반갑습니다.
AI를 활용한 문장 생성에 대해 설명해볼까 합니다.
제목 죄송합니다.
공부가 잘 안되니 화가 나는군요.
블로그에 제 화를 잘 녹여보겠습니다.
자연어 생성에서 Decoding 과정
Decoding을 통해 자연어를 생성하는 과정을 의미합니다.
Encoding에서 문맥에 대한 정보를 잘 담은 input을 decoder에 입력으로 넣고, decoder는 출력으로 나온 단어를 다시 입력으로 넣어 문장을 생성하는 auto regressive한 형태로 구현됩니다.
가장 원시적으로 생각해 보면 언어모델 LM이 있을 때, 어떤 질문이 x로 들어왔다고 생각해보면 LM의 확률 분포 중 가장 확률이 높은 것을 내보내는게 이상적이겠습니다.
즉 Decoding의 수학적 목표를 표현해보자면
원하는 대답 = 이 되겠습니다.
즉 log-likelyhood를 최대로 높이는 값을 내보내자 라는 것이죠.
위의 수식대로 풀이하면 모든 단어 조합을 고려해서 출력해야 하니 LM의 vocab 수를 t만큼 제곱하는 연산을 해야합니다.
의 연산이 필요하겠군요
약 10000개의 단어사전이 있는 언어모델이 어떤 질문이 나왔을 때 10개의 단어를 뱉으려면 의 연산을 하시면 되겠습니다.
감사합니다.
농담입니다 죄송합니다.
의 값을 연산량을 좀 잘 케어하면서 가장 높은 수를 내고자 하면 어떻게 해야할까요?
1. Greedy searching
언어모델은 단어를 내뱉을 때 softmax의 결과값을 바탕으로 내보냅니다.
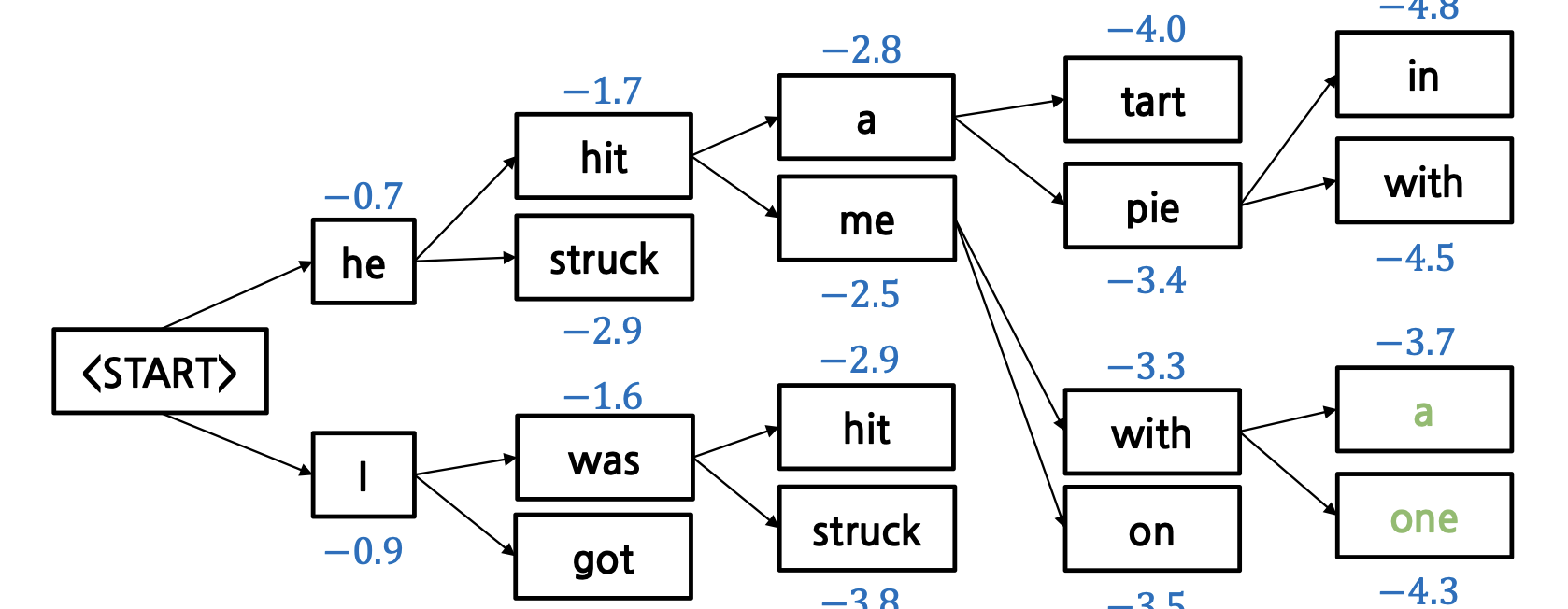
위와 같이 START 토큰이 입력으로 들어왔을 때를 시작으로 다음 단어가 뭐가 나올지를 예측하게 되겠죠.
