반갑습니다.
NLP (자연어처리) 모델은 어떤 Task를 수행할 수 있을까
에 대해서 설명해볼까 합니다.
뭐 다양한 일을 할 수 있겠지만 Transformer기반의 모델이 NLP의 표준이 되었듯이 NLP의 Task또한 어느정도 정리가 되었다고 생각합니다.
그런 의미에서 NLP 분야의 Task들을 이번 글에 싹 정리해보겠습니다.
사전지식) NLP 모델의 input과 output
Seq to Seq 모델을 생각해봅시다.
SeqtoSeq 모델은 Input이 모델을 통과해 output으로 나옵니다.
여기서 주의깊게 보셔야 할 점은 input과 output의 도메인입니다.
input과 output이 어떤 내용을 담고 있냐에 따라 다양한 Task를 풀이할 수 있습니다.
N개의 input이 들어갔을 때 output은
1개
N개
M(N!=M)개
로 구분될 수 있습니다.
즉
N to 1
N to N
N to M
으로 나눌 수 있겠습니다.
이걸 왜 나누냐
몇 개가 나오느냐에 따라 다양한 Task를 정의할 수 있기 때문이죠.
아래를 더 살펴보시면 알 수 있을겁니다.
1. N to 1
N개의 input으로 들어간 정보들이 합쳐져 1개의 output을 뱉어냅니다.
output으로 나오는 1은
Linear layer를 통과시키고 softmax나 sigmoid를 통과시키면 확률 분포를 나타낼 수 있습니다.
확률 분포?
아하 ~
1. 이진 분류 (스팸인지 긍/부정인지 등등)
2. 두 문장간의 관계 (두 문장이 이어지는지, 논리적으로 참/거짓인지)
3. 문장의 주제 (사회, 운동, 문화 등등)
4. 두 문장이 유사한지 (유사도)
를 구별할 수 있겠습니다.
문장을 두개 입력한다는 것은 [SEP]토큰을 통해 구분할 수 있습니다.
BERT에 대해 아시는 분은 익숙하실 듯 싶습니다.
일반적으로는 Transformer의 Encoder를 통해 구현합니다.
하지만, GPT와 같이 Transformer의 Decoder를 통해 구현할 수도 있습니다.
예를 들어, 입력으로 "이게 스팸인지 한 단어로 알려 줘(0,1)."라고 넣고 결과가 한 단어로 나온다면, N to 1로 볼 수 있겠죠.
2. N to N
N개의 input으로 들어간 정보들이 N개의 output을 뱉습니다.
N개의 input이 그에 대응되는 N개의 output을 냅니다.
이 특징을 이용하면 각각의 단어들이 어떤 정보를 가지고 있는지에 대해 집중해서 볼 수 있습니다.
- 명사 의미 분석 (뭐 축구선수이다, 물건의 양에 관한 것이다, 개수에 관한 것이다 등)
- 형태소 분석 (명사, 조사, 부사, 동사 등등)
역시나 BERT를 예로 들면, 각각의 output이 나올 때, 전부 Linear layer를 통과시켜 N개의 확률 분포를 만들고, softmax를 통과시켜 본인이 원하는 Label을 지정합니다.
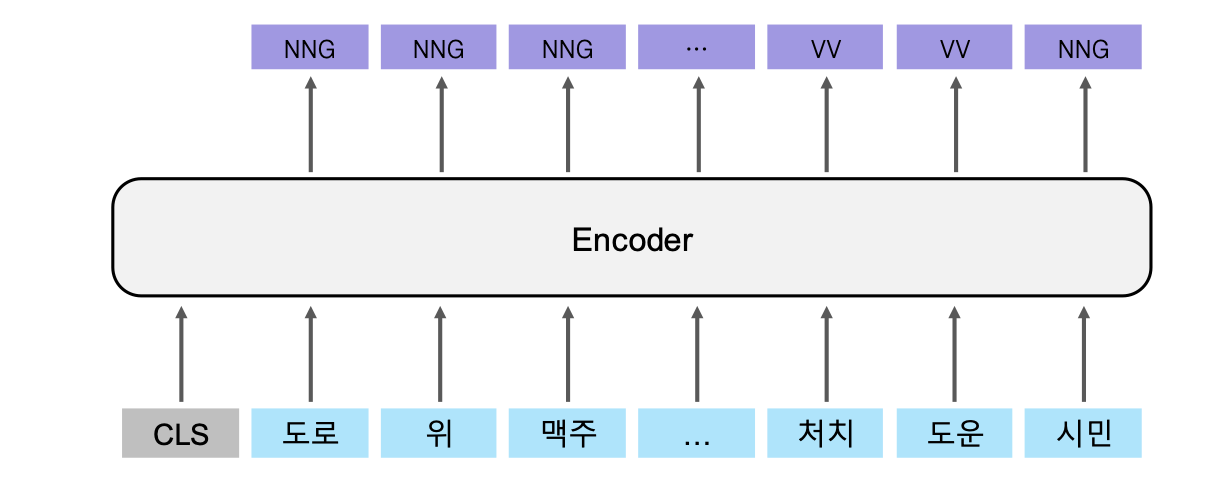
분류에 사용하는 [CLS] 토큰은 사용하지 않으니 사실 N to N-1이긴 합니다
,,,
편의상 NtoN이라 합시다 !! ㅎㅎ
3. N to M
N개의 input으로 들어간 정보들이 길이가 정해지지 않은 M개의 output을 뱉습니다.
길이가 정해지지 않는 M
을 듣자마자
Auto regressive하군 이라고 생각이 드신다면 훌륭합니다. 똑똑하시군여
Transformer의 Decoder 부분과 같이 어떤 정보가 주어졌을 때 가장 알맞는 단어를 하나씩 내뱉고 그것을 다시 input으로 넣으면서 [EOS]토큰이 나올때까지 반복하면 N to M의 형태를 가집니다.
N to M으로는 뭘 할 수 있냐
1. 번역(Translation) : 인코더에서 주어진 정보와 [SOS]토큰을 통해 디코더에서 입력 문장과 대응되는 의미를 가진 문장을 생성해냅니다.
2. 요약(Summarization) : 하나의 단락을 주고 이 중 중요한 정보를 품고 있는 단어들을 출력하여 문단을 요약합니다.
3. 대화(Dialog): 주어진 문장과 그에 맞는 대답을 가진 문장쌍을 학습시켜 사용자와 원활한 대화를 이끌 수 있는 생성모델을 학습시킵니다.
4. 이미지 설명(Image Captioning) : 이미지 정보를 인코더에 주고 주어진 이미지의 상황을 설명합니다.
다양한 Task들을 두고 보면 N to M이 가장 사람들이 원하는 혁신에 가까운 Task들인 것 같습니다.
그만큼 난이도도 더 어렵겠죠.
'
'
'
'
NLP에서의 Task들은 이정도면 대부분 다룬 듯 싶습니다.
그렇다면 이런 것들을 왜 분류할까요
그 이유는 모든 사람들이 공통적으로 사용할 수 있는 평가지표를 정하기 위함이라고 생각합니다.
실생활 적용에 필요한 Task들을 잘 정리하고 표준을 정해놓으면 다른분들이 본인의 모델을 평가할 때 본인의 모델이 다른 모델 대비 얼마나 잘 동작하는지를 알 수 있습니다.
또 그 지표가 높을수록 실제로 도움이 된다는 신뢰성도 높일 수 있겠죠.
그런 의미에서 다양한 Metric들도 소개해볼까 합니다.
근데 제가 지금 허리가 아파서
좀만 나중에 적겠습니다.
읽어주셔서 감사합니다 !!
