반갑습니다.
저번 글에서는 MRC 모델에 대해 간단히 얘기해봤습니다.
이번 글 부터는 그 요소들에 대해 하나하나씩 파고들어보겠습니다.
첫빠따는 Extraction Based MRC 모델입니다.
Extraction Based MRC
추출 기반의 Machine Reading Comprehension을 의미합니다.
질문에 대한 답변을 지문 내의 단어들 사이에서 찾습니다.
Extraction Based MRC 모델은 지문 내에서 정답을 찾는 모델입니다.
SQuAD 1.0, 2.0과 같이 지문과 질문, 정답으로 이루어져 있는 데이터셋을 활용해서 모델을 제작합니다.
평가 지표는 기본적으로 EM(Exact Match)와 F1 Score을 활용합니다.
EM은 정답과 예측단어가 완전히 일치할 때 1점, 하나라도 틀리면 0점입니다.
각박하군요 ㅠ
그에 비해 F1 Score은 단어 단위로 맞췄는지 틀렸는지의 비율을 계산합니다.
부분점수가 있죠.

이런 식으로 계산됩니다.

F1 Score은 뭐 많이들 아실 것 같습니다.
Precision과 Recall의 조화평균입니다.
Extraction Based MRC 모델을 어떻게 만들까요?
1. Encoder Only Model
정답 단어의 시작 부분과 끝 부분의 위치에 대한 Logit을 토큰마다 Classification의 개념으로 계산합니다.
Extraction Based MRC는 지문에서 답을 직접 발췌해서 출력합니다.
모델은 Encoder only 모델을 통해 각 sentences에서 start logit과 end logit을 뽑아냅니다.
대표적인 모델로는 BERT가 있겠습니다.
입출력을 살펴보면
[Qustion] '내가 어제 먹은 음식은?' [Context] '나는 어제 두부를 먹었다.'
라는 입력 데이터에서 내가 어제 먹은 음식에 대한 답을 찾고자 모델에 넣으면
Start : 6
End : 8
이 나오는거죠.
그러면 Context[Start:End]를 통해 답을 찾아낼 수 있겠습니다.
Bert 모델의 모든 토큰에 logit을 계산하고, 실제 정답 라벨과의 차이에 대한 로스를 Cross_Entropy Loss를 통해 계산합니다.
start_loss = CrossEntropyLoss(start_logits, start_positons)
end_loss = CrossEntropyLoss(end_logits, end_positions)
total_loss = (start_loss + end_loss) / 2처럼요 ㅎㅎ
이처럼 시작, 끝 위치를 예측하는 모델은 후처리 함수가 성능에 큰 영향을 끼칩니다.
후처리 함수의 기능들을 설명해보면
- start/end logit들을 큰순서로 N개를 뽑는다.
- 불가능한 조합을 제거한다. (end가 start보다 앞에 있거나 질문 쪽에 있거나 등)
- 가능한 조합들로 score을 계산하고, 큰순으로 정렬한다.
- Score가 가장 큰 조합부터 k개 내보낸다.
이 부분에 대한 구현이 정말 까다로웠습니다.(제기준)
저도 아직 잘 모르니까 일주일동안 해서 5점이 나왔겠죠.
에흉
다른 대안으로는 Decoder 가 있는 모델을 활용해 Autoregressive 하게 생성해낼 수도 있습니다.
Generative based model
Decoder을 활용하여 출력을 Autoregressive한 형태로 뽑아 질문에 대한 대답을 Generation의 형태로 출력합니다.
Encoder 기반의 모델은 입력 데이터가 다음과 같습니다.
[[CLS] Question [SEP] Context [PAD][PAD]...]
이처럼 Special Token들을 이용해서 시작과 끝점을 예측하죠.
이와 반대로 Generative based model은 데이터를 자연어 기반의 format으로 전달합니다.
뭔소리냐면
[Question text : Context ] 이런식으로 전달한다는 겁니다.
대표적인 모델로는 GPT, BART 등이 있겠습니다.
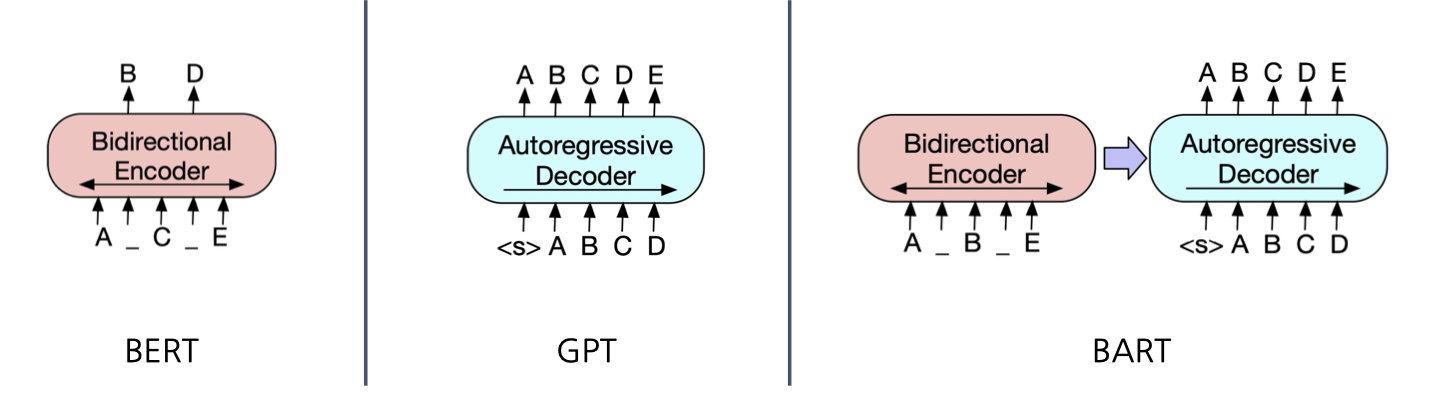
위 사진이 BERT, GPT, BART에 대한 차이를 잘 볼수 있군요.
