반갑습니다.
MRC 모델에서 자주 사용되는 Retrieval에 대해 설명해볼까 합니다.
Retrieval은 검색 엔진에도 사용됩니다.
배움을 거듭할수록 실생활에서 자주 썼던 기술들을 배우게 되니 기분이 좋네요 ㅎㅎ
이번 글에서는 두가지 종류의 retrieval 중, Sparse retrieval에 대해 알아보겠습니다.
Retrieval이란?
Sparse한 방법 또는 Dense한 방법으로 쿼리와 관련된 문서를 찾는 모델을 의미합니다.
MRC 모델에서는 쿼리를 입력하면 쿼리를 통해 떠올린 문서를 바탕으로 쿼리에 대한 답을 출력합니다.
Sparse한 방법과 Dense한 방법 이 뭘까요
먼저 sparse data에 대해 생각해 봅시다.
sparse (희소) 하게 표현된 데이터는 One hot vector와 같이 [0,0,0,0,,,,1]처럼 표현됩니다.
데이터에 0이 많고 적은 부분을 1로 표현하죠.
반면 Dense (밀집) 하게 표현된 데이터는 [0.123,0.1512,0.6345,0.3435,,,,] 등 모든 요소가 0이 아닌 경우가 많고, Sparse 벡터에 비해 길이가 짧습니다.
아하
Sparse retireval은 뭔가 Sparse한 데이터를 활용해서 문서를 떠올리고
Dense retrieval은 뭔가 Dense한 데이터를 활용해서 문서를 떠올리는구나!!
아래에서 살펴보겠습니다.
Sparse Retrieval
Sparse Retrival들의 기본 개념은 다음과 같습니다.
1. 일단 쿼리에서 나오는 단어들을 본다.
2. 그 단어가 많이 등장하는 문서를 찾는다.
예를 들어보면
Query : 흑백요리사의 등장인물들을 알려줘.
라는 질문이 들어왔다면
'흑백요리사', '등장인물', '알려줘' 뭐 이런 단어들을 바탕으로 문서를 찾습니다.
문서를 한 열개 찾으면
흑백요리사, 요리사, 등장인물, 알려주다 같은 단어가 많이 포함된 문서들이 나오겠죠. 이를 이용한 방법입니다.
이 때, 문서들에 존재하는 단어들을 미리 Bag of Words 형태로 저장해놓으면 검색 속도를 빠르게 가져갈 수도 있겠습니다.
하지만 단어들만을 기준으로 찾으면 몇가지 단점이 존재합니다.
가령 쿼리에 '나는 흑백요리사의 등장인물을 알고 싶어.'라고 들어왔을 때
문서에서 '나는' 이라는 단어가 '흑백요리사'라는 단어보다 많이 등장한다면, 빈도를 바탕으로 문서를 출력할 때 원하지 않는 문서가 검색될 가능성이 높습니다.
감이 오시죠 ㅎㅎ
Sparse retrieval을 제작할 때 고려해야 할 점은 '나는', '그들은'과 같은 단어의 점수는 낮게, '흑백요리사' 같은 단어의 점수는 높게 설정해야합니다.
단어의 정보량을 판단하는 기준을 잘 설정하는것이 Sparse retrieval의 핵심이 되겠습니다.
1. TF-IDF (Term Frequency - Inverse Documents Frequency) retrieval
TF-IDF retrival은 문서에서 나오는 단어를 바탕으로 점수를 매겨 가장 높은 score을 가지는 문서를 output으로 내보내는 알고리즘 기법입니다.
이 때, 자주 등장하는 단어의 점수는 낮게, 드물게 등장하는 단어의 점수는 높게 받아들여 정보를 더 정확히 찾을 수 있도록 합니다.
이를 통해 사용자는 쿼리에 등장하는 단어를 바탕으로 떠올린 문서들을 얻을 수 있습니다.
소개에서 설명 다 해놨네요.
일단 이름을 보자면, TF (단어의 빈도), IDF (단어가 제공하는 정보의 양)
으로 알아두시면 되겠습니다.
TF는 단순히 문서의 단어들이 단어장에 얼마나 등장했는지에 대한 빈도입니다.
