Half갑습니다.
이번 글에서는 대 LLM시대가 된 이유에 대해서 풀어서 글을 작성해볼까 합니다.
왜 LLM이 각광받고있을까요
당연히 LLM이 성능이 좋으니까겠죠
LLM의 성능이 왜 좋은지, 그리고 어느 부분에서 좋은지 등에 대해서 소개해보겠습니다.
LLM이 뭔가요?
LLM은 Large Language Model의 약자로, 일반적으로 아주 큰 파라미터를 갖는 모델을 대규모 데이터(테라바이트 단위의 토큰들)로 훈련된 사전 학습 모델을 의미합니다.
일반적으로 Decoder-only 모델을 기반 모델로 사용합니다.
설명이 모호합니다.
그냥 많은 데이터들로 학습시킨 모델들을 LLM이라 부르면 되나 ??
기준이 뭐지 ?? 라는 생각이 드는군요
LLM의 기준
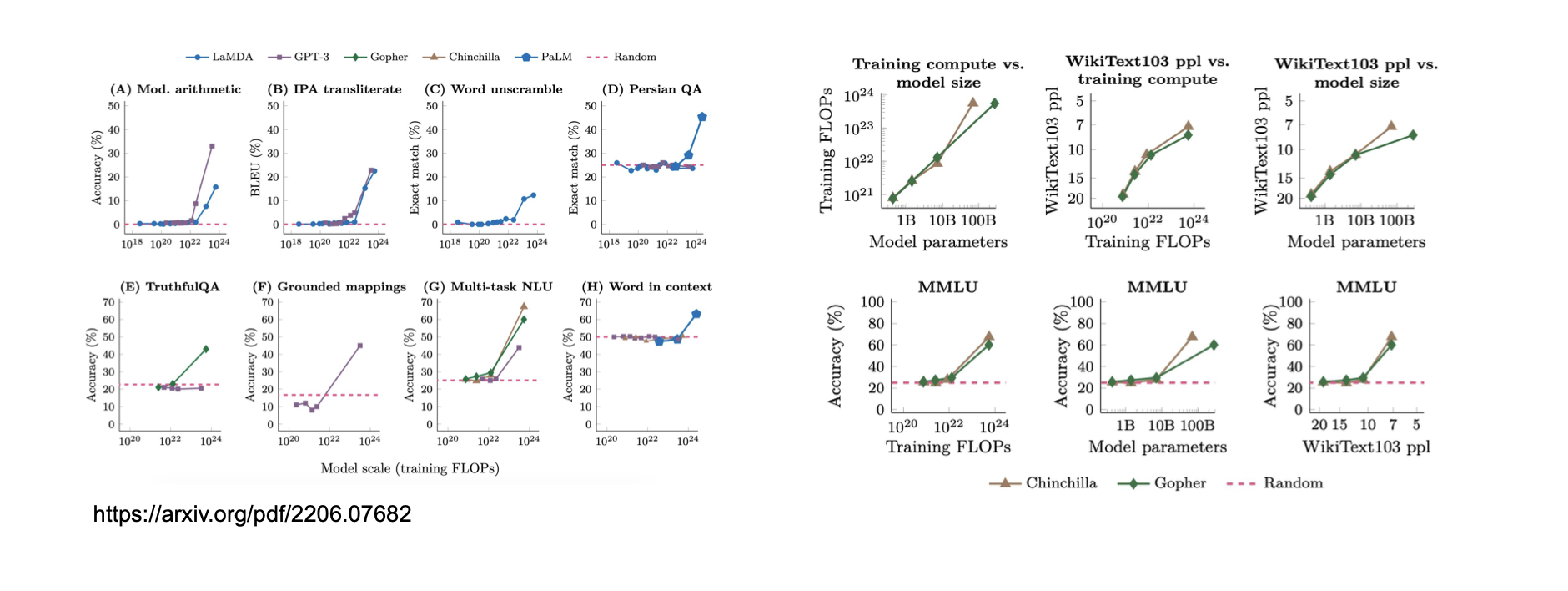
위 그래프는 Emergent Abilities of Large Language Models라는 논문(https://arxiv.org/abs/2206.07682)에서 발표된 그래프입니다.
