반갑습니다.
LLM의 Fine Tuning이 어떻게 이루어지는지, 다양한 기술들에 대해 적어볼까 합니다.
방법은 비교적 쉬운데 .. 좋은 결과를 내는 것은 어려운 것 같습니다.
Fine Tuning이란?
Pretrained 된 언어 모델을 소량의 데이터로 재학습시켜 본인이 풀고자 하는 문제에 대해 특화된 모델을 얻는 방법을 의미합니다.
특히, 많은 파라미터를 갖는 LLM은 개인이 직접 pretraining을 시키는 것에 많은 어려움을 가지므로 Fine Tuning을 하는 것이 적절한 선택이 될 수 있습니다.
여태까지 Bert 계열의 모델들의 Supervised Learning과 크게 다르지 않습니다.
다만 굳이 LLM Fine Tuning을 다른 카테고리처럼 묶어 표현하는 이유는 모델의 사이즈가 로컬에서 돌리는 데에 무리가 있기에 어떻게 하면 로컬에서 잘 돌릴 수 있을지에 대한 고민들이 추가됐기 때문입니다.
그럼 학습은 어떤 식으로 이루어질까요?
간단한 예제를 보겠습니다.
role : system : 지문을 읽고 질문의 답을 구하세요
role : user : data_template.format(지문, 질문, 선택지)
role : assistant : data['answer']위와 같은 템플릿을 적용하면
<|begin_of_text|><|begin_of_text|><|start_header_id|>system<|end_header_id|>
지문을 읽고 질문의 답을 구하세요.<|eot_id|><|start_header_id|>user<|end_header_id|>
지문 : ~~~
질문 : ~~
선택지 : 1. ~~ 2. ~~ 3. ~~ 4. ~~ 5. ~~
선택지 중 정답을 하나만 고르세요.
정답 :<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
1<|eot_id|>
이런 형태의 데이터가 나옵니다.
지문, 질문, 선택지, 정답은 풀고자 하는 데이터를 넣으면 되겠죠.
모델은 들어온 프롬프트를 바탕으로 뒷 내용을 추론합니다.
assistant에는 모델의 예상 답변을 넣어줍니다.
모델은 user가 제공한 문제를 읽고 가장 정답인 부분을 output으로 내보냅니다.
이후, assistant(예상답변)과 본인이 출력한 결과물의 logit을 cross entropy를 통해 loss를 계산한 뒤, backward 과정을 거칩니다.
즉, 정답이 1이면 logit은 [1,vocab_size] 크기의 확률 분포를 갖고, 그 중 1에 해당하는 부분만 100%인 것이고
모델의 출력 logit은 [1, vocab_size] 크기의 확률 분포인 것은 같지만, 다음에 나올 단어 확률이 [[0.01, 0.03, 0.01, ...]]과 같은 확률 분포가 되는 것입니다.
두 확률 사이의 loss를 계산한 뒤 backward 한다고 생각하시면 되겠습니다.
프롬프트라는 것은.. 결국 문맥이라고 생각하시면 됩니다.
LLM은 다양한 글자로 이루어진 text를 바탕으로 그 다음에 나올 text를 추론하는 방식으로 훈련됩니다.
LLM을 활용하려면 마찬가지로 한 문맥을 입력으로 주고 원하고자 하는 정답을 추론하게 하면 되겠습니다.
문맥을 누가봐도 이해하기 쉽고 간결하면서 필요한 내용을 출력하도록 하는 것이 Prompt Engineering이 되겠습니다.
간단히 학습 과정에 대해서 살펴봤는데요.
LLM의 파라미터 단위는 B(십억)입니다.
모든 파라미터를 backward하는 것은 아주아주 많은 시간과 비용이 들게 되지요.
그래서 일반적으로 LLM Fine Tuning에는 PEFT라는 것을 활용합니다.
PEFT?
PEFT(Parameter Efficient Fine Tuning)이란, LLM의 모든 파라미터를 update하지 않고 전체 파라미터의 소량만 학습하여 Fine Tuning하는 방법을 의미합니다.