Generative 모델에서는 GPT와 BART를 활용할 수 있겠습니다. (디코더가 달려있기 때문)
아참 참고로 BART는 텍스트에 노이즈를 주고 다시 복구하는 방향으로 pre-trained된 모델입니다.
Generative 모델은 Encoder 모델과 달리 입력 모델을 훈련하는 방식이 비교적 쉽습니다.
시작과 끝 위치를 이리저리 나누고 가르지 않아도 output이 자연어 형태로 나오기 때문이죠.
대신 다양한 후보군들을 만들고 가장 정배를 찾는 과정은 필요합니다.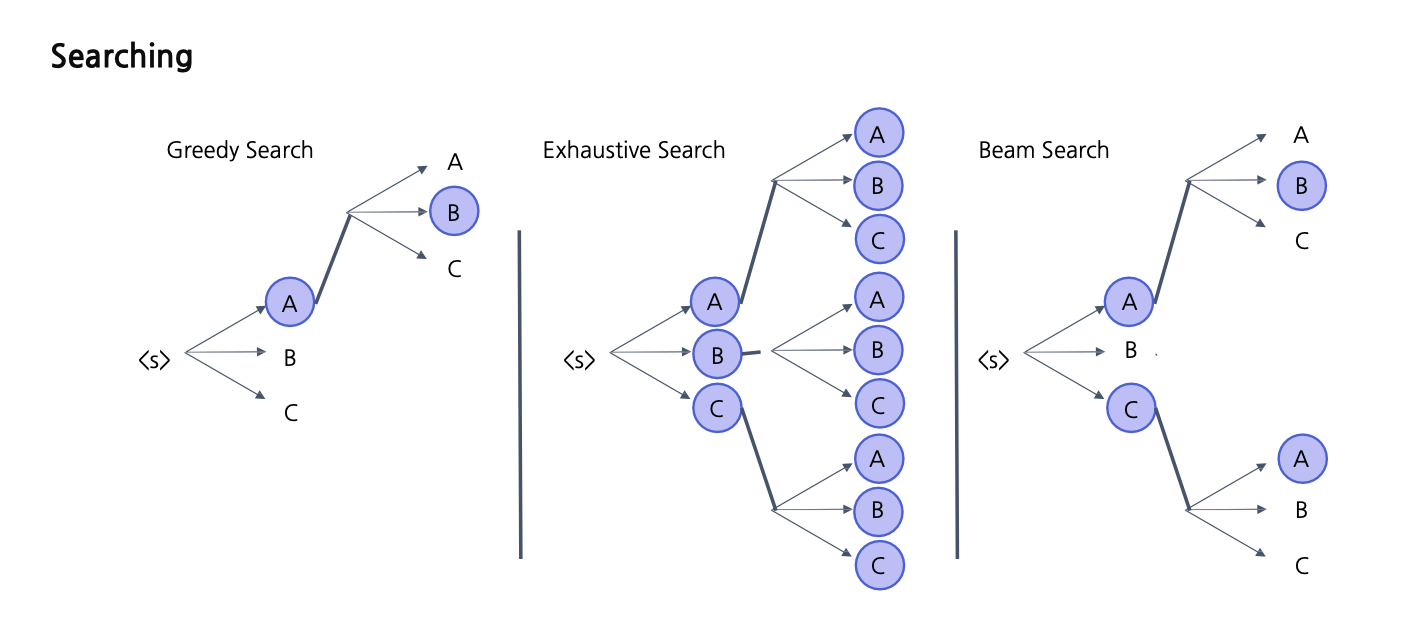
엥 이사진은 뭘까 ??
https://velog.io/@yongari/그래서-AI로-문장-생성을-대체-어떻게-하는건데
누가 아주 잘 설명해놨네요. 참고해서 보시면 되겠습니다.
'
'
'
이로서 Extraction Based MRC Task를 풀이하기 위한 모델들을 알아봤습니다.
말로 설명하면 정말 간단하고 쉬운데 구현으로 넘어가면 정말 괴롭습니다.
코딩을 잘하시는 분들은 도전해보시면 좋을 것 같습니다.
현업자 분들은 다 활용해서 쓰시는 기술들일테니까요.
글 읽어주셔서 감사합니다 !
