반갑습니다.
Llama3.2에서 사용된 기술들에 대해 소개해볼까 합니다.
물론 몰라도 huggingface에서 불러오고 잘 사용할 수 있지만..
알고 모르고의 차이는 크다고 생각합니다.
아무래도 개념이다보니까 어려운 부분이 많은데.. 잘 공부해서 설명해보겠습니다.
Transformer과 Llama의 차이
처음 공개된 Transformer과 최근에 공개된 오픈소스 LLM Llama의 차이는 뭘까요
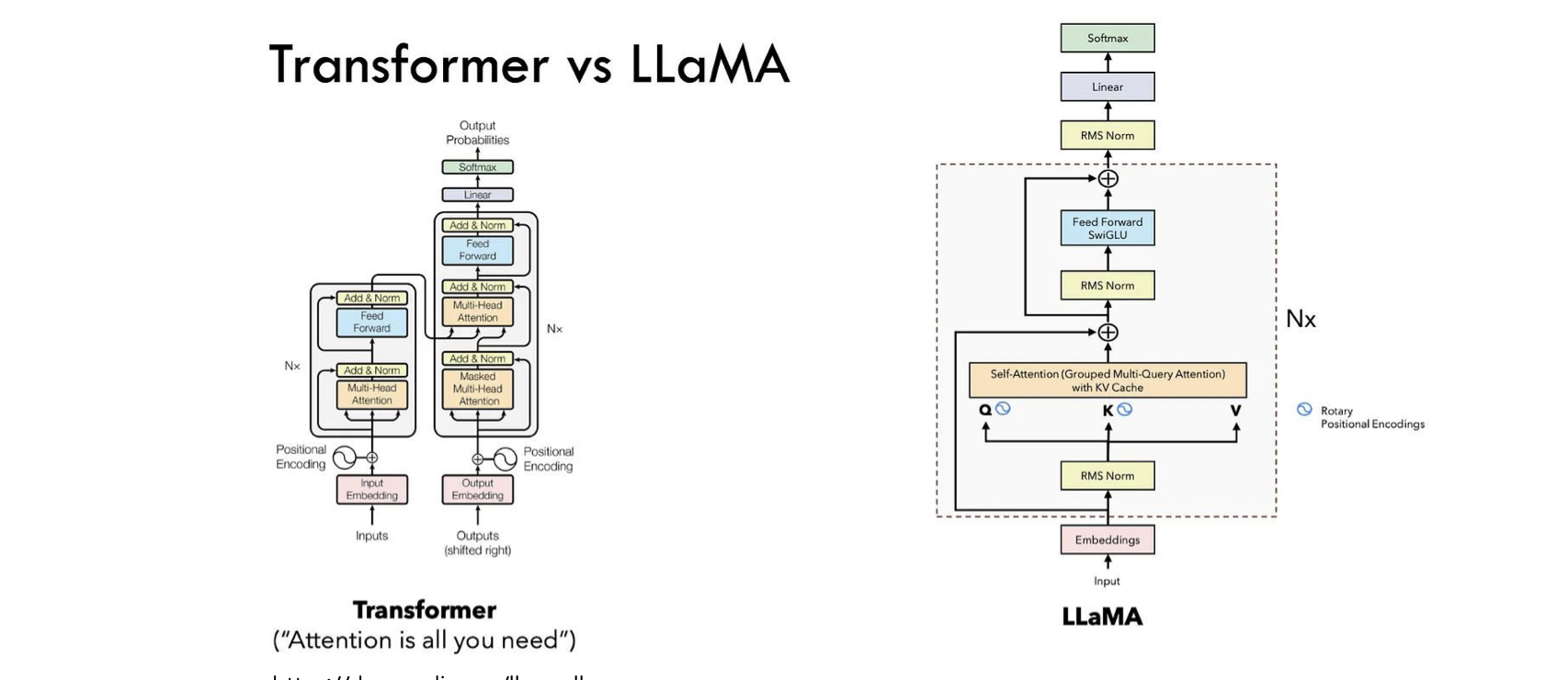
위 사진에서 자세히 살펴볼 수 있습니다.
