반갑습니다
LLM의 Knowledge Update와 RAG에 대해 알아볼까 합니다.
엥 그냥 새 데이터가 생길때마다 추가학습 시키면 되는거 아닌가요?
그렇지않더군요.
살펴보겠습니다.
Temporal Misalignment
LLM이 새로운 지식을 배우지 못하여 발생하는 문제들을 의미합니다.
LLM은 최신 정보를 모릅니다.
왜냐하면 대규모 Pretraining, Fine-Tuning, Alignment Tuning 등은 한 시점에서 이루어지고, 그 데이터들은 미래의 데이터를 포함하고 있지 않기 때문입니다.
2024년 12월 3월에 이루어진 비상계엄 사태에 대해서는 GPT는 알지 못하죠. 예전의 데이터로 학습된 모델이기 때문입니다.
혹은 '미국의 현재 대통령은 누구야?' 라는 질문은 시간에 따라 달라지기에 모델이 정확한 대답을 하지 못할 가능성이 있습니다.
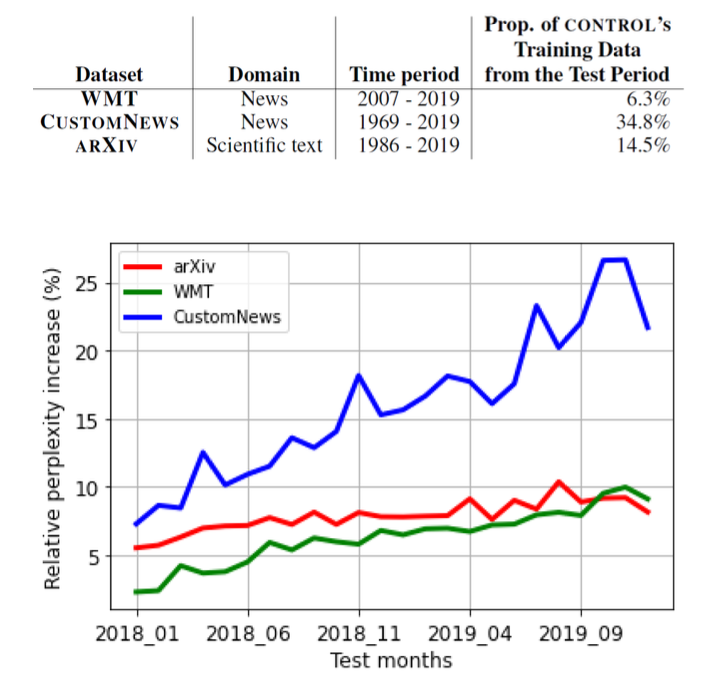
Lazaridouet al., “ Mind the Gap: Assessing Temporal Generalization in Neural Language Models”
, NeurIPS , 2021
실험군 : 2017/9월까지의 학습 텍스트 자료
대조군 : 2019까지의 학습 텍스트 자료
평가 데이터 : 2018~2019 기간의 텍스트
로 실험을 진행했을 때,
대조군 모델 대비 실험군 모델의 Perplexity(혼란도)가 모든 데이터셋에서 상당히 증가한 것을 살펴볼 수 있습니다.
그렇다면 다시 돌아와서, 매번 새로운 데이터를 학습하면 되는게 아니냐 ?
Catastrohic Forgetting 문제가 발생합니다.
Catastrophic Forgetting
여러 태스크를 순차적으로 배울 경우, 앞선 태스크에서 학습한 정보를 잊어버리는 문제를 의미합니다.
예를 들어, CIFAR 10 이미지 분류에 대해서 학습한 모델이 이후 MNIST 태스크에 대해 추가 Fine-Tuning하게 되면, 그 전에 맞췄던 문제도 못맞추는 상황이 발생합니다.
따라서 모델은 최신 지식을 학습하면서 과거 정보를 기억하는 것이 중요합니다.
대표적인 해결 방법은 두가지가 있습니다.
- Continual Learning
- Retrieval-Augumentd Generation
두가지에 대해 자세히 살펴봅시다.
Continual Learning
이전 학습 데이터를 잊지 않으면서 새로운 과제/데이터를 학습하는 학습 기법을 의미합니다.
다양한 방법들이 있습니다.
1. Regularization method
추가학습 시 기존 파라미터에서 벗어나지 않도록 Regularization을 적용합니다.
Rec-Adam, EWC(Elastic Weight Colsolidation) 등을 활용합니다.
파라미터를 업데이트 할 때
라는 로스를 활용합니다.
