반갑습니다.
요즘 연구 트렌드는 Pretraining, Finetuning 등을 넘어서 Prompting으로 발전되고 있는 것 같습니다.
제 생각에는 새로운 패러다임의 개발에서 기존 모델들의 활용으로 넘어가는 듯 합니다.
이번 글에서는 LLM의 추론 퀄리티를 올려줄 수 있는 다양한 Prompting 방법에 대해서 정리해볼까 합니다.
시작 !!
Prompting
Prompting이란, LLM에게 대답을 받고 싶은 Query를 보내는 글을 의미합니다.
언어 모델을 제어하고 소통하는 수단으로 활용됩니다.
간단하게 말해서 언어모델에게 던지는 질의를 의미합니다.
이 질의에는 단순히 궁금한 부분을 물어볼 수도 있고, 어떤 양식을 맞추도록 요청할 수도 있죠.
활용 방법은 무궁무진하다고 생각합니다.
그렇다면 왜 Prompting이 중요하다고 평가되고 연구도 많이 이루어지는것일까요
이유는 LLM은 사실 생각하는 능력이 없기 때문입니다.
ChatGPT를 사용해보신 분들은 알겠지만 답변을 들었을 때, 정말 도움이 될 때도 있고 이상한 소리를 할 때도 있습니다.
또 어쩔때는 도움이 되는 말인 것 같았는데 헛소리일 때도 있죠.
이는 언어모델이 우리를 속이려고 한 게 아닙니다.
우리와 소통하는 언어모델은 대부분 Causal Language Model입니다.
Causal Language Model은 우리가 작성한 앞부분의 문맥을 보고 가장 나올 확률이 높은 단어들을 Output으로 내보냅니다.
그렇기에
집에 사과 열개가 있는데 어제 두개를 먹었고 오늘 아침에 세개를 먹었어.
점심에 어머니가 집에 있는 사과의 개수의 두배를 마트에서 사오셨어.
집에 사과는 몇개 있니?
같은 이해와 사고를 필요로 하는 문제에서 LLM이 많이 약한 모습을 보입니다.
(요즘 LLM들은 이런 문제도 잘 풀긴 합니다)
그럼 어떻게 해결해야 할까요
이런 문제들은 Prompting을 어떤 구성으로 주냐에 따라 정답률이 올라갈 수 있습니다.
그러한 방법들을 나열해보겠습니다.
CoT Prompting
1. Chain of Thought
생각하는 과정을 모사하는 설명을 Prompt에 추가로 기입합니다.
CoT는 유명한 Prompting 방법론중 하나입니다.
예시를 들어보겠습니다.
- Q : 사과 3묶음짜리와 낱개 2개를 샀어. 사과 1묶음에는 사과가 10개 들어 있어. 총 사과는 몇개니?
A : 사과가 10개 들어있는 묶음을 3개 샀으므로 사과는 30개이다.
이 때, 낱개로 2개를 구매했으므로 총 사과는 32개이다.
Q : 바나나 5묶음과 낱개 3개를 샀어. 바나나 1묶음에는 20개가 들어있어. 총 바나나는 몇개니?
A :
이해가 되실까요
위처럼 풀이 과정을 보여준 뒤 정답을 내도록 유도합니다.
언어모델은 풀이 과정을 작성하면서 정답일 확률이 높은 숫자를 더 잘 출력할 수 있도록 추론합니다.
