반갑습니다.
오늘은 BERT에 대해 알아보겠습니다.
저도 작성하면서 알아가야 할 것 같습니다. 어려워요 ㅠㅠ
BERT란 ?
Attention 알고리즘 기반 자연어 처리 모델로서, Transformer의 Encoder부분만 사용하여 문장을 양방향에서 학습할 수 있다는 장점을 가지고 있습니다.
감정 분류 / 문장 분류 / 질의 응답에서 특히 높은 성능을 기록하였습니다.
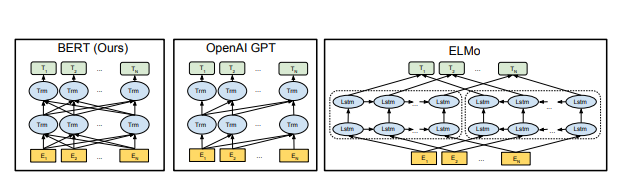
사진에서 가장 왼쪽의 모델이 BERT입니다.
간단히 말하면 Transformer의 인코더 부분만을 떼서 모델로 만든것이 BERT라고 보시면 되겠습니다. (Decoder 부분만을 사용한다면 GPT가 됩니다.)
Transformer은 크게 디코더와 인코더로 나뉘죠.
여기서 인코더는 Self-Attention 기법을 사용하여 주어진 문장의 단어들을 문맥 정보를 잘 포함하고 있는 고차원 벡터로 바꾸는 역할
디코더는 주어진 고차원 벡터를 Cross-Attention을 통해 다시 단어로 바꾸는 역할
을 수행합니다.
BERT 를 더 자세히 생각해 보자면 Self-Attention이 무려 문맥을 양방향으로 보고 병렬학습 깔즤 가능한 기똥찬 아이디어인 것 같으니 이것만 활용해서 한번 해보겠다
라는 의미 인 듯 합니다.
BERT는 MLM(Masked-Language-Model)과 NSP(Next-Sentence-Prediction) 두 가지 학습 방법으로 훈련됩니다.
여기서 주목해야 할 점은 둘 다 Self-supervised_learning(자기지도학습)을 통해 학습이 이루어졌다는 점입니다.
Self-supervised-learning이 뭐에요?
Self-supervised-learning(자기지도학습)이란, 사람이 직접 Labeling한 데이터를 학습하는 것이 아닌 모델이 자기 스스로 문제를 만들고 그 문제를 직접 풀이하면서 학습을 진행하는 방법입니다.
소개만 봐도 레전드 사건 발생이죠.
여태 Labeling을 하는데 10시간 100시간 500시간이 걸렸는데, 이런 고통의 labeling 시간을 없앨 수 있다는 것은 아주 대단한 대목이라고 봐도 무방할 듯 싶습니다.
자기지도학습이 가능하다는 것은 기존에 한정돼 있는 데이터만을 사용하는 것이 아닌, 아주 많은 텍스트 데이터를 학습할 수 있다는 큰 메리트를 가지고 있습니다.
뒤에 소개할 MLM과 NSP의 설명을 읽으신다면 자기지도 학습이 어떻게 이루어졌는지를 알 수 있습니다.
MLM(Masked-Language-Model)
MLM(Masked-Language-Model)이란, 단어의 특정 부분을 랜덤한 비율로 Masking하고, 그것을 모델이 맞추며 문맥을 학습하는 과정을 의미합니다.
이 과정을 통해 모델은 단어가 문장 내에서 어떤 역할을 하는지, 단어의 의미가 맞게 쓰였는지를 학습할 수 있게 됩니다.
