반갑습니다.
저번 글에서는 NLP 모델을 활용하여 어떤 문제들을 풀 수 있는지에 대해서 설명드렸었는데요.
이번 글에서는 학습시킨 모델을 평가하기 위해 어떤 지표들이 쓰이는지 알아보겠습니다.
벤치마크는 크게 두 종류로 나눌 수 있습니다.
- NLP 모델을 상용화하여 실제 문제들을 해결할 수 있는지에 대한 평가 (Task base)
- 모델이 전체적인 문맥을 잘 알아먹는지에 대한 "언어이해" 평가 (Understanding base)
1번같은 경우에는 GLUE, Super GLUE, KLUE등이 있고
2번같은 경우에는 Massive Multitask Language Understanding(MMLU) 나 Chatbot arena 등이 있겠습니다.
Task-base
실생활에서 직면할 만한 다양한 Task 기반 데이터셋들입니다.
1. General Language Understanding Evaluation(GLUE)
아래와 같은 NLP 문장 또는 문장 쌍의 NLP Task들로 구분되어 있습니다.
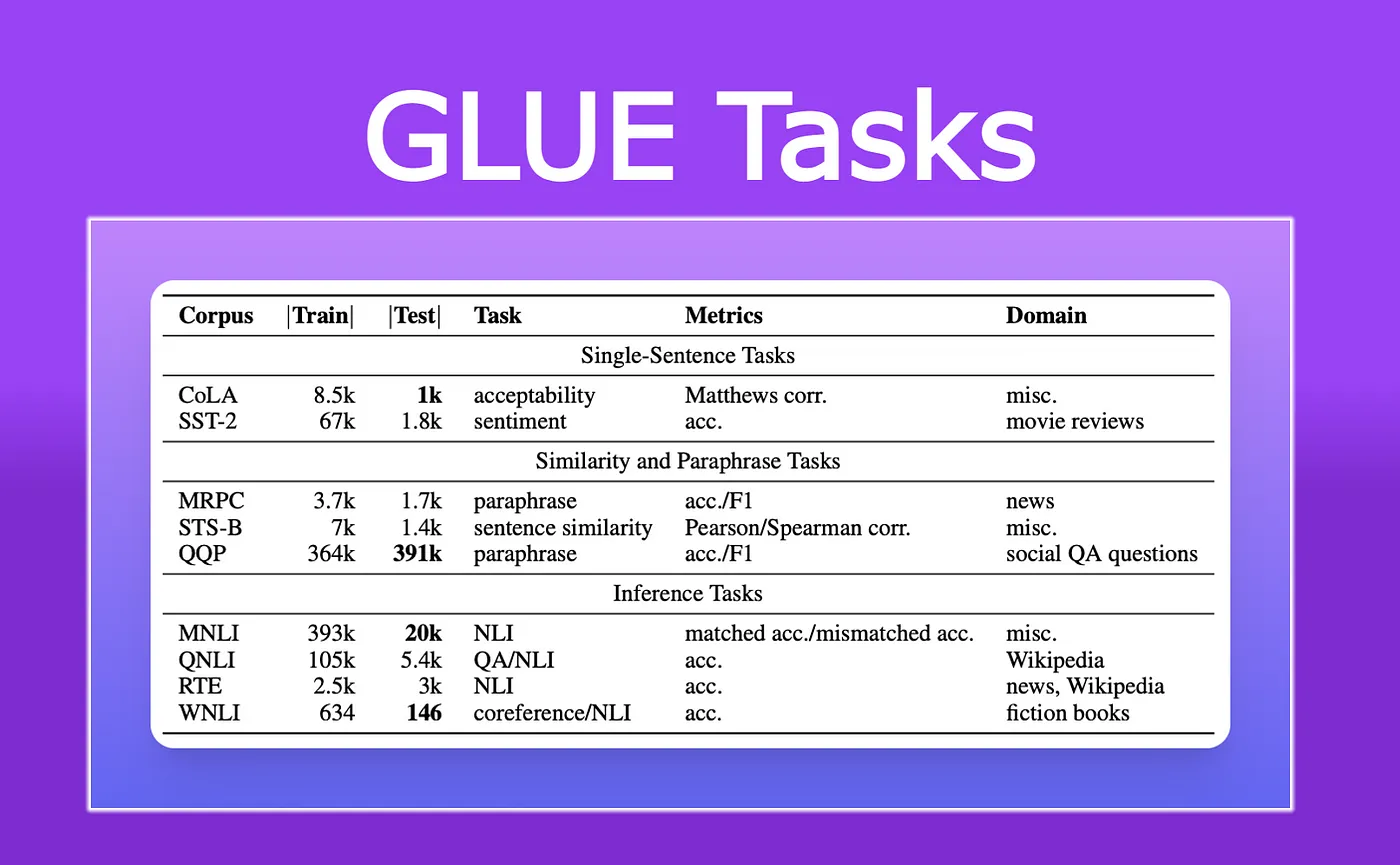
모든 데이터셋들은 N to 1 의 형태를 가지고 있습니다.
(문장 ~~ / label : ~)
2. Super GLUE
Super GLUE는 GLUE 다음에 나온 평가 데이터셋입니다.
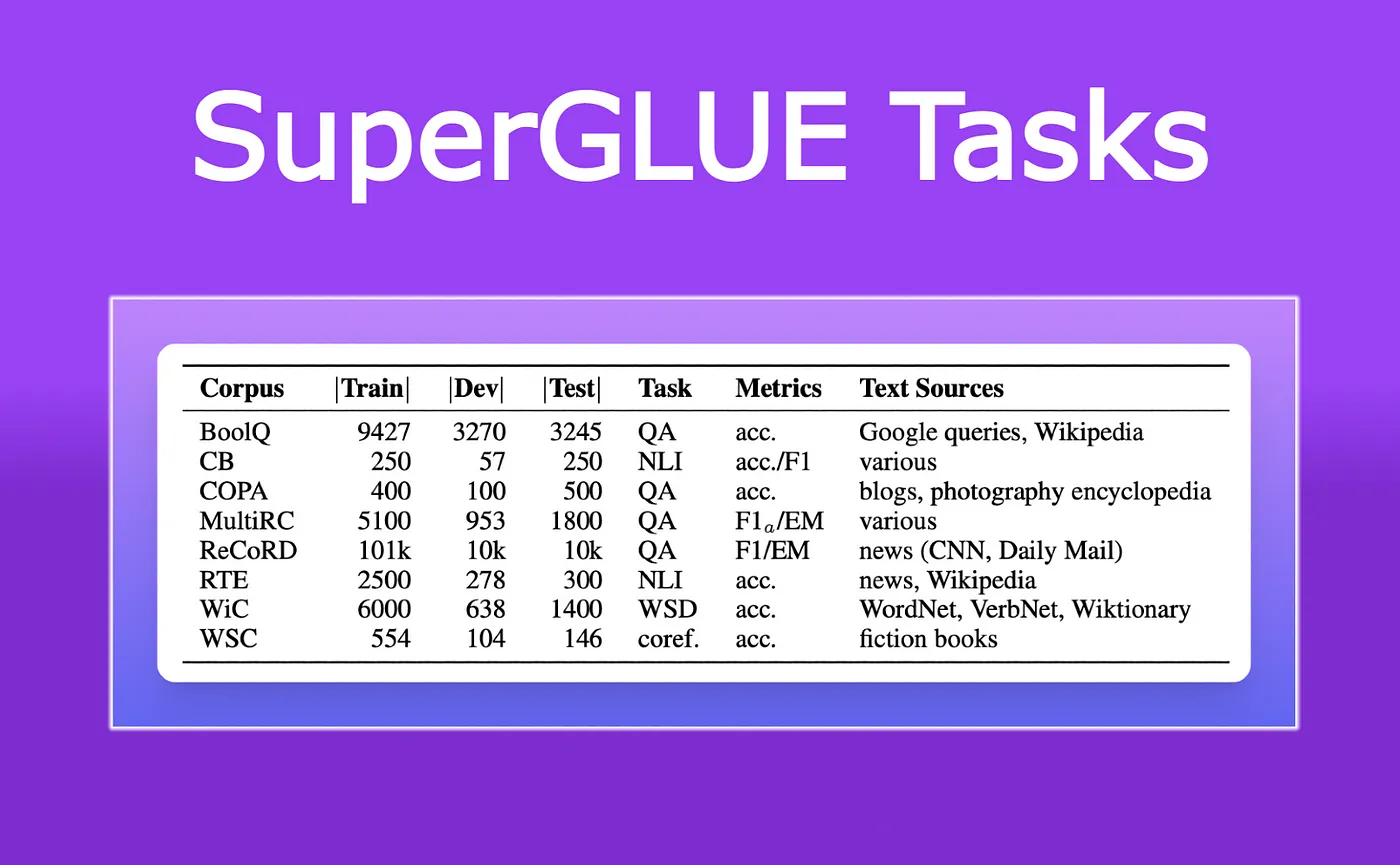
GLUE 데이터셋보다 조금 더 개선되고 어려운 내용을 담고 있습니다.