PEFT는 pruning, distillation, LoRA, prompt tuning 등 다양한 방법이 있지만, 이번 글에서는 LLM Fine Tuning에서 일반적으로 많이 사용되는 LoRA, Prompt tuning에 대해서 설명합니다.
1. LoRA (Low Rank Adaption)
LLM의 Parameter는 Freeze 한 뒤, 모델의 양 끝단에 학습 가능한 파라미터를 구성해 학습을 진행하는 방법입니다.
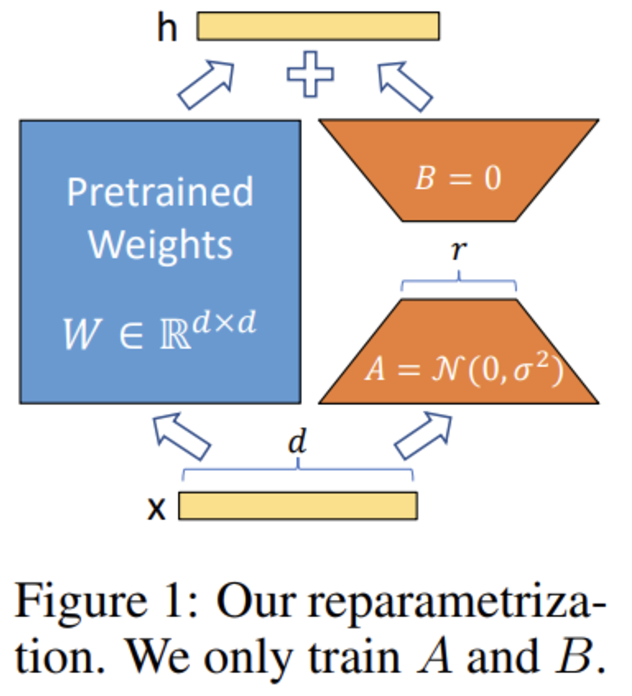
사진을 통해 확인하는 것이 더 이해가 쉬울 듯 합니다.
작전이 뭐냐
model은 Freeze시키고 오른쪽에 nn.Linear layer를 구성합니다.
이 레이어만 학습 가능하도록 한 뒤 마지막에 합쳐 원래 LLM의 output shape로 맞춰 내보냅니다.
위와 같은 방법은 아주 소량의 파라미터들로도 LLM의 성능 손실을 최소화 시키면서 한 Task에 전문성을 갖도록 할 수 있습니다.
가만 생각해보면 분류, 요약, 채팅 등에 특화된 LLM 3개를 만드는 것 보다 일반적으로 다 잘하는 LLM을 하나 만든 뒤, Lora adaptor를 3개 만드는 것이 훨씬 효율적입니다.
LoRA에서 발전된 QLoRA라는 방법도 있습니다.
2. QLoRA
RoLA 방법론을 그대로 적용하되, 모델의 Parameter을 Quantization합니다. Quantization은 6bit, 8bit, 16bit 등으로 구성할 수 있습니다.
QLoRA는 간단히 말하면 LoRA에 Quantization까지 하겠다는 의미입니다.
모델의 파라미터 용량이 줄어들어 더 메모리 효율적인 학습이 가능합니다.
다만 Quantization의 정도가 심할수록 원래 LLM이 갖고 있던 능력의 정밀도가 떨어질 수 있겠습니다.
LoRA 적용법
코드로 살펴보겠습니다.
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # QLoRA는 4bit 양자화를 사용
bnb_4bit_compute_dtype=torch.float16, # 계산 precision (float16 또는 bfloat16 사용 가능)
bnb_4bit_use_double_quant=True, # 이중 양자화 활성화
bnb_4bit_quant_type="nf4" # NF4 양자화 타입
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config, # BitsAndBytesConfig 추가
device_map="auto",
)Quantization은 위와 같이 간단한 config를 작성하여 모델을 불러올 때 적용할 수 있습니다.
- load_in_4bit, 6bit, 8bit, 16bit 등은 모델을 가져올 크기를 의미합니다.
