반갑습니다.
Hugging Face에 대해 설명해볼까 합니다.
이제는 요즘 AI모델링의 표준이지 않을까 싶습니다.
저도 존재만 알았는데 이번에 글을 작성하면서 제대로 알아가는 시간이 되었으면 좋겠습니다.
Hugging Face가 뭐죠?
Hugging Face란 데이터 수집, 모델, 훈련, 평가, 공유까지 AI모델링의 모든 과정을 알기 쉽고 간편하게 모듈화 해 놓은 오픈소스 플랫폼입니다.
수천개의 AI 모델이나 Tokenizer 등을 간단한 코드 작성으로 불러올 수 있게끔 모듈화하여 오픈소스로 배포합니다.
최근에 Hugging Face에 대해 배우며 느낀 점이 있습니다.
"이걸 먼저 알았다면 큰일날 뻔 했다.
공부를 거의 안해도 쓸 수 있잖아?"
허깅페이스는 그정도로 간편하고 강력한 툴이 아닐까 싶습니다.
AI를 모델링하며 필요한 거의 모든 부분들은 이미 구현이 돼 있고, 값을 지정하거나 True, False로 지정하여 사용할 수 있습니다.
Hugging Face가 지원하는 도구들
1. Dataset
일반적으로 텍스트데이터의 처리 과정은
Dataset 수집 > Tokenizing > Dataset Mapping > DataCollator의 순서를 따릅니다.
허깅 페이스에서는 위 과정을 모두 지원합니다.
먼저 논문에서 평가, 훈련에 쓰이는 대부분의 데이터셋을 간편하게 불러올 수 있습니다.
다른 사람들이 올려놓은 데이터셋 또한 로드할 수 있습니다.
허깅페이스 홈페이지에 들어가면 Dataset 항목이 있습니다.
이를 눌러 본인이 원하는 태그들을 고르고, 필요한 데이터셋을 찾습니다.
데이터셋을 찾았다면, 이름 오른쪽의 copy 버튼을 클릭한 뒤
from datasets import load_dataset
data = load_dataset('path')를 통해 불러올 수 있습니다.
Tokenizer 또한 불러올 수 있습니다.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
def mapping(example):
return tokenizer(example['text'], truncation = True, padding = 'max_lenghth')
dataset.map(mapping)와 같이 구성하면 데이터들을 매핑할 수 있겠죠.
또 Tokenizer에서
tokenizer.add_tokens(['힘들다', '배고프다'])
tokenizer.add_special_tokens({'cls_token' : "<CLS>" })와 같이 원하는 토큰을 추가할 수도 있습니다.
마지막으로, DataCollator을 지원합니다.
DataCollator는 텍스트 데이터를 동적으로 처리할 수 있게 해주고, 용도에 따라 추가적인 전처리를 지원합니다.
(추가적인 전처리?) : MLM, CLM등을 해줌
(동적 처리?) : 배치를 보고 최대 길이가 100이면 패딩을 100까지만 해서 메모리를 효율적으로 관리해줌
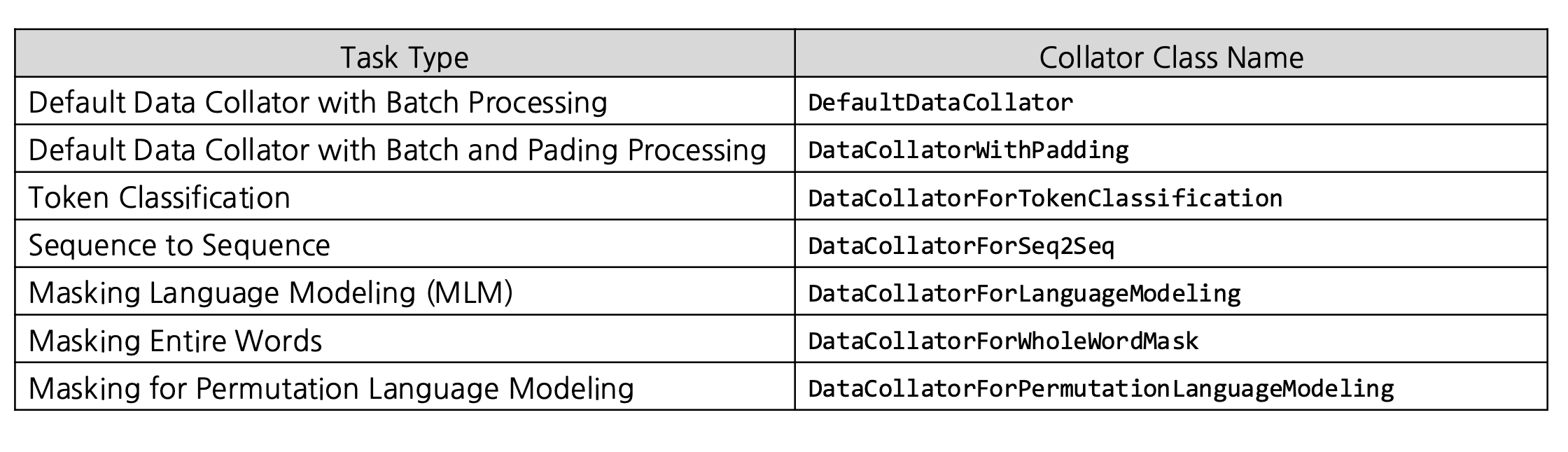
이렇게 용도에 따라 다양한 DataCollator을 사용할 수 있겠습니다.
