반갑습니다.
저번 글에서는 retrieval 모델 중 Sparse retrieval들에 대해서 알아봤는데요.
이번에는 밀집 벡터들로 표현하는 Dense passage retrieval에 대해서 설명해볼까 합니다.
Dense Passage Retrieval?
문서를 밀집벡터로 표현하여 query와 passage간의 임베딩 벡터를 구한 뒤, 유사도를 측정하여 관련 문서를 찾는 시스템입니다.
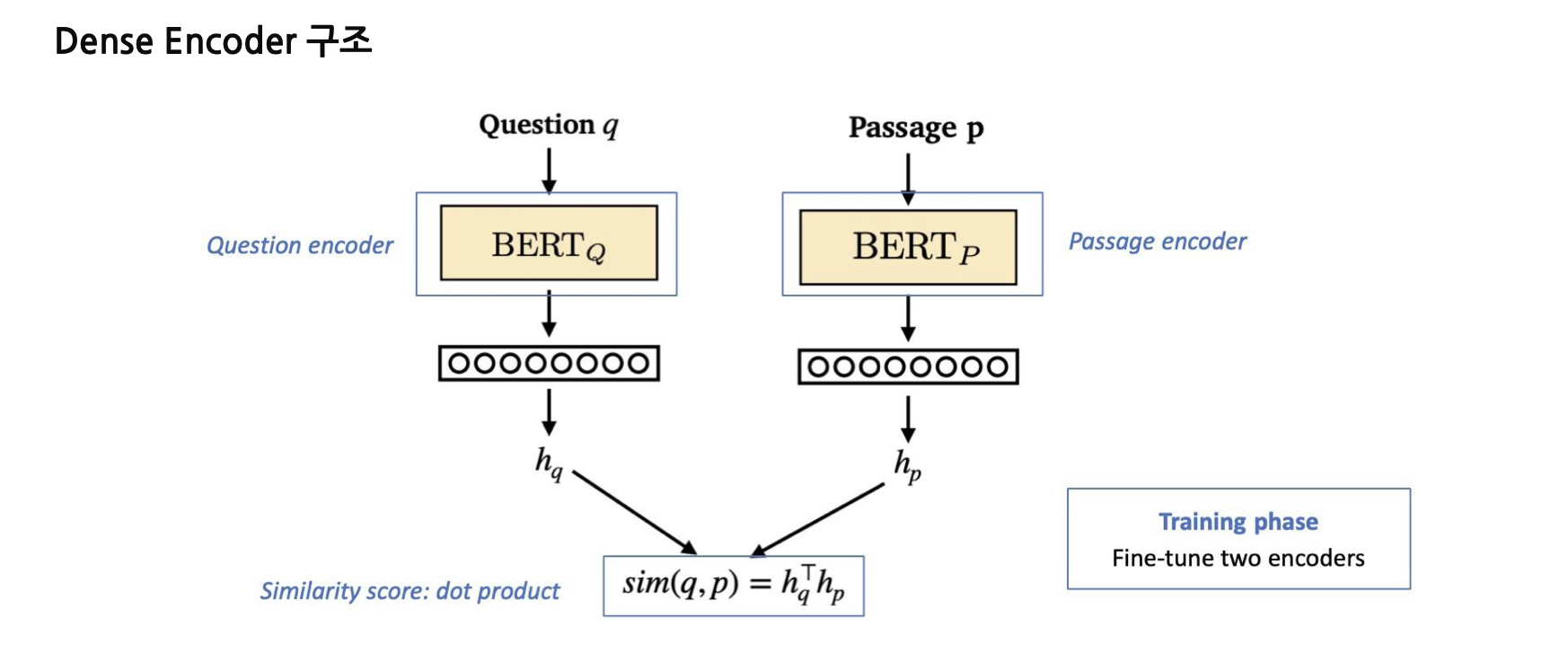
Dense 모델의 장점은 문장, 문서의 의미를 파악할 수 있다는 점입니다.
Sparse 모델은 '펩시' 와 '콜라' 와 '코카콜라' 를 전부 다른 단어로 파악하는 반면, Dense 모델은 비슷한 의미로 파악할 수 있습니다.
한 의미가 여러 단어로 표현되는 문서를 찾는 데에 Sparse Retrieval보다 좋겠습니다.