일단 Transformer는 Encoder-Decoder 구조이고, Llama는 Decoder-only구조인 것을 알 수 있습니다.
그 외에도 Llama에는
- Rotary Positional Embedding
- Multi-head attention
- RMS Norm (Root Mean Square Normalization)
- Flash Attention 2
라는 기술들이 적용되었습니다.
하나하나 살펴보겠습니다.
1. Rotary Positional Embedding
Rotary Positional Embedding (RoPE)은 토큰 간 위치 정보를 각 토큰의 임베딩에 회전 변환을 적용하여 추가하는 방식입니다. 이 방식은 토큰 순서를 표현하면서도 각 토큰을 독립적으로 처리할 수 있게 하며, 특히 시계열 데이터나 길이가 변하는 입력 처리에서 유용합니다.
주의깊게 봐야 할 부분은 회전변환, 길이가 변하는 입력 처리입니다.
기존의 Positional Embedding은 위치 정보를 갖지 않는 Transformer 구조에서 임베딩에 위치 정보를 추가하기 위해 더하는 일종의 상수였습니다.
하지만 여러가지 문제점이 존재했는데
- 상대적인 위치 표현의 어려움
각 단어의 위치가 어디에 있는지는 알려주지만 단어간의 거리 차를 알지 못합니다.
(1,2,3,4가 아닌 가나다라, ㄱㄴㄷㄹ 같은 느낌임) - 단어 길이의 확장성
토큰 길이가 512자로 제한됩니다. 513자 이상의 토큰 길이가 입력으로 들어올 경우, 모델이 제대로 알아먹지 못하는 문제점이 존재했습니다. - 위치 정보가 뚜렷하지 않음
기존의 Positional Embedding은 모델의 입력 제일 첫 부분에 더해져서 들어가다보니 layer를 지날수록 위치 정보가 뚜렷해지지 않는 단점이 존재했습니다.
이러한 부분들을 개선하기 위해 등장한 Rotary Embedding입니다.
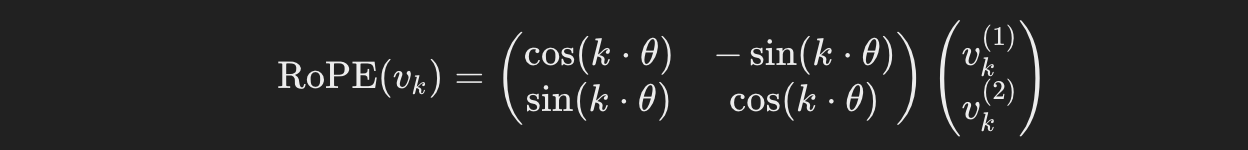
위 식은 회전변환 식과 일치합니다.
Rotary Embedding은 원 위에서의 점이라고 생각하시면 됩니다.
그르니까 원 위의 한 점을 각도를 변환시키면서 한바퀴 돌리는 것이지요.
만약 360도를 10000개로 쪼갰다면 10000개의 sequence length를 커버할 수 있고, 20000개 30000개처럼 맘대로 나눌 수 있겠습니다.
RoPE를 사용하면 단어 길이를 맘대로 정할 수 있고, 두 토큰 사이의 위치가 각도로 맺어져 있기에 상대적인 위치 차이 정보도 함께 표현할 수 있습니다.
또, Transformer 에서는 제일 처음 부분에 Positional Embedding을 더하는 방식이었지만, Llama3.2에서는 매 Attention연산의 앞 과정마다 RoPE를 더하여(정확히는 Q와 K에만) Layer를 지나면서도 위치 정보를 보존하도록 하였습니다.