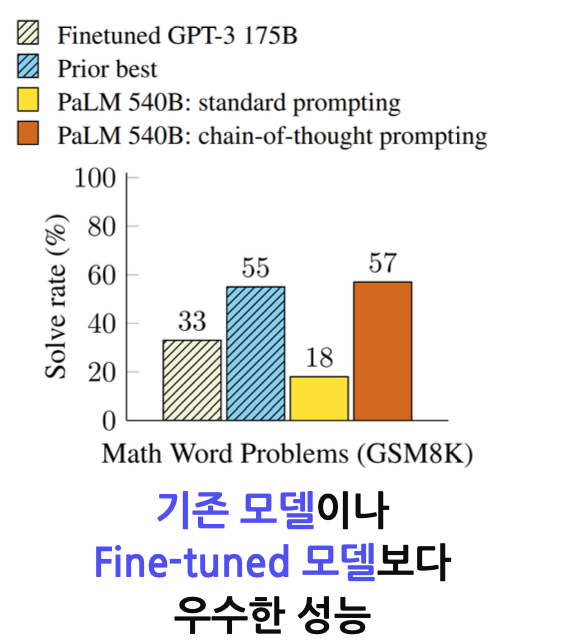
(Wei et al., “Chain- of -Thought Prompting Elicits Reasoning in Large Language Models”, NeurIPS , 2022)
사진을 보시면 위와 같은 CoT 프롬프팅을 적용한 것만으로도 추가적인 학습이 필요한 Fine-Tuning 모델보다 좋은 성능을 내는 것을 보여줍니다.
2. Zero-shot Chain of Thought
예시를 보여주지 않고 언어모델이 풀이 과정을 같이 출력하도록 지시합니다.
Zero-shot이라는 것은 예시를 하나도 보여주지 않는 것을 의미합니다.
그렇다면 예시를 보여주지 않고 어떻게 모델이 풀이과정을 출력하도록 할 수 있을까요
간단합니다.
"Let's think step by step.(차근차근 생각하세요.)"라는 문장을 추가하기만 하면 됩니다.
이런 단순한 방법으로도
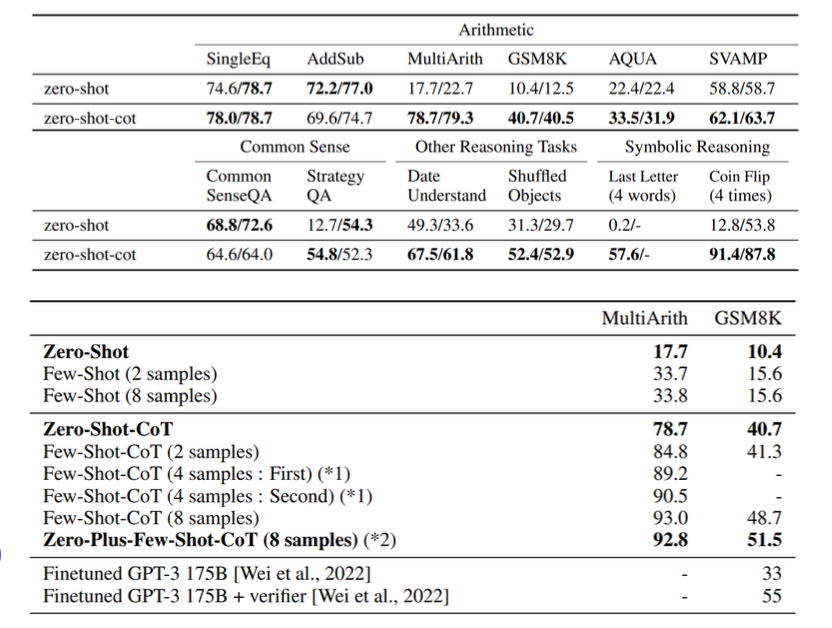
(Kojima et al., “Large Language Models are Zero- Shot Reasoner”, NeurIPS , 2022)
다음과 같은 좋은 성능을 발휘하는 것을 보여줍니다.
Zero-shot보다 훨씬 높은 성능을 보이는 것을 알 수 있습니다.
Zero-Plus-Few-Shot-CoT는 Zero-Shot-CoT로 생성한 예시들을 같이 제공하는 방법론을 의미합니다.
이러한 CoT 방법론들에는 주의할 점이 있습니다.
먼저, 답을 생성하고 풀이 과정을 적도록 하면 안됩니다.
풀이 과정을 생성하면서 답을 생각해내야 하기에 답이 먼저 생성되면 의미가 없겠죠.
단점 또한 존재합니다.