그렇다면 최고의 확률을 가진 단어를 차례대로 출력하자 라는 작전입니다.
근데 제가 소개할 다양한 방법론들 중 1번으로 나왔다는거는 당연히 문제점이 있다는 것이겠죠
가령 확률이 0.50,0.49,0.01 세 가지 확률 분포가 나왔다고 하면
0.50의 확률을 가지는 단어를 선택하는 것이 타당하지 않은 판단이라고 생각됩니다.
또, 만약 0.50짜리 확률의 예측 단어가 틀린 단어였다면?
그 뒤에 나오는 단어도 그냥 쭉 틀리게 되는것이죠.
ex) 우리집 고양이는 매트 위에 있다 (정답문장)
첫 예측 : 우리집
두번째 예측 : 고양이는 (다음 예측 :[매트 : 0.49, 개 : 0.1, 츄르를 : 0.50])
세번째 예측 : 츄르를
네번째 예측 : 좋아해
와 같은 맥락으로 뭐 하나가 잘못 예측되면 전부 망해버리는 단점이 존재합니다.
2. Beam search
Greedy decoding을 개선하는 방법입니다.
Beam Search에서는 매 시점마다 가능한 후보 단어들 중에서 k개의 상위 확률을 가진 단어들을 선택하여 부분적으로 완성된 문장을 계속 확장합니다.
각 후보 문장의 점수는 로그 확률의 합으로 계산됩니다. 즉, 각 시점에서 생성된 단어의 로그 확률을 누적하여 문장의 점수를 구합니다.
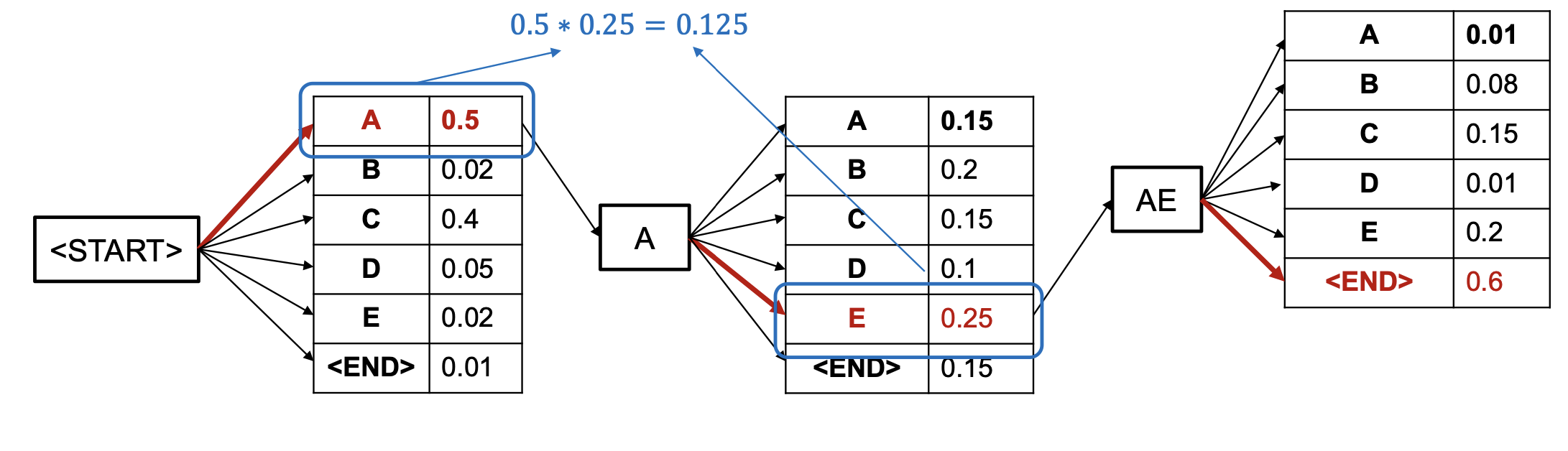
을 사용해서 각 단어 별 score을 구합니다.(여기서 은 위에서 말씀드린 원시적 확률과는 다른 Encoder을 활용해 문맥에 맞는 적절한 input을 넣었을 때의 확률입니다.)
이러한 스코어를 활용해 후보를 [START] 토큰부터 두 개씩 만들어 갑니다.(3개 이상으로 설정할 수도 있습니다)
그 다음, 각 후보별로 Score가 가장 높은 값을 찾아서 링크하는 방식인 것이죠.
Beam search를 한다면 연산량은 당연히 더 많아지겠지만 Greedy search보다 합리적인 문장 생성을 만들어 낼 수 있습니다.
하지만 Beam search에도 단점이 존재합니다.