짱이군요 ㅎㅎ
2. Multi head Attention
토큰 길이만큼의 Q와 K를 곱하는 대신, 토큰 길이를 분할하여 Attention을 수행한 뒤, Concat하여 연산량을 줄이는 방법입니다.
예를 들어봅시다.
4000개의 길이를 갖는 Q, K, V가 있다고 해보면
어텐션 연산에서 의 연산량을 갖게 됩니다.
이를 10개로 쪼개면
4000 / 10 = 400
으로 바꿀 수 있습니다.
계산해보니 약 16000000 : 160000으로, 100배정도 차이가 나는군요. 연산을 많이 줄일 수 있는 방법이 되겠습니다.
여기서끝이아니다
Grouped Query Attention이라는 방법 또한 쓰이는데,
이는 Multi Head Attention에서 몇몇개의 Head를 독립적으로 구성하는 것이 아니라 Query 공간을 묶어서 사용해보니 연산량은 줄면서 성능이 비슷하더라
그래서 효율적이더라 라는 연구결과를 바탕으로 고안된 방법입니다.
즉 Head 별 Query (512, 768)의 벡터를 각각의 헤드에서 다 구하는 것이 아닌, 한 Query 벡터를 그대로 사용하는 방법입니다.
GQA는 모델 크기별로 적용되기도 하고 적용되지 않기도 한다고 합니다.
아무래도 성능이 비슷하긴 하지만 약간의 하락이 있을 수 밖에 없기 때문인 듯 합니다.
경량화 모델에서 많이 쓰이는 방법이 되겠습니다.
3. RMS Norm
RMS Norm(Root Mean Square Normalization은 Batch Norm과 Layer Norm에 비해 더 간소화된 정규화 방법론입니다.
RMS Norm은 다른 정규화 방법에 비해 속도가 빠르고 대형 모델에 적합합니다.
Batch Norm이나 Layer Norm은 많이들 들어보셨겠지만 RMS Norm은 아마 좀 생소할 수 있다고 생각합니다.
일단 저는 처음 봤거든요. ㅎㅎ
왜 RMS Norm이 속도가 빠르고 대형 모델에 적합할까요
RMS Normalization(RMSNorm)이 계산이 더 빠른 이유는 평균을 계산하지 않고 루트 평균 제곱(RMS)만을 사용해 정규화하기 때문입니다. 일반적으로 평균과 분산 계산이 추가적인 연산을 필요로 하는 반면, RMSNorm은 각 입력의 제곱을 합해 RMS를 계산하므로 연산 비용이 줄어듭니다.
또, BN이나 LN은 평균과 분산을 계산하기 위해 파라미터로서 반드시 저장해두어야하는데, RMS Norm은 그럴 필요가 없다고 합니다.
더 자세히 알고 싶은데 .. 잘 이해가 안되는군요 ㅠ
혹시라도 설명해주실 분이 계시다면 감사히 배우겠습니다.
4. Flash Attention2
Flash Attention이란, Attention 메커니즘 중 하나입니다.
Flash Attention은 1, 2, 3 세가지 버전이 존재하며, 일반적으로 3은 기업 단위에서 사용하기에 2가 널리 사용됩니다.