기존의 로스와 더불어서 현재 파라미터와 업데이트하고자 하는 파라미터와 L2거리를 최소화하는 Regularization을 추가로 더하겠다는 의미지요.
EWC는 Fisher라는 정보 행렬을 계산하여 Output에 영향을 많이 미치는 파라미터들을 찾아 부분을 채운다고 하는군요.
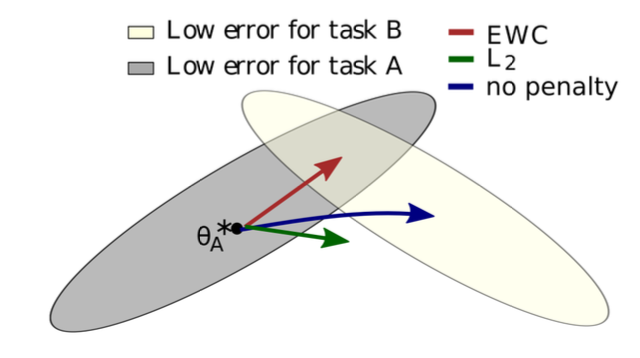
위처럼 기존 확률분포를 지키면서 새로운 확률분포를 따라가도록 학습합니다.
2. Parameter expansion method
원래의 매개변수는 고정하고, 특정 지식/Task를 다루는 모듈을 모델에 추가해서 학습합니다.
LoRA와 Adapter가 있습니다.
LoRA, Adapter 모두 기존의 모델은 냅두고 새로운 파라미터를 학습시켜 특정 Task에 맞게 붙였다 뗐다 할 수 있습니다.
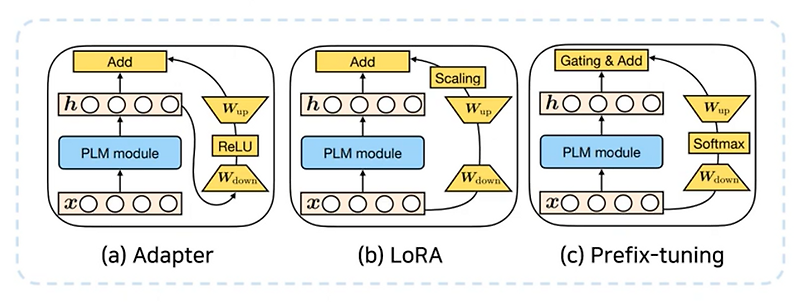
Adapter는 Hidden Layer 이후에 추가적인 Layer을 통과합니다.
LoRA는 기존의 Input Output 구조에 병렬로 추가 Layer을 붙여 속도 지연이 없도록 하고, 비선형 함수를 사용하지 않습니다.(이미 PLM Model이 비선형성을 충분히 표현한다고 판단하기 때문)
3. Rehearsal method
추가학습을 진행할 때, 과거 데이터를 샘플링하여 함께 학습하는 방법입니다.
Mix-review라는 방법론이 있습니다.
로 계산됩니다.
L2 regularization과 같은 Weight Decay 방법들은 Fine-Tuning할수록 사전학습 데이터의 Negative Log-Likelihood가 올라가는 반면, Mix-Review는 Fine-Tuning을 해도 사전학습 데이터의 NLL을 유지할 수 있다고 하네요.
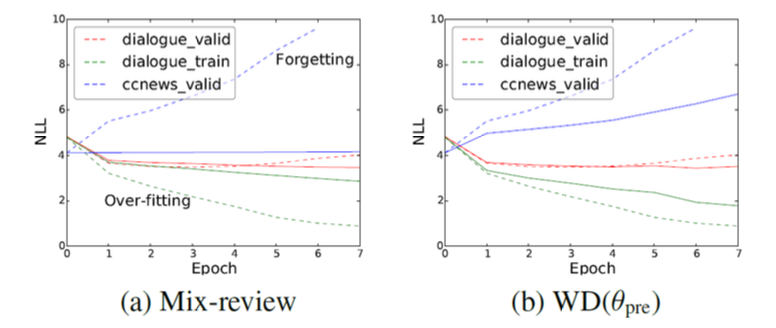
He et al. “Analyzing the Forgetting Problem in the Pretrain-Finetuning of Dialogue Response Models”. EACL. 2021.
위 그림처럼 기존의 Regularization 방법보다 더 나은 지식 보존 성능을 보여줍니다.
다만 Fine-Tuning Loss 뿐만 아니라 Pretrain Loss(MLM, NSP)도 계산해야 하기에 계산 비용이 많이 든다는 단점이 존재하겠습니다.