- Emergent Ability(모델의 파라미터가 100B이상)가 발현된 모델에서 효과적이며, 코드 데이터를 학습한 경우에만 성능이 향상된다는 보고가 있습니다.
- Reasoning (풀이과정)을 생성하는 와중, 풀이 과정이 이상하면 정답이 무너지는 경우가 존재합니다.
- 이유가 있음직해야 제대로 된 정답을 출력합니다.
ex) 지금 내가 하는 말의 앞단어만 따서 출력해 줘.(지내하말앞따출)
이러한 지시는 이유가 없기에 CoT를 활용하여도 큰 효과를 보지 못합니다.
이러한 단점을 보완하기 위해서 일종의 Ensemble과 같은 방법이 등장합니다.
3. Self-Consistency
CoT를 통해 생성된 문장을 바로 출력하지 않고 n개의 문장을 통합하여 하나의 출력을 내보냅니다.
한 프롬프트에 대해 10개의 샘플을 뽑습니다.
이때, Temperature을 조절하여 다양한 샘플을 뽑습니다.
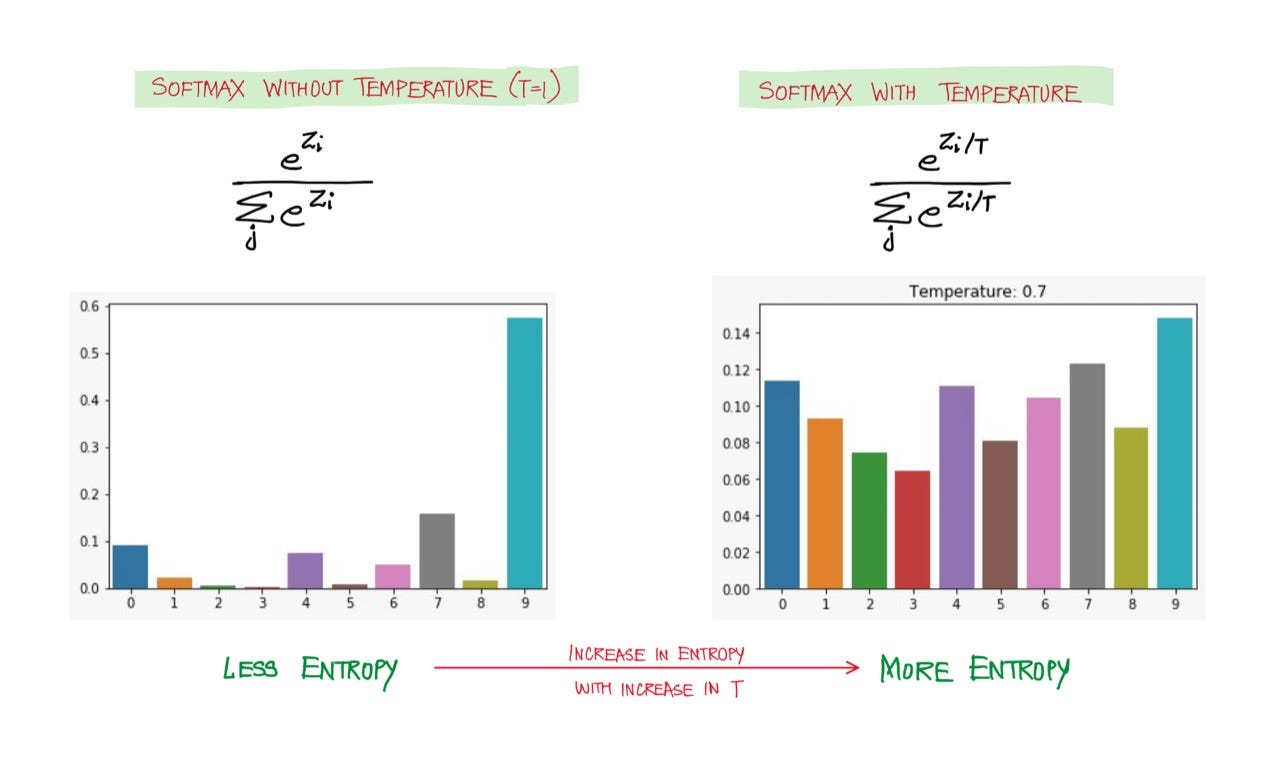
Temperature가 높을수록 Label 분포는 Smoothing됩니다.