import torchtext
import numpy as np
import torch
from torch import nn
# torchtext.disable_torchtext_deprecation_warning()
import datasets
from transformers import BertTokenizer, BertForMaskedLM
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
dataset = datasets.load_dataset("bentrevett/multi30k")
tokens = tokenizer(dataset['train']['en'], padding="max_length", truncation=True, max_length=16, return_tensors="pt")
input_ids = tokens['input_ids'].clone() # input_ids를 복사하여 수정
labels = input_ids.clone() # labels도 복사하여 사용
# 15% 확률로 마스크할 위치 선택
probability_matrix = torch.full(labels.shape, 0.15)
mask_indices = torch.bernoulli(probability_matrix).bool()
# 마스크되지 않은 위치는 -100으로 설정 (손실 계산 제외)
labels[~mask_indices] = -100
# 마스크된 위치 중 10%는 랜덤한 단어로 교체
rand_indices = torch.bernoulli(torch.full(labels.shape, 0.1)).bool() & mask_indices
random_words = torch.randint(len(tokenizer), labels.shape, dtype=torch.long)
input_ids[rand_indices] = random_words[rand_indices] # 10%는 랜덤한 단어로 대체
# 10%는 원래 단어 유지
origin_indices = torch.bernoulli(torch.full(labels.shape, 0.1)).bool() & mask_indices & ~rand_indices
input_ids[origin_indices] = labels[origin_indices] # 10%는 원래 단어로 유지
# 나머지 마스크된 위치는 [MASK] 토큰으로 설정
mask_indices = mask_indices & ~rand_indices & ~origin_indices
input_ids[mask_indices] = tokenizer.convert_tokens_to_ids(tokenizer.mask_token)
# 결과적으로 tokens 딕셔너리의 input_ids와 labels를 업데이트
tokens['input_ids'] = input_ids
tokens['labels'] = labels
간단하게 코드를 작성하려 했는데, 꽤 길어졌네요.
설명해보자면 전체 단어를 숫자로 매핑하고 이를 Masking하는 작업입니다.
마스킹 할 인덱스를 뽑고, 그 인덱스가 아닌 단어에는 -100으로 labeling하여 나중에 loss 계산할 때 제외하는 방식이지요.
loss_fn = torch.nn.CrossEntropyLoss(ignore_index=-100)로 설정되면 -100의 인덱스가 나왔을 때에는 로스 계산을 안합니다.
여기서 전체 단어 중 15프로를 Masking_Index로 사용하고 있는데, 15프로에서도 또 나누고 있죠.
15프로 중
80프로는 Masking
10프로는 랜덤한 단어로
나머지 10프로는 단어를 그대로 사용하고 있습니다.
그냥 다 마스킹하면 되지 왜 ??
라고 생각하신다면 똑똑하신겁니다.
제가 그랬거든요
['MASK']토큰만을 사용한다면 모델은 ['MASK']토큰이 나왔을 때에만 예측을 잘 하도록 학습됩니다.
하지만 실제 모델을 사용할 때에는 ['MASK']라고 주지 않겠죠.
그래서 실제 나올 수 있는 단어들을 넣는겁니다.
근데 또 그 중에서 10프로는 그대로의 단어를 쓴다 ??
만약 단어를 그대로 넣는 작업을 하지 않는다면 예측할 때 주어진 단어는 절대 답이아니겠구나
라는 의도하지 않은 편향이 생기게 됩니다.
따라서 모델이 예측을 할 때 가장 어렵게 학습하기 위한 다양한 방법이라고 생각하시면 되겠습니다.

글씨가 좀 작아서 불편하시죠 죄송합니다
labels를 보시면 '[MASK]'라고 설정된 부분만 실제 정답이 있음을 알 수 있습니다.
NSP(Next-Sentence-Prediction)
NSP(Next-Sentence-Prediction)이란, 두 문장을 입력으로 주고 첫번째 문장이 두번째 문장과 이어지는 문장인지를 맞추는 학습 과정을 의미합니다.
이 과정을 통해 모델은 문장의 문맥을 알고 자연스러운 문장 구조를 학습할 수 있게 됩니다.
MLM이 단어를 맞추는 Task였다면 NSP는 두 문장이 같은 맥락인지를 파악하는 Task입니다.
두 문장의 앞에는 [CLS] 토큰을, 문장이 분리되는 시점에 [SEP]토큰 하나, 끝나는 시점에 [SEP]토큰 하나를 붙이는 전처리를 통해 학습할 수 있습니다.
모델이 [CLS]를 입력으로 받는다면, 두 문장이 연속적인지를 output으로 내보내고, 실제 답과의 loss계산하여 모델을 학습합니다.