IDF가 중요한데요,
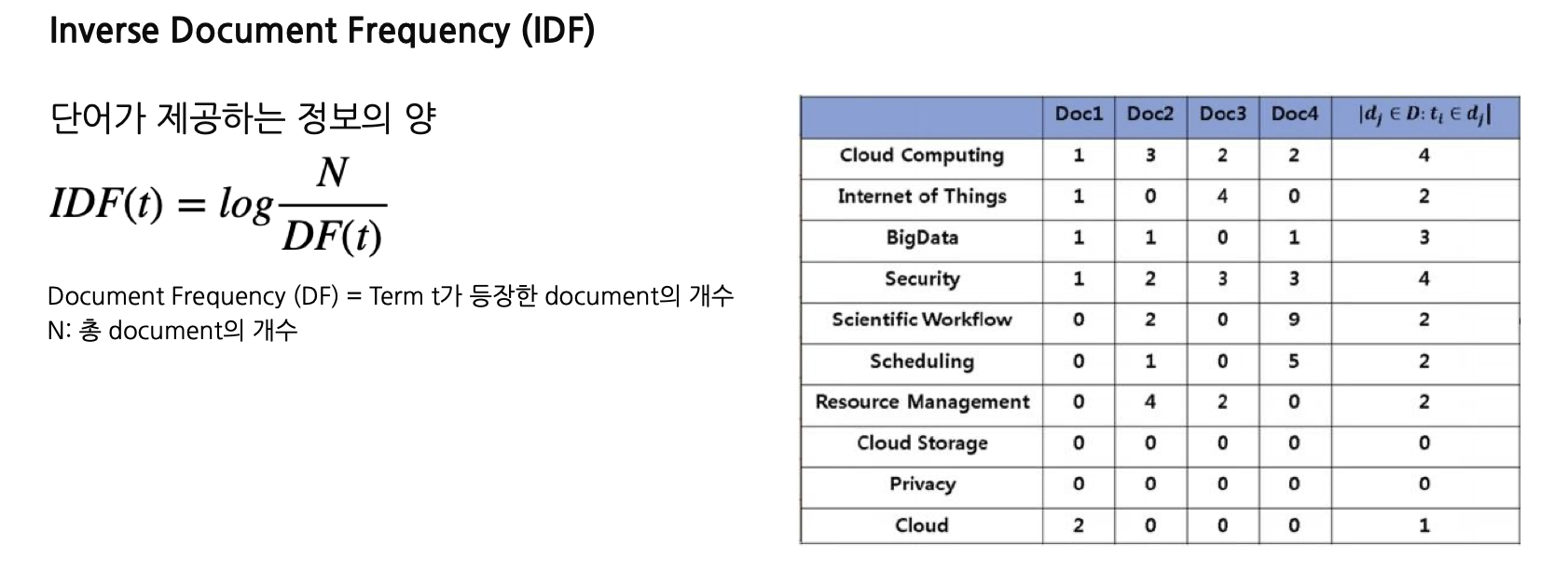
수식을 보시면 아실 수 있듯이 전체 Document의 개수에서 특정 term 등장한 Document 개수를 나눕니다.
자주 등장하는 단어들은 나누겠다는 의미겠지요.
TF-IDF retreival score은 TF와 IDF를 곱함으로서 만들어집니다.
코드가 간단해서 같이 살펴보겠습니다.
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
Documents = load_from_disk(documents_path)
tokenizer_func = lambda x: x.split(' ')
vectorizer = TfidfVectorizer(tokenizer=tokenizer_func, ngram_range=(1,2))
vectorizer.fit(corpus)
sp_matrix = vectorizer.transform(corpus)
df = pd.DataFrame(sp_matrix[0].T.todense(), index=vectorizer.get_feature_names_out(), columns=["TF-IDF"])
df = df.sort_values('TF-IDF', ascending=False)
print(df.head(10))이처럼 tokenizer func을 지정해 주고 ngram_range를 지정해줍니다.
이후 fit / transform을 통해 문서를 TFIDF 점수를 가진 행렬로 만들어 줍니다.
shape는 (문서개수, feature개수)가 되겠죠.

앞으로 쿼리가 들어온다면
query = vectorizer.transform([question])
result = query * sp_matrix.T # (1, feature 개수) * (feature개수, 문서 개수)
# > (1, 문서 개수)
result는 한 쿼리에 대해 모든 문서간의 점수를 계산한 행렬을 가지게 됩니다.
sort해서 점수를 높은 순으로 세운다면 원하시는 결과를 가질 수 있겠습니다.
하지만 이렇게 훌륭한 알고리즘에도 단점이 존재합니다.
문서 길이에 대한 문제죠.
단어의 정보에 가치를 고려할 수 있게 되었지만, 문서의 길이가 항상 같지는 않습니다.
Q. 과학 문제집 추천해줘.
라는 쿼리가 들어왔을 때,
Doc 1 : 고딩들 문제집 추천해준다. 뭐가좋냐면 ~~
Doc 2 : 과학 기술의 발전은 어디까지일까? 우선 과학에 대한 정의부터 나눠보자. ~~ (대충 아주 긴 과학얘기)
Doc 2가 선택되겠죠.
무슨소리냐면
TF-IDF 기반의 Retrieval은 문서의 길이가 길 수록 뽑히는 데에 유리하다라는 단점이 존재합니다.
이를 해결하고자
2. BM 25 retrieval
TF-IDF 알고리즘의 개선판입니다.
TF, IDF를 계산하는 과정까지는 같으나 문서의 길이를 고려하여 문서 길이 정규화 과정까지 수행합니다.
일반적으로 TF-IDF보다 결과가 좋습니다.

저도 공식을 잘 몰라서 GPT에게 간단히 물어봤습니다 하하
상수가 많이 섞여 조금 어려워 보이겠지만 결국 TF IDF 식의 확장판입니다.
IDF와 TF를 곱하는 데, 여기서 k에)를 곱하여 문서 길이를 같이 고려할 수 있도록 합니다.
문서 길이가 와장창 커지면 IDF 뒤에 곱해지는 수가 작아지도록 한 것이지요.
'
'
'
'
'
Sparse retrieval에 대해서는 이정도면 된 듯 싶습니다.
물론 제가 소개해드린 방법 외에도 다양한 Sparse retrieval가 아마 존재하겠죠.
저도 좋은 게 있다면 나중에 이 글에 추가하도록 하겠습니다.
다음에는 retireval 중 두번째, Dense retrieval에 대해 글을 작성해보겠습니다.
감사합니다 !