Emergent Abilities라는 것은 모델의 크기가 어느 수준을 넘어가면 대부분의 Task에서 갑자기 성능이 확 오르더라
그걸 Emergent Abilities라 부르자
라고 해서 등장한 용어입니다.
보통 Emergent Abilities는 모델의 파라미터가 8~10B에서 발현된다 하는군요.
그래서 Huggigface에 LLM들을 보면 보통 8B부터 시작하나 싶습니다(3B 모델도 있긴 하지만)
LLM은 왜 Decoder-only 모델을 사용할까?
Transformer 기반 모델들은 Encoder-Decoder, Encoder-only, Decoder-only 모델들이 있습니다.
이중 왜 Decoder-only 모델을 LLM의 기반 모델로 사용할까요
Decoder-only model은 Autoregressive한 방식으로 단어를 생성해내는 생성에 특화된 모델입니다.
사전훈련할때도 뒤에 나올 말을 생성하는 방식으로 훈련이 진행되죠.
BERT같은 Encoder-only모델은 생성을 원활히 해낼 수 없습니다.
Generation도 본문 내에서 시작 단어 위치와 끝 단어 위치를 내보내는 수준밖에 되지 않죠.
따라서 다양한 Task를 수행하는 종합적인 모델을 만드려면 생성에 있어서 제약이 없는 Decoder-only model을 사용하는 것이 메리트가 많겠습니다.
LLM이여야만 하는 이유?
LLM을 사용하기 전까지는 보통 Pretrained Bert 모델을 finetuning하여 모델을 한 Task에 전문성을 갖도록 하는 방법이 주를 이루고 있었습니다.

사진을 보시면 2018년도부터 Encoder의 발전에 따라 NLU (감성분류, 주제분류 등) Task들이 많이 정복되기 시작했음을 알 수 있습니다.
하지만 Encoder, Encoder-Decoder 모델들은 몇 가지 단점들이 존재합니다.
- Encoder-Decoder 연결부 Cross attention 과정에서 병목 현상이 존재.
- Encoder-Decoder 에서 Encoder를 ICL(In-Context-Learning)에 최적화 시키는 데에 많은 비용 소모
- Encoder의 사전 학습 방식은 생성 Task에 초점이 맞춰져있지 않음. (MLM)
- Fine tuning을 통해 도메인 특화된 Task 한가지만 잘 수행할 수 있음.
좀 큰 단점이라고 한다면
대부분 하나의 Task에 특화된 모델로서 동작한다라는 부분이겠군요.
AI 모델이 하나 완성데는 데에 데이터수집 처리 모델학습 결과분석 개선 이렇게 다양한 작업들이 존재하는데 하나의 Task만 풀 수 있다면 효율적이지 못하겠습니다.
Decoder-only model은 위의 단점들을 대부분 해결할 수 있습니다.
ICL(In-Context-Learning)이라는 방법으로 몇 가지 예시를 보여주거나(Few shot) 사고 흐름(Chain of thought)을 정의해주면 아주 다양한 Task를 풀 수 있습니다.
또한 사전 학습 단계에서 text의 뒤를 예측해가는 훈련을 하기 때문에 전체 단어의 15%정도만 Masking하여 맞추는 BERT와 다르게 훈련 효율도 좋죠.
그래서 AI의 유행이 많은 일을 해낼 수 있는 아주 큰 모델을 만들자로 기운 듯 합니다.
하지만 이런 모델들을 학습시키는 데에는 몇십억 토큰의 데이터(심지어 잘 전처리된)와 고성능의 GPU가 필요합니다.
아무나 할 수 없죠.. ㅠ
그래도 최근에는 연산량을 줄이기 위한 최적화 기법들의 발전과 함께 대기업들이 Pretrained LLM을 많이 공개해주고 있어서 많은 사람들이 LLM을 쉽게 fine tuning할 수 있는 시대가 돼가고 있는 듯 합니다.
'
'
'
이번 글에서는 간단히 왜 LLM이 뜨게 되었는지, LLM으로 왜 Decoder-only 모델이 주로 쓰이는지 설명해 봤습니다.
다음 글에서는 Llama에서 쓰인 최신 기술들에 대해 설명해보고자 합니다.
저도 그냥 Transformer에서 Decoder만 떼서 만들었을 줄 알았는데
처음 공개된 Transformer와 다른 부분들이 많더군요.
그래서 다뤄보고자 합니다.
감사합니다 !