Beam-Search시 더 다양한 단어를 내뱉을 수 있죠.
(참고 : https://velog.io/@yongari/그래서-AI로-문장-생성을-대체-어떻게-하는건데)
10개의 Reasoning과 Answer중 Answer 부분만 가져와 가장 다수로 등장한 Answer을 내보냅니다.
Hard Voting과 유사한 방법이라고 생각하시면 되겠습니다.
복잡한 문제를 분해하는 Prompting
1. Least-to-Most-Prompting
문제를 세부적으로 분해하여 풀이하는 과정을 예시로 보여주어 모델이 문제를 세부적인 작은 문제들로 바꾸어 풀이할 수 있도록 돕습니다.
예를 들어보겠습니다.
스키장 이용시간은 1시간이다. 레프트를 타고 올라가는 데에는 10분이 걸리고, 내려오는 데에는 5분이 소요된다.
스키를 총 몇번 탈 수 있는가?
라는 문제가 있다면
문제를 작은 요소들로 분해하여 풀이하는 예시를 보여줍니다.
- 레프트를 타고 올라가는 데에는 10분이 소요된다.
- 내려오는 데에는 5분이 소요된다.
- 그렇다면 스키를 한번 타는 데에는 15분이 소요된다.
- 이용시간은 1시간이기에 총 4번 탈 수 있다.
이렇게 예시를 같이 첨부한다면 모델은 다른 문제도 위 예시처럼 작은 문제들로 분해하여 풀이합니다.
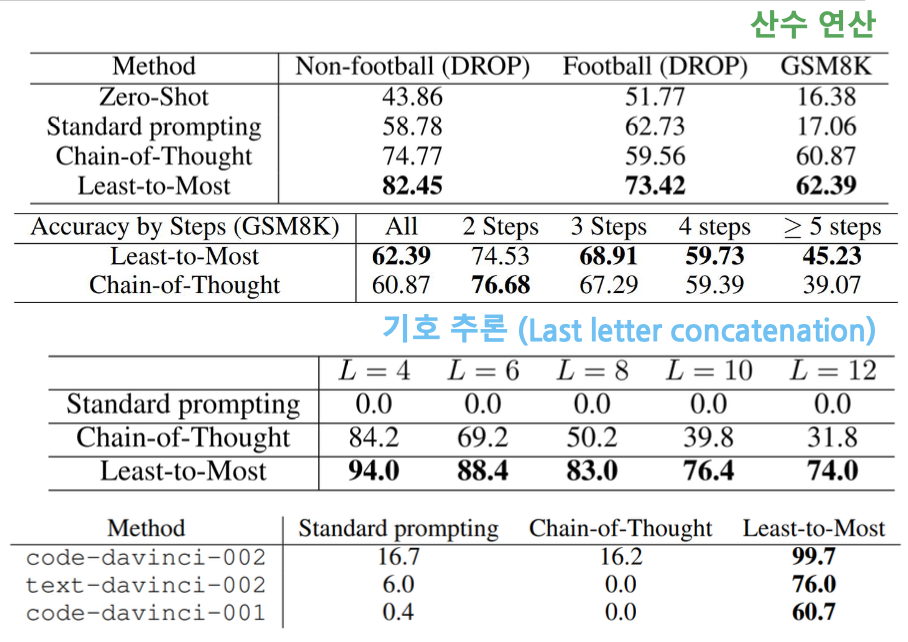
(Zhou et al., “Least- to-Most Prompting Enables Complex Reasoning in Large Language Models”, ICLR, 2023)
이러한 Prompting 기법은 산수, 기호추론 과제에서 CoT보다 높은 정확도를 기록합니다.