- bnb_4bit_compute_dtype은 모델이 계산을 수행할 때 dtype을 어떤 것으로 할 건지 정합니다. torch.bfloat16: bfloat16은 float16과 비슷하지만, 더 넓은 표현 범위를 가진다고 하는데, 최신 하드웨어 (A100, H100)에서만 사용이 가능하다고 하네요.
- bnb_4bit_use_double_quant는 이중 양자화를 의미합니다. 압축된 가중치를 한번 더 압축합니다.
- bnb_4bit_quant_type은 4비트로 양자화 된 데이터를 어떻게 표현할 것인지 정합니다. fp4(float 4)는 일반적인 부동소수점 표현이고, nf4(normalized float 4)는 4비트 정규화 부동소수점 표현입니다.
QLoRA에서는 nf4가 더 좋다고 알려져서 표준이라고 하네요.
from peft import get_peft_model, LoraConfig
peft_config = LoraConfig(
r=32,
lora_alpha=64,
lora_dropout=0.05,
target_modules=['q_proj', 'v_proj', 'k_proj', 'o_proj'],
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(self.model, peft_config)위 과정을 통해
LLM을 LoRA 모델로 바꿀 수 있습니다.
from trl import SFTTrainer, DataCollatorForCompletionOnlyLM, SFTConfig
sft_config = SFTConfig(
do_train=True,
do_eval=True,
lr_scheduler_type="cosine",
max_seq_length=2048,
output_dir="outputs_gemma",
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
per_device_eval_batch_size=1,
num_train_epochs=3,
learning_rate=1e-5,
weight_decay=0.01,
logging_steps=1,
save_strategy="epoch",
eval_strategy="epoch",
save_total_limit=2,
save_only_model=True,
report_to="none",
)
trainer = SFTTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
preprocess_logits_for_metrics=preprocess_logits_for_metrics,
peft_config=peft_config,
args=sft_config,
)이런식으로 peft_config = peft_config를 통해 넣는 방법으로도 구현할 수 있습니다.
SFTTrainer(SupervisedFineTuningTrainer)은 지도학습을 위한 Trainer입니다.
일반 Trainer는 모델을 처음부터 학습하거나 Workflow의 Customizing이 필요할 때 많이 사용되지만 SFTTrainer은 소량의 데이터셋으로 Finetuning할 때 사용됩니다. 또, peft_config를 기본적으로 지원하니 위와 같은 방식으로 구현해도 좋겠습니다.
3. Prompt Tuning
Prompt Tuning이란 대규모 사전 학습된 언어 모델(Pre-trained Language Model, PLM)에서 파라미터를 고정한 상태로, 작은 크기의 프롬프트를 학습하여 특정 작업(Task)에 적응시키는 기법입니다. 모델의 원래 가중치는 변경하지 않고, 입력 데이터에 추가하는 프롬프트 텍스트(혹은 임베딩)를 학습합니다.
Prompt Tuning은 모델의 가중치를 전부 Freeze한 뒤, Prompt text를 학습하는 모듈입니다.
의도가 뭐냐면 모델의 성능을 최대한 끌어올릴 수 있는 프롬프트를 만들도록 파라미터를 추가하는 것이지요.
가령 Prompt를
"나는 오늘 밥을 먹었고 어제는 ...이 문장을 요약해 줘."
라고 나왔다면
Prompt Tuning이 탑재된 모델은
"[Summarize : 나는 오늘 밥을 먹었고 어제는...]"
이런 식의 문장으로 바꿔서 모델에 입력으로 넣습니다.
어떻게 보면 프롬프트 엔지니어링을 좀 더 AI를 활용해서 하는 느낌인 것 같습니다.
'
'
'
이렇게 LLM Fine Tuning에 대해서 살펴봤습니다.
방법은 쉽지만 PEFT를 통해서 학습을 하더라도 몇시간 이상 걸립니다.
결과를 확인하는 데에 몇시간이 걸리니 디버깅이 쉽지 않습니다.
디버깅을 적게 하기 위해서는 이론을 탄탄히 배우는 것이 중요하겠습니다.
감사합니다 !