마찬가지로 대부분 N to 1 의 형태를 가지고 있지만 가운데 언저리에 RecoRD 데이터셋은 N to N 의 형태를 가지고 있습니다.
어떻게 생겼징
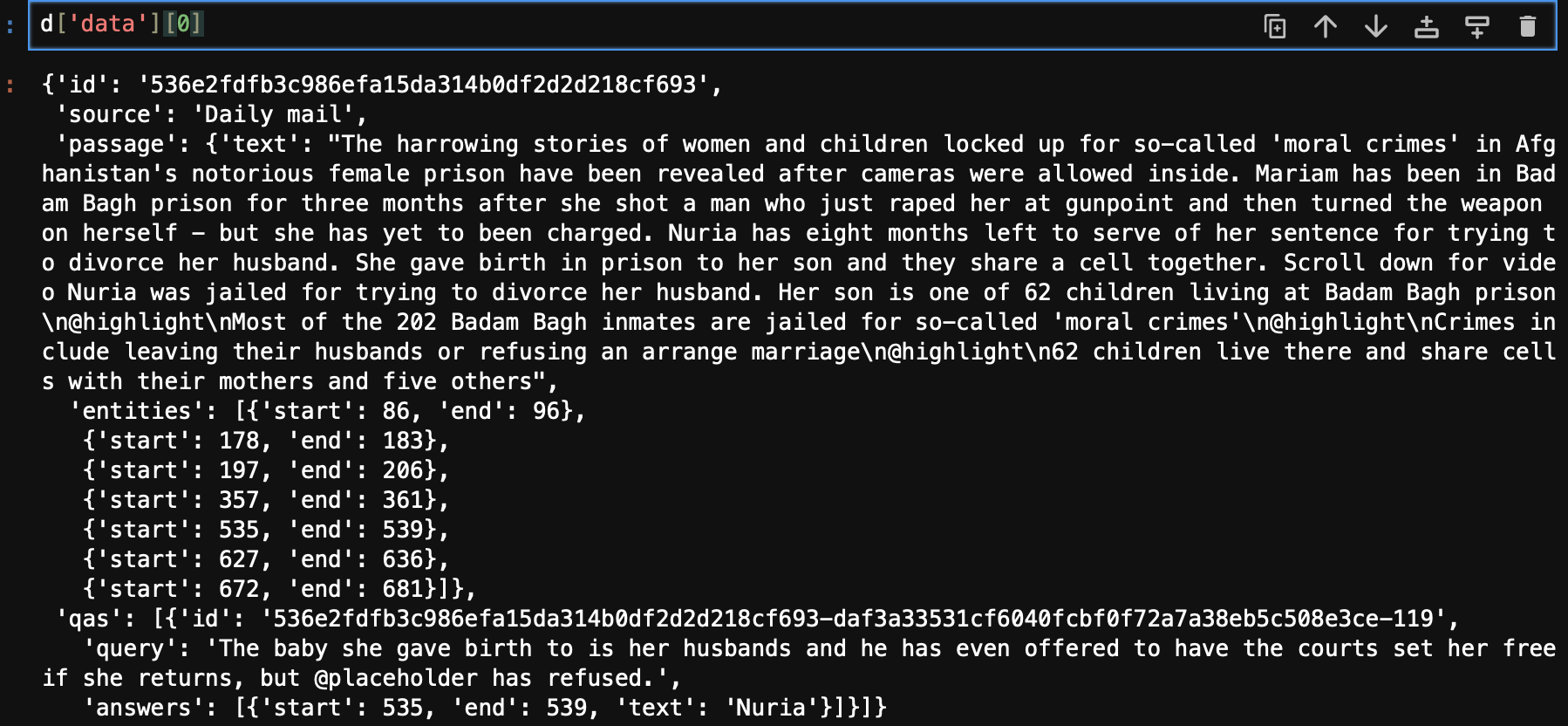
아하 ~ 본문과 질문, 질문에 대한 답으로 구성돼 있구나?
ㅎㅎ
3. KLUE
KLUE 는 GLUE의 한국어 버전이라고 보시면 되겠습니다.
대부분 N to 1의 형태를 가지고 있지만 N to N, N to M의 형태를 가진 데이터들도 포함돼 있습니다.
N to M의 형태는 어떻게 생겼을까요

아합 ㅎㅎ
Understanding base
실생활에서 적용할 수 있을만큼 자세한 분류를 하진 않았지만 모델의 일반적 언어 이해 능력들을 올릴 수 있는 dataset들입니다.
1. Massivce Multitask Language Understanding(MMLU)
MMLU는 모델이 지문의 내용을 잘 이해하는지를 평가할 수 있는 데이터셋입니다.
67개의 분야로 이루어져 있고 지문과 5지선다형 질문, 정답, 난이도, 카테고리로 이루어져 있습니다.
범용적인 언어 모델을 만들고자 한다면 MMLU를 적극 활용할 수 있겠습니다.
2. Chatbot arena
챗봇 아레나는 웹사이트 인데요.
생성형 언어모델의 평가는 쉽지 않습니다.
어떤게 더 좋은지에 대한 지표를 확실히 세울 수 없기 때문이죠.
"점심 메뉴 추천해줘."라는 질문을 던졌을 때 모델마다 다른 대답을 얻을 수 있습니다.
그런 대답들을 집단지성을 이용해서 많은 사람들이 뭐가 더 나은지를 고를 수 있게 해놓은 사이트입니다.