특히, 단계가 많은 문제일수록 CoT보다 우수한 Output을 내보낸다고 하는군요.
하지만 이러한 Prompting 기법은 이전 문제에서의 논리가 문제가 있으면 이후에도 영향을 끼치는 단점이 존재합니다.
이런 부분을 개선한 것이
2. Decomposed Prompting
큰 문제를 몇가지의 독립적인 작은 문제로 분해합니다.
여기서 중요하게 봐야 할 점은 독립적이라는 부분입니다.
Decomposed Prompting은 분해한 문제들끼리 영향이 없도록 하며, 분해한 문제들을 마지막에 통합하여 결과를 내도록 합니다.
Q: "A는 B보다 크고, B는 C보다 크다. A와 C 중 누가 더 큰가?"
Step 1: "A는 B보다 큰가?"
Output: "네, A는 B보다 큽니다."
Step 2: "B는 C보다 큰가?"
Output: "네, B는 C보다 큽니다."
Step 3: "A와 C 중 누가 더 큰가?"
Output: "A가 더 큽니다."
Answer: "A가 더 크다."
위처럼 독립적인 문제들을 나열하고, 마지막에 합쳐서 풀이하도록 지시합니다.
추가적으로 응용한다면, Prompting을 줄 때 사전에 정의해 놓은 도구들을 불러올 수 있도록 할 수도 있습니다.
ex) 당신은 아래와 같은 도구를 사용할 수 있습니다.
[검색] : 웹에서 검색합니다.
[단어 분해] : 단어를 분해합니다.
이러한 도구들을 정의해준다면
모델은
[검색] : 검색할 내용 (Search Function Calling)
<검색 결과>
결과에 따른 출력
이런식으로 Output을 낼 수도 있습니다.
이러한 Decomposed Prompting 기법은 일반화에 특히 강한 모습을 보입니다.
ReAct
ReAct + Self-Consistency
ReAct Prompting이란, 모델의 출력을 다시 입력으로 받아 만족스러운 결과가 나올 때 까지 반복하는 기법을 의미합니다.
ReAct Prompt는 총 세가지를 Output으로 내보내도록 지시합니다.
[Thought] : 무엇을 해야할지에 대한 생각
[Act] : 생각한 내용을 수행 (Act는 사용자가 정의)
[Observation] : 수행한 내용을 관찰
위 세가지를 수행하고, 결과를 다시 Input으로 넣어 답이 나왔다면 내보내고, 나오지 않았다면 위 과정을 반복합니다.
하지만 모델의 성능이 좋지 않다면, 계속 반복하는 경우가 많아 성능이 떨어질 수 있습니다.
그렇기에 몇번 이상의 반복에도 결과가 나오지 않는다면 Self-Consistency 방법을 통해 Output을 내보냅니다.
두 가지 방법을 합쳐서 결과를 내는 것이지요.
이 ReAct는 현재 핫한 Agent의 개념과 상당히 유사한 부분이 많습니다.
핵심은 Output을 다시 Input으로 넣는다는 부분입니다.
모델이 직접 무엇이 필요한지 진단하고 그 도구를 사용할 수 있는 능력을 기르는 것이 성능에 큰 영향을 미치겠습니다.
듣기로는 이러한 기술은 100B 이상의 LLM에서만 잘 작동한다는군요... ㅎㅎ
'
'
'
'
이렇게 Prompting 기법에 대해 자세히 알아봤습니다.
개인적 생각으로는 Prompting은 모델이 사고를 할 수 없으니 인간이 사고하는 과정을 최대한 비슷하게 따라하게 하자
가 핵심인듯 합니다.
제가 실력이 생긴다면 Agent에 대해서도 블로그에 자세히 다뤄보고 싶네요.
이상 마치겠습니다.
감사합니다 !

안녕하세요! 개발자 준비하시는 분이나 현업에 종사하고 계신 분들만 할 수 있는 시급 25달러~51달러 LLM 평가 부업 공유합니다~ 제 블로그에 자세하게 써놓았으니 관심있으시면 한 번 읽어봐주세요 :)