Ex) (1)나는 인공지능을 공부하는 학생이다.(2)똥 마렵다.
라는 문장들이 있다면
['[CLS]', '나는', '인공지능을', '공부하는', '학생이다', '.' ,'[SEP]', '똥', '마렵다', '.', '[SEP]','[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]']
로 나뉘게 됩니다.
이것을 모델에 input으로 줍니다.
input으로는 세가지가 들어갑니다.
1. input_ids : 숫자로 매핑 된 단어들
2. input_type_ids : 각 단어가 어떤 형식인지 ([0,0,0,0,0,0,1,1,1,1,1,1,1,1,1] 같은 형식)
3. attention_mask : 어디까지가 진짜 문장이고 패딩인지
([1,1,1,1,1,1,1,1,1,1,0,0,0,0,0]같은 형식)
이 때, CLS토큰을 받으면 뒤의 문장이 이어지는지의 여부를 이진 분류를 통해 학습합니다.
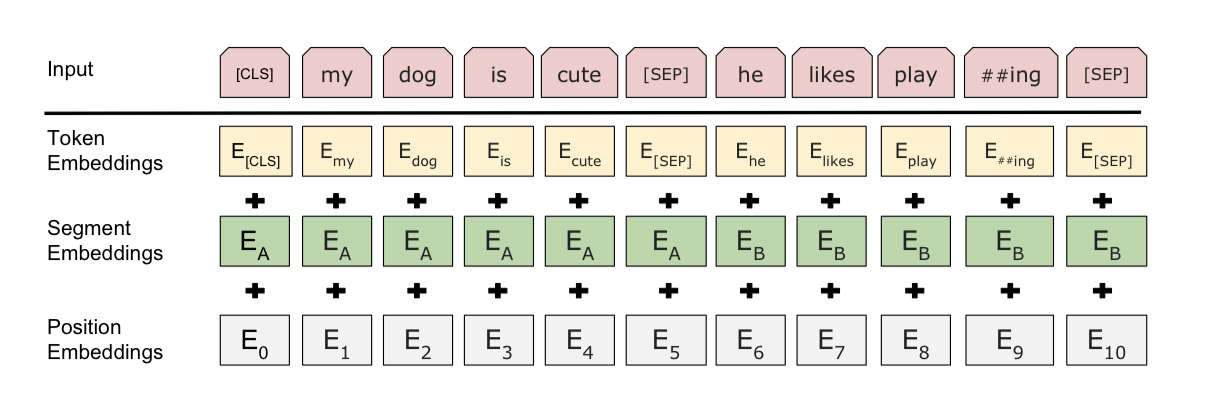
input word들은 위와 같이 Position Embedding과 Segment Embedding값을 더한 형태로 구현됩니다.
Segment Embedding은 단순히 input_type_ids가 0인지 1인지에 따라 다른 값을 더해 모델이 두 문장을 구분할 수 있도록 합니다.
Positon Embedding은 각 문장의 순서를 인지할 수 있도록 상수값을 더하는 과정입니다. (Self-attention은 순서 정보를 알 수 없기 때문)
위 두 과정을 자기지도학습을 통해 한번에 학습합니다.
두개를 한번에 학습 ?!
['[CLS]', '나는', '인공지능을', '공부하는', '학생이다', '.' ,'[SEP]', '똥', '마렵다', '.', '[SEP]']
라는 문장으로 바꿨으면, 여기에 Masking까지 더하는 것이지요.
['[CLS]', '나는', '인공지능을', '[MASK]', '학생이다', '.' ,'[SEP]', '똥', '마렵다', '.', '[SEP]']
요렇게 ~~
ㅎㅎ
이러한 험난한 과정을 반복해서 겪은 BERT 모델은 Pretrained model입니다.
이후에 본인이 풀고싶은 Task에 맞는 훈련을 추가적으로 Fine-tuning한다면 기존의 모델보다 더 대단한 성과를 낼 수 있겠습니다.
여기서부터는 Supervised Learning을 통해 학습합니다.