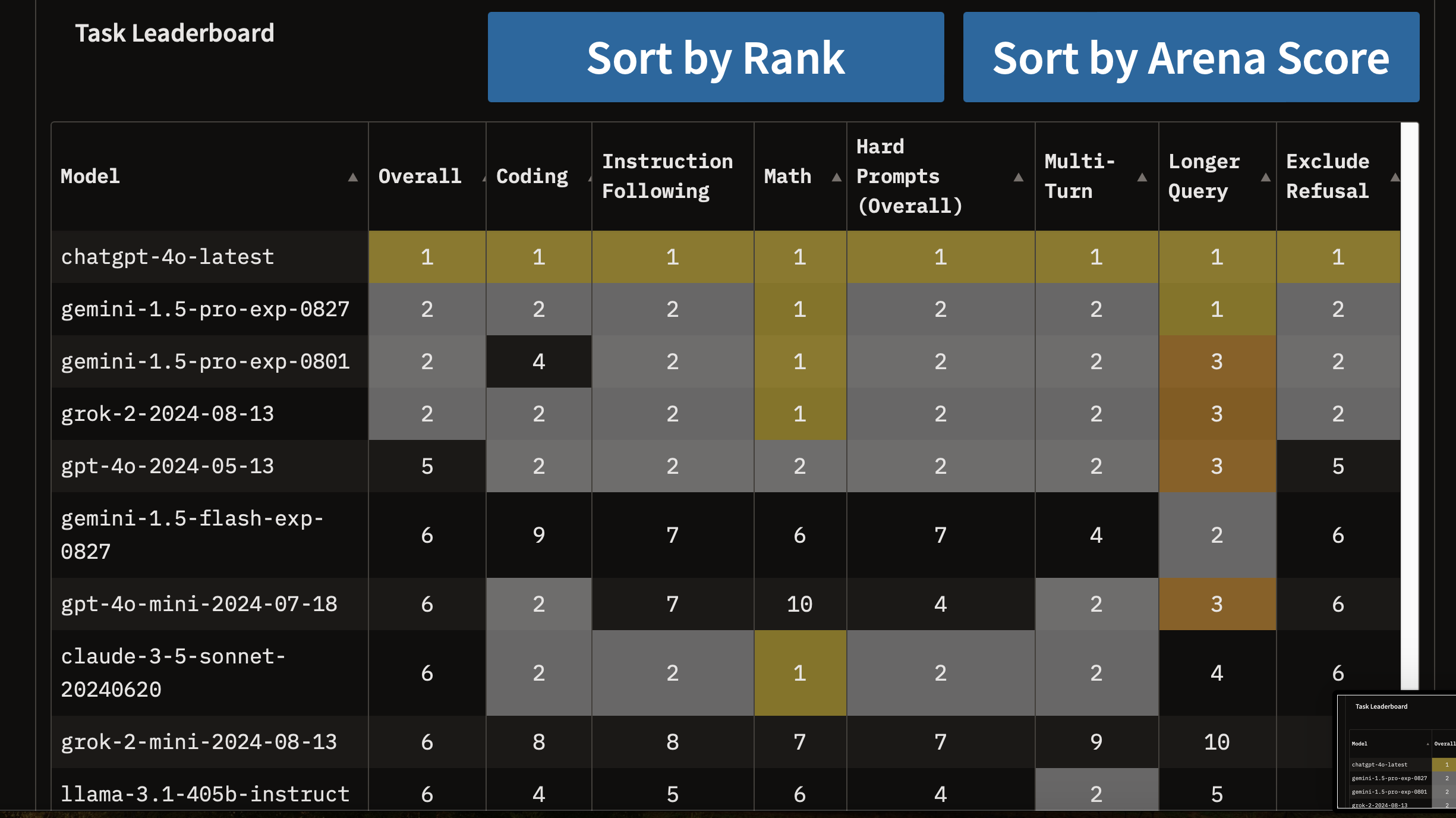
GPT가 만든 대답 VS Gemini가 만든 대답
이런식으로 떠서 사람들이 투표를 하면 그 결과가 리더보드에 반영됩니다.
지금은 GPT 4o가 압도적 일등이군요.
'
'
'
이로서 NLP 모델의 능력을 평가할 수 있는 대표적인 Benchmark들을 소개해봤습니다.
제가 소개한 데이터셋을 제외하고도 세상에는 아주 많은 기준과 지표가 있겠죠.
꼭 저 데이터셋을 이용해서 평가하지 않고도 신뢰성을 보장할 수 있다면 다양한 지표를 만들어서 상대방을 설득시킬 수 있겠습니다.
감사합니다 !~!~

nlp benchmark 논문 찾아보려고 검색했는데 이 글이 나왔어
세상 참 좁다