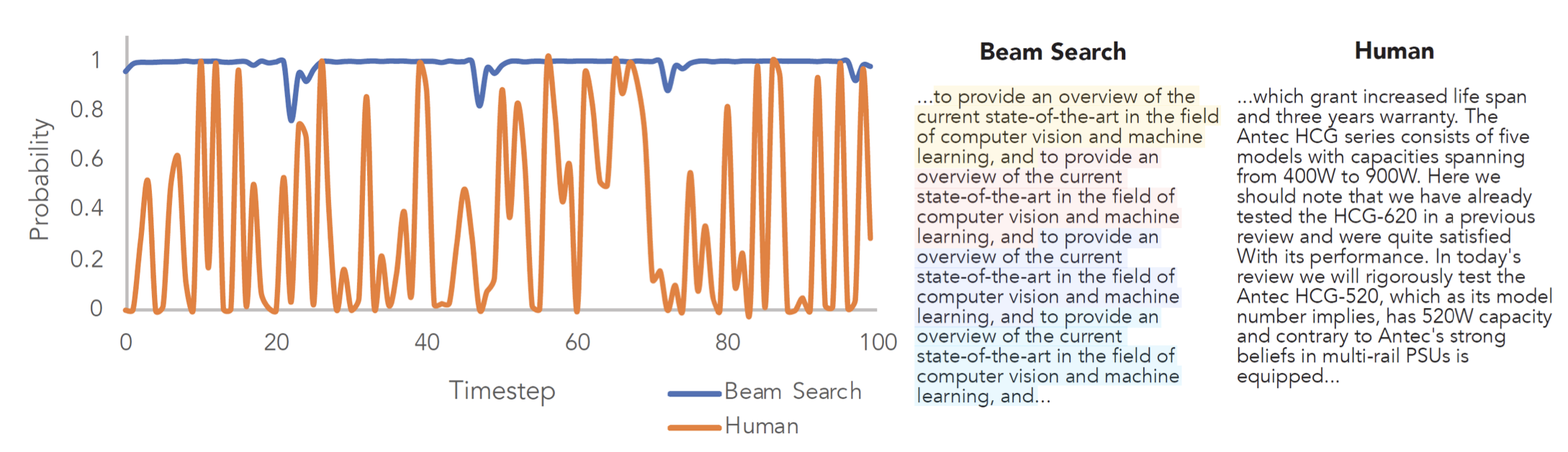
위 사진을 보시면 알 수 있듯이 Beam Search는 너무 정배만 찾아다니다 보니 거의 비슷한 대답을 반복적으로 생성하는 것을 볼 수 있습니다.
그럼어뜩해애앵
이러한 문제들은 모델에 랜덤성을 추가함으로써 해결할 수 있습니다.
Sampling의 종류
(사전지식) Temperature
Temperature이란, softmax에 추가하는 하이퍼 파라미터입니다. 분모, 분자에 존재하는 에 𝜏를 나눔으로서 확률 분포를 더욱 뾰족하거나 뭉툭하게 만들 수 있습니다.
계산 해보시면 알 수 있겠습니다. softmax는 값이 클 수록 확률 분포가 많이 튀는 성질을 가지고 있습니다(지수를 쓰기 때문).
이 때, 𝜏라는 하이퍼파라미터 값을 나누게 되면 𝜏>1에서 확률 분포가 더 뭉툭해지고, 𝜏<1에서 확률 분포가 더 뾰족해집니다.
언어 모델을 사용해보신 분들은 Temperature을 조절하는 bar을 본 적이 있으실 수도 있겠습니다.
아 ~ 요런거구나
하시면 될 것 같습니다.
1. Top-k sampling
나올 단어의 확률 탑-k까지를 고려해 그 중 랜덤한 단어를 output으로 내보내는 샘플링 기법입니다.
단어의 output 후보들이 있고, 그것들이 나올 확률들이 있다면
확률들을 크기별로 sort해서 위에서 k(여러분이 지정한 값)까지의 단어 중 랜덤한 값을 내보냅니다.
상당히 합리적이지만 아쉽게도 단점이 존재합니다.
예를 들어 k = 3일 때
확률 우리집 고양이가
1. 매트(0.97)
2. 똥(0.01)
3. 용가리(0.01)
'
'
'
일 때,
똥이 선택된다면 대참사죠.
이를 보완한 방법이
2. Top-p sampling
나올 단어의 확률의 합을 선정하여 후보군을 설정하고, 그 안에서 단어를 내보냅니다.
p = 0.8로 설정하였을 때,
단어 후보군들의 확률의 합이 0.8이 넘어갈 때 까지 후보군에 단어를 넣습니다.
Top-p sampling을 하게 된다면 특정 단어만 확률이 높을 때는 후보군을 적게, 단어들의 확률이 고루고루 퍼져 있을때는 후보군을 많게 설정할 수 있다는 장점이 존재합니다.
언어 모델들은 Temperature을 통해 다음 후보 단어들의 확률을 조정하고, 조정된 확률의 단어들을 Top-p sampling을 통해 출력하면서 언어 모델에 의외성을 조절합니다.
얼마나 정답에 정확할지, 또 얼마나 사람같을지를 여러 시행을 통해 조절해나가는 과정인 듯 합니다.
'
'
'
단어 생성이 어떻게 이루어지는지, 어떤 기법들이 있는지에 대해 알아봤습니다.
감사합니다.