Pre-trained BERT model의 취직처를 알아보겠습니다.
'
'
- Sentence Classification
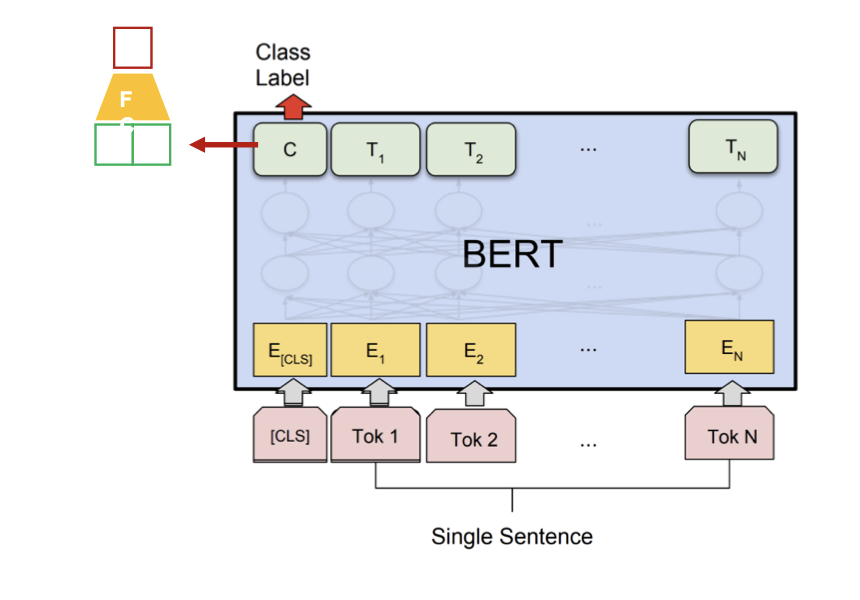
CLS토큰의 output을 Fully connected layer과 softmax를 통과시켜 문법적으로 맞는 표현인지를 학습합니다.
- Sentence Pair Classification
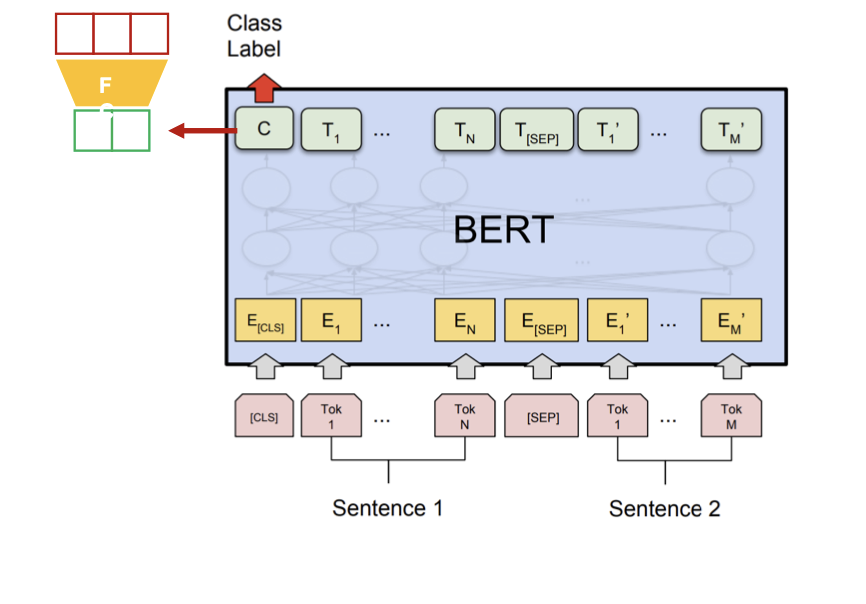
CLS토큰의 output을 Fully connected layer과 softmax를 통과시켜 두 문장 사이의 관계를 학습합니다.
ex) 1. 나는 판교 동사부마라탕을 먹었다. 2. 어제 판교동사부 마라탕은 적어도 마라탕 한개를 팔았다.