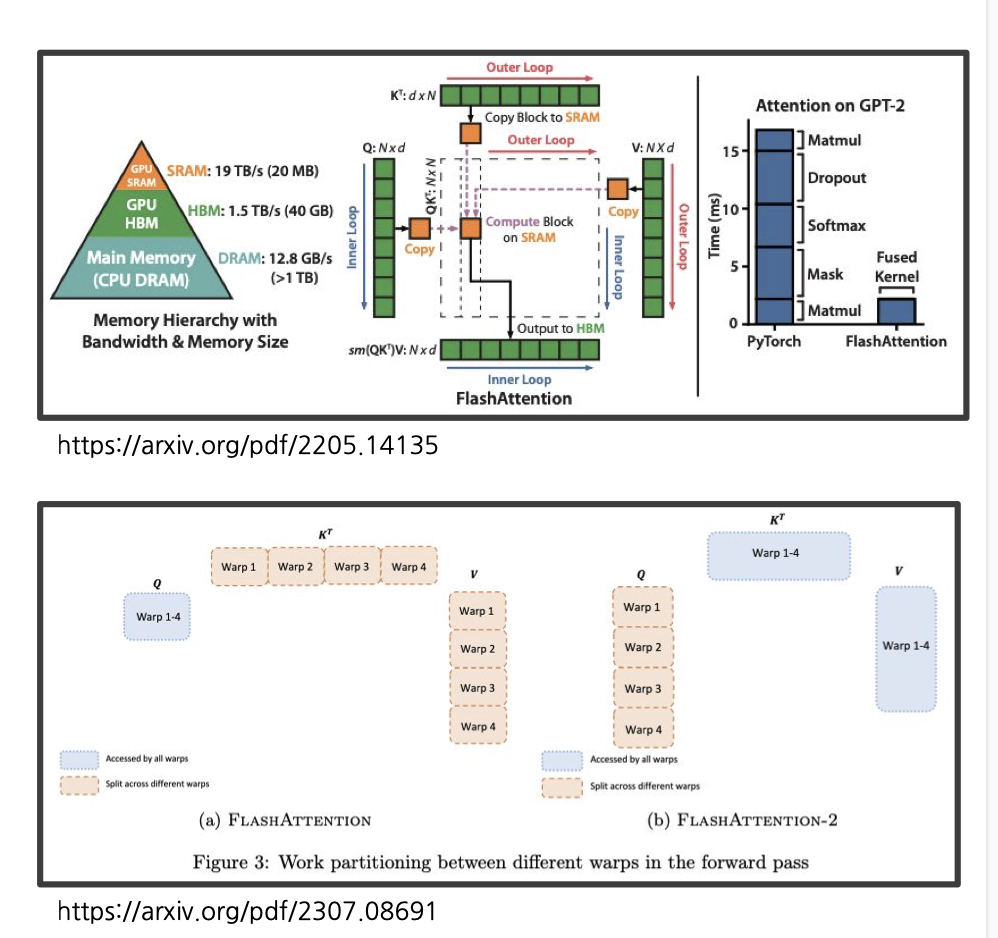
위는 Flash Attention1, 2를 설명한 그림입니다.
왼쪽 위의 피라미드를 보시면 GPU는 총 세가지로 이루어져있습니다.
SRAM (GPU의 연산을 담당하는 아주 작은 램)
HBM (VRAM이라고 불리는 것)
DRAM (우리가 램이라고 부르는 것. DDR3,4같은거)
우리가 큰 모델을 올려서 훈련을 시킬 때 GPU는 Attention 과정에서 Q와 K를 HBM에서 SRAM으로 올려 작업을 수행하게 됩니다.
Flash attention1은 이때 HBM과 SRAM이 왔다갔다 하는 작업을 최소한으로 줄여 속도를 극대화시킨 방법입니다.
이 방법에는 Tiling과 Recomputation 방법이 사용된다고 하는군요.
