step 현재 단어의 query를 구하고 encoding step 단어들의 key, value를 구함
- decoder에서 예측한 단어는 다음 단계의 input으로 들어감
Pre-training
- BERT
- masked langauge model
- next sentence prediction
- GPT
- Next word prediction
- T5
- unsupervised Denoising
- Supervised Text to Text
Pre-training - Unsupervised Denoising
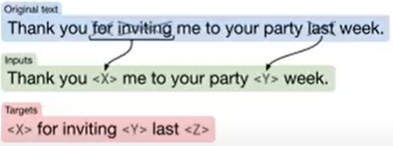
- bert의 mask langauge modeling과 유사
- Randomly sample and drop out 15% of tokens in the input sentence
- 지워진 token의 자리를 sentinel token으로 대체: 순서가 중요하기 때문에 각각 다른 token을 사용(<X>, <Y>)
- 원래 어떤 단어가 들어가야 했는지 예측하는 방식: text generate
Pre-training - supervised Text-to-Text
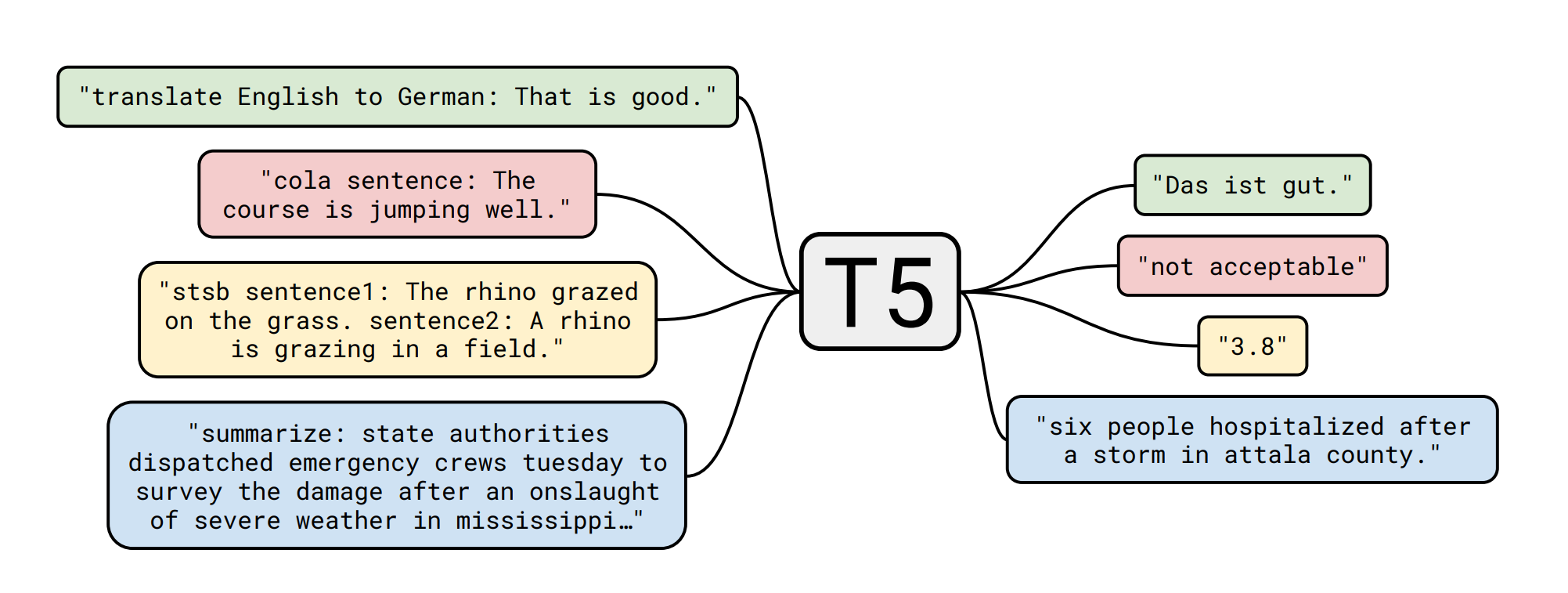
하나의 model을 여러개의 dataset으로 학습
Summary
- text-to-text framework가 하나의 model을 다양한 task에 대해 학습할 수 있게 해주는 방법 제시
- unified된 model을 다양한 task에 미리 pre-train 시켜놓으면 individual task를 푸는데도 도움이 된다.
- unsupervised denoising이 도움이 된다.

hello world