반갑습니다.
RNN계열(RNN, LSTM, GRU)에 대해 설명해볼까 합니다.
RNN 모델이 어떤 구조인지 모르고 사용하시는 분들이 꽤 있는 것 같습니다.
사실 제가 그렇습니다.
이번에 설명하면서 저 또한 많이 배워가는 기회가 됐으면 좋겠습니다.
RNN 이 뭐 임?
RNN이란 Recurrent Neural Network의 약자로, 한국어로는 순환 신경망이라고 불립니다.
시계열 데이터와 같은 순서 개념이 있는 데이터를 처리하기 위해 고안되었으며 t-1시점의 출력을 다시 input으로 받는 순환적인 특징을 가지고 있습니다.
이를 통해 모든 RNN이 같은 가중치를 공유하면서도 이전 정보를 추가적으로 받을 수 있다는 장점을 가지고 있습니다.
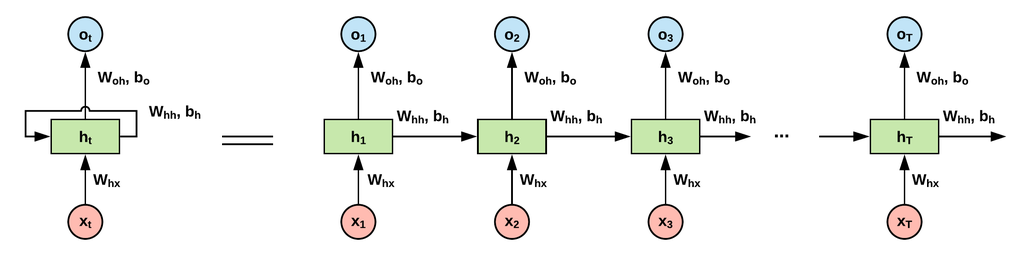
위 사진이 RNN의 구조입니다.
살펴보면, RNN은 총 두 가지의 output이 나옴을 알 수 있습니다.
하나는 다음 차례에 넣을거 (hidden state)
또다른 하나는 다음 차례에 넣을거 (output)
일단 hidden state를 현재 입력과 이전 출력을 바탕으로 계산하고,
현재의 hidden state를 W_output과 곱해 밖으로 내보냅니다.
RNN 기본 모델은 문제점이 아주 많습니다.
- 문장 데이터를 예로 들었을 때, 앞단의 정보만 받는다.
- 긴 정보에 대해서는 뒤로 갈 수록 제일 앞단의 정보가 흐려진다.
- Backpropagation을 진행할 수록 기울기 소실/폭발이 생긴다.
3번에 대해서만 설명을 해 보면, RNN계열은 BPTT(Back-Propagation-Thorough-Time) 이라는 방식으로 역전파가 진행되는데
입니다.
연쇄법칙을 통해 로스를 전달하는 과정에서 가 계속 같은 값을 곱하게 됩니다.
계속 같은 값을 곱하게 되는 과정이 Exploding/Vanashing문제점을 야기하는것이지요.
문제점이 너무 많다보니, RNN을 개선한 다양한 모델이 나오기 시작했습니다.
이번 글에서는 대표적인 LSTM과 GRU에 대해서 얘기해보겠습니다.
LSTM(Long-Short-Term-Memory)
LSTM이란, 기존 RNN의 장기기억 의존 문제를 보완하기 위해 고안된 모델입니다.
RNN과 다르게 input / output gate와 더불어 cell, forget gate를 추가하여 장기기억 의존성 문제를 어느정도 해결하였습니다.
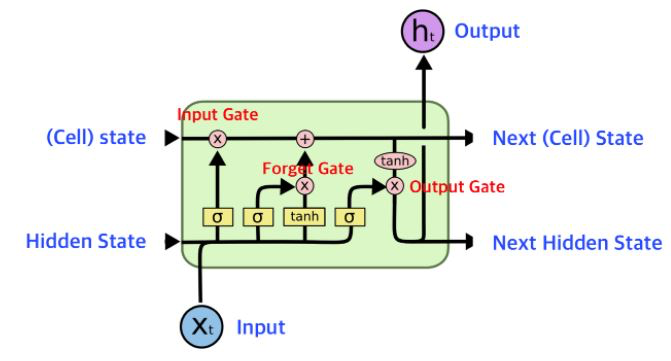
Cell gate와 Forget gate를 추가했다는 것이 무슨 의미일까요
간단히 요약하면, input과 이전 단계에서의 output만 고려하지 않고, 어떤 정보를 잊을 것인지 판단(forget)하고, 어떤 정보를 적을 것인지를 정해서 (funtion gate) 새로운 기억(cell)을 만듭니다.
그리고 이 cell state를 통해 output과 다음 입력으로 사용 될 next cell state를 만드는 것이죠.