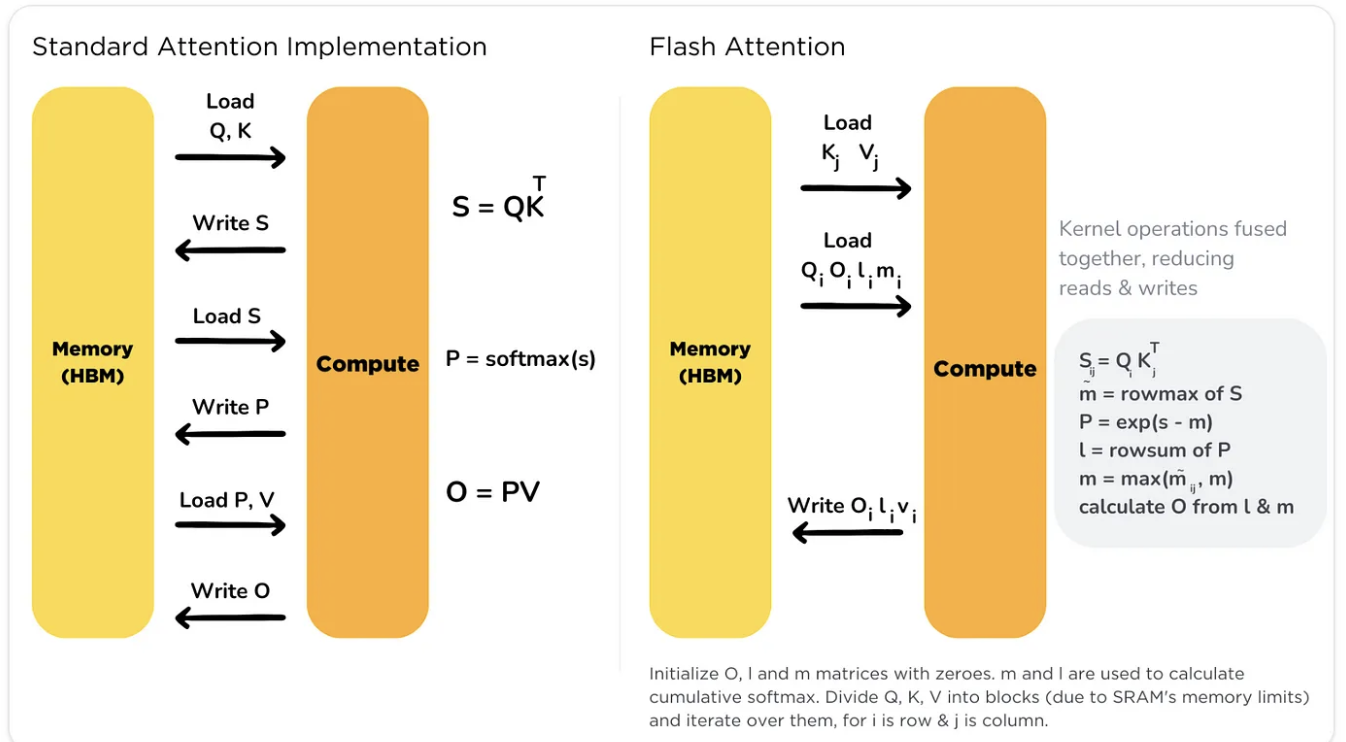
위 그림처럼 Flash Attention은 기존 Attention 연산과 달리 데이터를 저장하고 로드하는 횟수를 많이 줄여 속도를 개선했습니다.
또 Flash Attention1의 오른쪽에서 Kernel fusion이라는 기술을 볼 수 있습니다.
이는 Matmul, Dropout, Softmax, Mask, Matmul이라는 다섯개의 과정을 하나하나 불러오는 것이 아니라 하나의 연산으로 합쳐서 만든 학습 전용 Custom Kernel을 사용하는 방법입니다.
이를 통해 약 5배 이상의 속도 향상이 있었다고 하는군요.
Flash Attention2는 기존 1의 방식과 더불어 Q를 fix하고 KV를 왔다갔다 하는 연산 방법에서 K와 V를 fix하고 Q를 왔다갔다 하는 연산 방법으로 바꿔 속도를 향상시킨 방법입니다.
Llama 3.2에서는 Flash Attention 라이브러리를 통해 불러오는 방법으로 구현되어있습니다.
외주를 맡긴거죠 ㅎㅎ
'
'
'
이로서 Llama3.2와 고전적인 Transformer 모델의 비교를 통해 최신 LLM은 어떻게 구현되는지에 대해 알아봤습니다.
많이 어렵군요 ....
이 부분은 나중에 추가적으로 보충할 필요가 있겠습니다.
더 공부하게 되면 글을 수정해보겠습니다.
감사합니다 !