두 문장이 논리적으로 맞는지를 학습합니다. (entailment)
- Sentence tagging
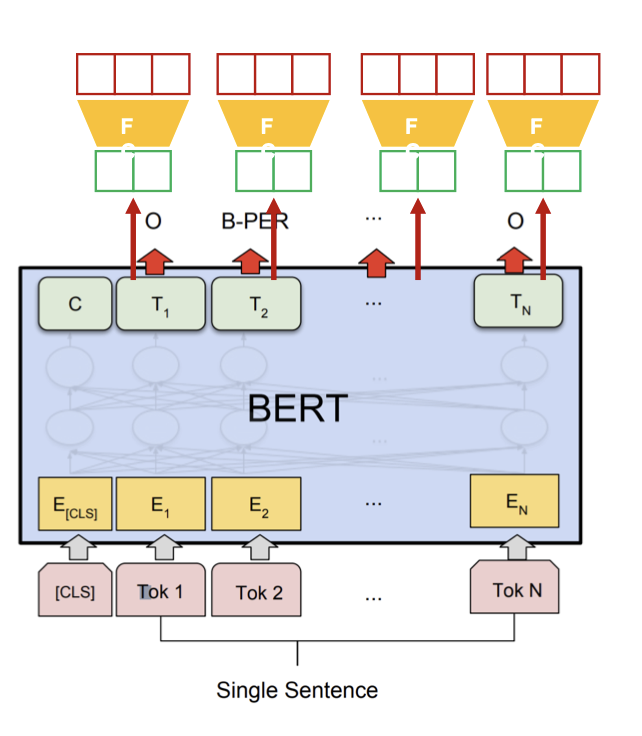
토큰 단위로 품사를 예측하는 task를 수행합니다.
- Machin reading comprehension
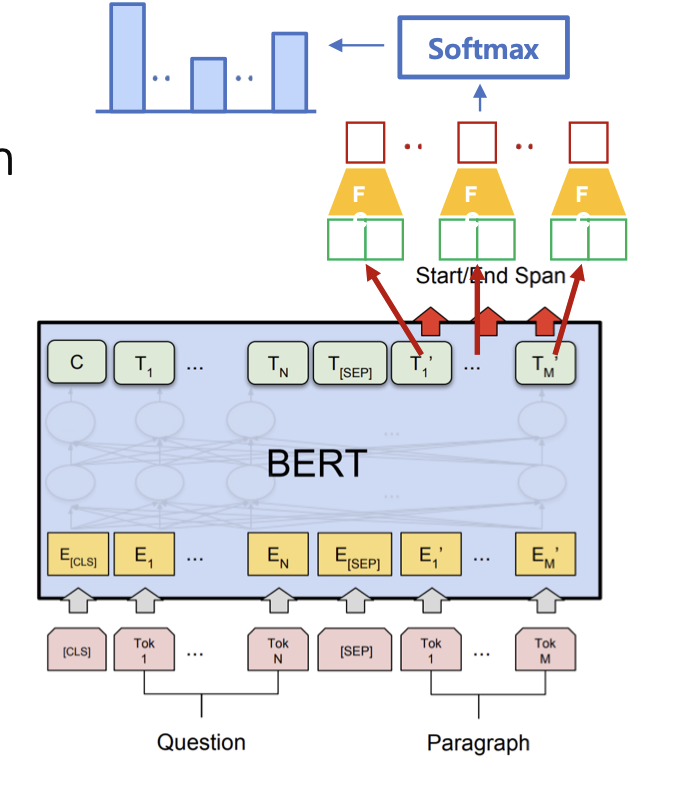
문장에서 주어진 질문에 대한 답을 잘 표현하는 것을 목표로 학습합니다.
[[CLS] 질문 [SEP] 문맥 [SEP]]
의 형식으로 입력을 받으며 이 중 정답의 시작과 끝 인덱스를 output으로 내보냅니다.
이렇게 BERT에 대해서 설명을 끝냅니다.
적으면서도 저도 자세히 모르는 부분이 있는 것 같아 아쉽습니다.
제가 더 똑똑해진다면 글을 자주 수정할 것 같습니다.
감사합니다 !!