GRU(Gated-Recurrent-Unit)
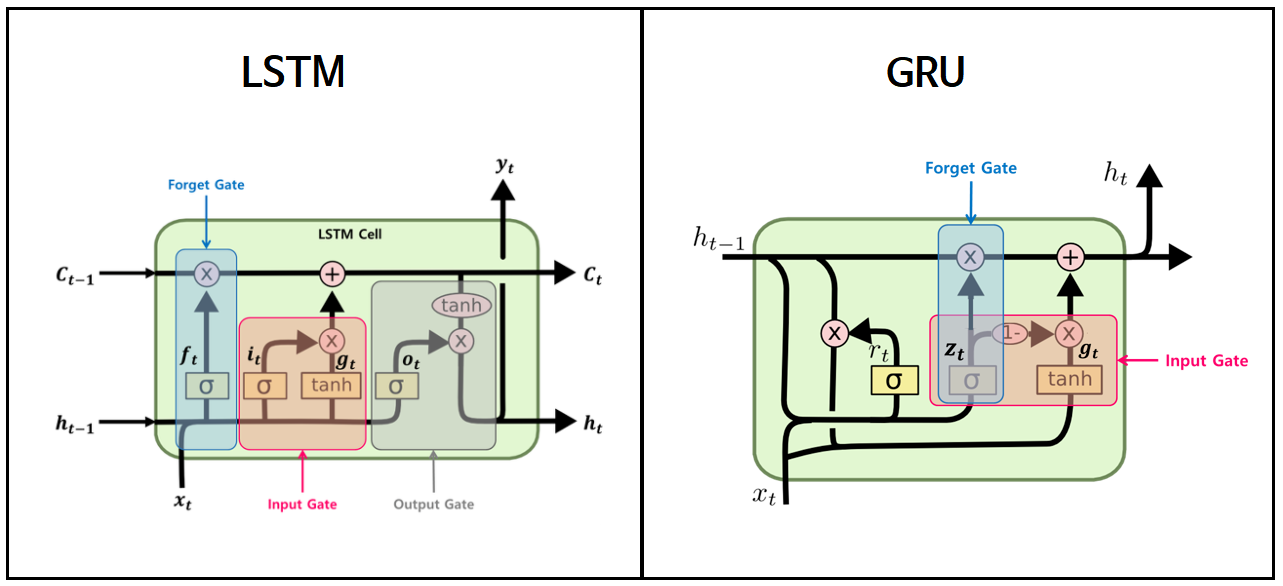
사진을 통해 Cell state가 어떻게 없어졌는지, input이 몇개인지 output이 몇개인지를 살펴보시면 되겠습니다.
GRU(Gated-Recurrent-Unit)는 LSTM에서 Cell state를 빼고, hidden state만 사용한 모델입니다.
LSTM의 경량화 모델로 생각하시면 되겠습니다.
고려해야 하는 W가 줄었으니까요.
하지만 성능은 LSTM 만큼 나오기 때문에 자주 쓰입니다.
흔히 모델에서 RNN계열을 사용하였다 라고 하면 Vanilla RNN(가장 기초적인 RNN)이 아닌 LSTM이나 GRU를 의미합니다.
하지만 위 모델들은 전부 기존 RNN계열의 문제점을 무릎을 탁 칠 정도로 해결하지 못했습니다.
가중치를 확인해보면 RNN보다는 확실히 Vanishing/Exploding이 줄었지만 여전히 남아있었고, 앞 문장만 본다는 사실은 변함이 없었으니까요.
앞 문장만 본다는 단점을 커버하고자 Bidirectional LSTM 또한 제시되었지만 이건 약간 뇌절? 같은느낌 ㅋㅋ
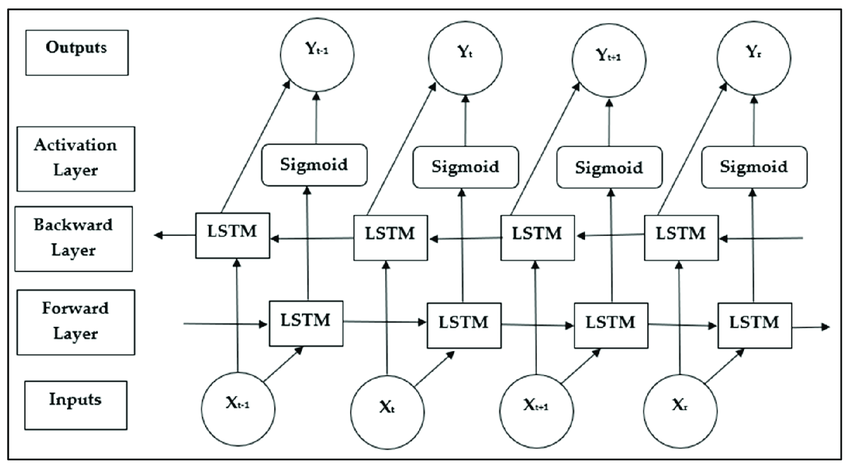
자 딱봐도 뭔가 범상치않죠
이쯤 되면 석박님들께서 슬슬 아,, 뭔가 방향성 자체가 좀 뇌절인 것 같다라는 생각을 하신 듯 합니다.
코드가 길어지고 뭔가 예외가 있는 것 같다 라고 생각하게 된다면 알고리즘 자체가 문제라고 생각하게 됩니다. 제가 백준 풀때 그랬거든요
그래서 아예 방향성을 바꾼 Attention 모델이 요즘 대세로 쓰이게 됐습니다.
Attention 알고리즘에 대해서는 제가 글을 작성한 것이 있으니, 제걸 봐주시거나 더 잘하시는 분들의 글을 읽어주시면 되겠습니다.
감사합니다.