2. Model
Dataset과 마찬가지로 다양한 최적화 기법들이 적용된 pretrained 모델들을 불러올 수 있습니다.
허깅페이스 홈페이지의 Models에서 본인의 의도에 맞는 태그들을 고른 뒤, 알맞는 모델을 찾아 model_name을 복사합니다.
from transformers import AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)본인의 모델을 peft 모델로 바꿀 수도 있습니다.
(peft 모델이란, parameter efficient fine tuning의 약자로 특정 부분만 집중적 학습하여 적은 수의 매개변수를 통해 특정 Task를 집중적으로 수행하는 모델을 의미합니다.)
from peft import LoraConfig, TaskType, get_peft_model
from transformers import AutoModelForSeq2SeqLM
peft_config = LoraConfig(task_type = TaskType.SEQ_2_SEQ_LM, inference_model = False, r = 8, lora_alpha = 32, lora_dropout = 0.1)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
model = get_peft_model(model, peft_config)
위와 같이 config만 인자로 모델과 함께 넘겨주면 한 분야에 특화된 lora 모델을 만들 수 있습니다.
lora는
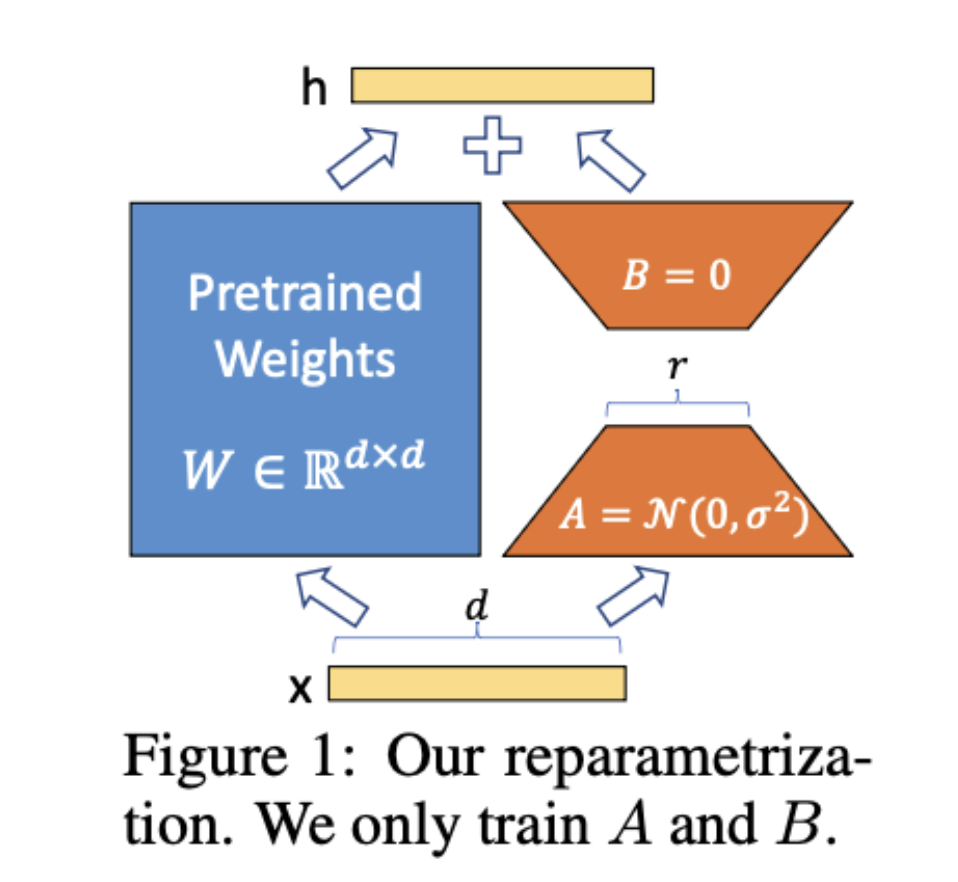
와 같은 구조를 가지고 있습니다.