'
'
'
이처럼 다양한 Continual Learning 방법이 있지만, 아무리 기존 지식을 잘 보존하면서 새롭게 생기는 데이터를 학습한다고 해도 LLM을 학습시키는 것은 너무 비용이 많이 드는 작업입니다.
아무리 짧은 시간 간격을 두고 학습해도 한시간 전의 야구경기 결과, 십분전의 비상계엄 이런 지식들은 습득할 수 없겠죠.
또, RLHF나 DPO 등으로 Alignment Tuning이 끝난 모델에 Continual Learning을 진행하면 Alignment에 영향이 존재할수도 있습니다.
뭔가 찝찝한 부분이 많죠.
그래서 등장한 참신한 방법이 있습니다.
Retrieval-Augumetned Generation
모델이 생성할 때, 외부 정보를 Prompt로 추가 제공하여 결과를 출력하는 방법을 의미합니다.
그러니까 ..
외부 검색 엔진을 활용하는 것입니다.
외부 검색 엔진은 회사 내의 Closed DB가 될 수도 있고, Google, 네이버의 검색 엔진이 될 수도 있습니다.
그렇다면 프롬프트가 어떻게 구성될까요
Q. 현재 비상 계엄이 핫한 이유를 알려줘.
라는 쿼리가 들어오면
검색엔진을 통해 실시간 뉴스 같은 글을 두세개 가져옵니다.
[윤석열 대통령 비상계엄 관련 기사 1]...
[관련기사 2]...
[관련기사 3]...
그렇다면 모델은 내부에서 이런 쿼리를 받게 됩니다.
<주어진 글의 내용을 참고하여 질문에 대답을 하세요.>
[관련기사 1, 관련기사 2, 관련기사 3]
현재 비상 계엄이 핫한 이유를 알려줘.
이렇게 입력으로 준다면 모델은 현재 상황을 알지 못하더라도 사실에 기반한 정보를 전달할 수 있게 됩니다.
즉, Temporal alignment와 Hallucination문제를 해결할 수 있게 되는것이지요.
RAG를 위해 쓰이는 Retreival의 종류는 다양하게 있습니다.
밀집 벡터를 사용할 수도 있고,
https://velog.io/@yongari/Retrieval이-뭘까-Dense-retrieval
희소 벡터를 사용할 수도 있죠.
https://velog.io/@yongari/Retrieval이-뭘까
또, RAG를 사용하면 참고한 문서들이 웹페이지라면, 주소를 같이 첨부하도록 할 수도 있습니다.
사실성이 올라가는것이지요.
사실 위에서 소개드린 방법은 엄밀히 따지면 Retrieval And Generation입니다.
처음 RAG가 제안된 논문에서는 방법이 좀 다르지요.
원래 RAG의 방법은 다음과 같습니다.
1. 문서를 찾는다. (확률 순으로 나열)
2. 찾은 문서 각각에 쿼리를 붙여 확률 분포를 구한다.
3. 모델의 Output 확률분포와 문서의 확률을 Weighted Sum(Marginalize)하여 최종 확률 분포를 구한다.
하유 Latex가 익숙하지 않아서 말로 설명하려니 어렵네요
이렇게 이루어집니다.
위와 같은 방법을 사용하면 정보가 불안정한 문서에 대해 대처할 수 있고, 문서를 한번에 넣지 않기 때문에 Input Text Length에 덜 걱정한다는 장점이 있지만, 한번의 Output을 내는 데에 찾은 문서의 수만큼 추론이 반복된다는 단점이 존재합니다.
RAG는 여태 언급된 단점들을 잘 해결할 수 있지만, 여전히 고민해야 할 문제들이 많습니다.
- Retrieval이 잘못된 문서를 가져올 수 있다.
- Retrieval된 문서에 너무 많은 내용이 포함되어 있으면 Noise로 작용한다.
- 너무 유명한 사실은 Retrieval이 필요하지 않다. (오히려 방해할 가능성이 있음)
Retrieval의 섬세함에 따라 성능이 좌우되는 만큼.. 좀 더 신경쓸 부분이 많아지겠습니다.
'
'
'
이로서 Knowledge Update에 대한 글을 마칩니다.
RAG에 대해 이해가 안되게 적은 것 같아 마음이 무겁네요.
좀 더 정리가 필요할 듯 합니다.
긴 글 읽어주시느라 고생많으셨습니다.
감사합니다 !