반면, 전문용어가 많이 등장하는 문서에서는 DPR보단 BM25, TF-IDF같은 Sparse retrieval을 사용하는 것이 좋겠습니다.
어려운 단어가 많은 의학 관련 문서들은 그쪽에 특화된 모델이 아니라면 Tokenizer와 Encoder가 제대로 된 의미를 갖는 임베딩 벡터를 내보내지 못할 가능성이 크겠죠.
의미와 희소성이 있는 표현을 모두 잘 헤아리는 retrieval을 만들기 위해서는 Dense retrieval과 Sparse retrieval을 섞어서 사용하는 것이 중요하겠습니다.
Dense Passage Retrieval은 어떻게 만들어요?
일반적으로, Passage Encoder과 Query Encoder 두가지 모델을 통해 Query Embedding, Passage Embedding을 구한 뒤, 유사도를 계산합니다.
(Dot product, Cosine Similarity 등)
이후, 쿼리와 정답 문서간의 로스를 계산하여 역전파합니다.
간단하게 코드를 통해 확인해보면 이해가 쉽겠습니다.
from transformers import AutoModel, AutoTokenizer
model_name = '뫄뫄'
q_encoder = AutoModel.from_pretrained(model_name)
p_encoder = AutoModel.from_pretrained(model_name)
p_tokenizer = AutoTokenizer.from_pretrained(model_name)
q_tokenizer = AutoTokenizer.from_pretrained(model_name)
# 위와 같이 모델을 지정하고,
for batch in datasets: # DataLoader가 되겠죠 ?
for query, passage in batch:
p_inputs = Tokenizer(passage)
q_inputs = Tokenizer(query)
p_embs = p_encoder(**p_inputs) # Passage의 임베딩
q_embs = q_encoder(**q_inputs) # Query의 임베딩
targets = torch.arange(0, batch_size).long()
sim_scores = torch.matmul(q_embs, p_embs.T)
sim_scores = F.log_softmax(sim_scores, dim=1)
loss = F.nll_loss(sim_scores, targets)
# Negative Log Likelyhood를 사용합니다.
이런 방식으로 구현할 수 있겠죠.
target이 왜 torch.arange일까요 ?
in-batch-negative-sampling이라는 방법론입니다.
배치사이즈가 8이라면, 8개의 question, passage 셋이 있겠죠.
그럼 8개의 sample들은 각각 1개의 정답과 7개의 오답을 가지게 되겠습니다.
그러면 따로 label을 정하지 않아도 알아서 라벨이 생기는 것이지요.
메모리 측면에서도 아주 좋은 접근법이 되겠습니다.
우리의 목적은 Passage와 Query의 유사도가 높아야 합니다.
좀 더 자세히 설명하자면, 모델의 예측과 실제 정답간의 분포를 동일하도록 해야합니다.
그렇기에 목적함수를 Negative Log Likelihood를 사용하는 것이지요.
이외에 다른 방법으로도 모델을 훈련할 수 있습니다.
두가지 모델을 선언하지 않고, 하나의 모델로
[CLS] Query [SEP] Passage [SEP] 과 같이 구성해서 0~1사이의 확률 분포로 나타내도록 하는 것도 좋은 방법입니다. (실제로 DPR의 논문에서는 이렇게 구현 돼 있다고 들었습니다.)
다만, 이 경우에는 Query와 Passage의 길이 합이 길다면 BERT 모델로는 길이 제한이 있을 수 있겠습니다.
LLM을 활용해서 임베딩 벡터를 얻을 수도 있습니다.
LLM의 Last Hidden state (CLS Token의 임베딩)를 활용해서 임베딩 벡터를 구하는 것이지요.
'
'
'
이로서 유명한 Dense Retrieval에 대해 많이 알아본 듯 싶습니다.
개념만 안다고 바로 사용할 수 있는게 아닙니다.
Sparse retrieval에서는 의미보다 단어의 매치가 중요한 만큼 조사를 뺀다던가, Stop words를 처리한다던가
Dense retrieval에 들어가는 train set들을 좀 더 분간하기 어려운 passage들로 구성한다던가 (Hard Negative Sample 추가)
여러 디테일을 고려해야 좋은 성능의 모델, 좋은 성능의 검색엔진을 개발할 수 있습니다.
감사합니다 !