왼쪽의 큰 파라미터는 freeze 시키고, 오른쪽에 r차원으로 줄였다가 다시 원래차원으로 돌리는 network를 구성해 파라미터 수를 적게 만들죠.
lora를 통해 구성된 모델은 적은 파라미터로 기존 모델과 비슷한 성능을 낼 수 있습니다.
이외에도 Quantization이라고 파라미터를 int8로 구성하여 파라미터의 용량을 줄이는 방법론도 이미 구현해 놔서 바로 쓸 수 있습니다.
3. Training
Hugging Face에서는 Trainer라고 모델의 학습을 간편하게 할 수 있도록 도와주는 모듈 또한 지원합니다.
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir = f"./results/{name}",
eval_strategy = "epoch",
save_strategy = 'epoch',
per_device_train_batch_size = batch_size,
per_device_eval_batch_size = batch_size,
num_train_epochs = epochs,
weight_decay = 0.01,
logging_dir = './logs',
logging_steps = 30,
report_to = "wandb",
run_name = run_name,
load_best_model_at_end = True,
metric_for_best_model = 'pearson')
trainer = Trainer(
model = model,
tokenizer = tokenizer,
args = training_args,
train_dataset = train_dataset,
eval_dataset = val_dataset,
compute_metrics = metric,
data_collator = data_collator,
)
trainer.train()처럼 Training arguments를 지정하고 이를 trainer에 넣어준 뒤 Trainer에 넣어주면 됩니다.
딕셔너리 형태로 반환하는 metric 함수를 만들어서 같이 넣어주면 평가 metric에 추가할 수도 있습니다.
optim.zero_grad()
x,y = batch
output = model(x)
loss = loss_fn(output, y)
loss.backward()
optim.step()
를 하나씩 작성할 필요 없이 하이퍼파라미터나 데이터셋 등을 지정하면 trainer.train()하나로 훈련할 수 있습니다.
Wandb나 Tensorboard같은 곳으로 로그를 보내 학습 상황을 살펴볼 수도 있습니다.
Accelerator을 통해 기존 모델을 분산 학습을 위한 모델로 바꿀 수도 있습니다.
from accelerate import Accelerator
accelerator - Accelerator()
train_loader, eval_loader, model, optimizer = accelerator.prepare(train_dataloader, eval_dataloader,model,optimizer)을 사용하면 모델을 분산 환경에서의 학습을 지원하는 모델로 바꿀 수 있습니다.
4. Evaluation
Hugging Face는 Accuracy, F1 score, roc auc score, pearson score, Rouge,BLEU score등의 평가 지표 계산 모듈을 지원합니다.
trainer의 compute_metrics 인자에 metric 함수를 만들어서 넣어주면 됩니다.
trainer는 evaluate할 때 preds와 정답 라벨을 쌍으로 넘겨줍니다.
따라서 label, pred = preds로 받아서 계산한 뒤 딕셔너리 {'acc' : accuracy, 'f1' : f1}의 형태로 넘겨주면 되겠습니다.
5. Pipeline
예를 들어봅시다.
우리가 감정 분석 Task를 한다고 쳤을 때, 학습한 모델이 잘 인식하는지를 알아보려면
Text를 쓰고 이를 토큰화해서 모델에 넣고 모델에서output이 나오면 그것을 softmax에 통과시키고 그 확률분포를 아유숨차
이런 과정을 한줄로 이룰 수 있도록 돕습니다.
from transformers import pipeline
classifier = pipeline('sentiment-analysis', model = your_model, tokenizere = your_tokenizer)
text = '나만 공부를 못해 난 망했어.'
print(classifier(text))
## (label : Negative, with_score : 0.99)
와 같이 구현할 수 있겠습니다.
'
'
'
'
허깅 페이스에 대해서 알아봤습니다.
거의 모델의 전 과정을 돕는다고 볼 수 있겠네요.
안쓰면 바보 아닐까요
일단 저는 바보긴 했습니다.
이제라도 잘 활용해봐야겠습니다.
시간이 지날수록 구현 능력보다 설계 능력이 중요해지는 오늘날에 살고 있는 듯 싶습니다.
창의성을 기르기 위해서는 책을 읽어야 한다던데 큰일입니다.
아무튼 읽어주셔서 감사합니다.

좋은 글 감사합니다! 많은 도움이 되었습니다.