반갑습니다
이번 글에서는 NLP 분야의 평가지표 중 하나인 Rouge, BLEU Score에 대해 설명해보겠습니다.
Classification같은 하나의 정답이 확실히 있는 Task들은 평가 방법이 간단하고 쉽습니다.
맞췄냐 못맞췄냐로 확실히 나눌 수 있으니까요.
하지만 output이 길게 나오는 구성의 모델들은 평가 방법이 쉽지 않습니다.
N to M 문제에서의 다양한 평가지표들이 있지만
오늘은 텍스트 요약에 주로 사용하는 Rouge Score과 텍스트 번역에 주로 사용되는 BLEU Score에 대해 소개해보겠습니다.
Rouge Score?
Rouge Score(Recall-Oriented Understudy for Gisting Evaluation)란, 자연어 처리 모델 중 주로 텍스트 요약의 성능을 확인할 때 자주 쓰이는 지표입니다.
Rouge-N, Rouge-L 등이 있습니다.
1. Rouge-N
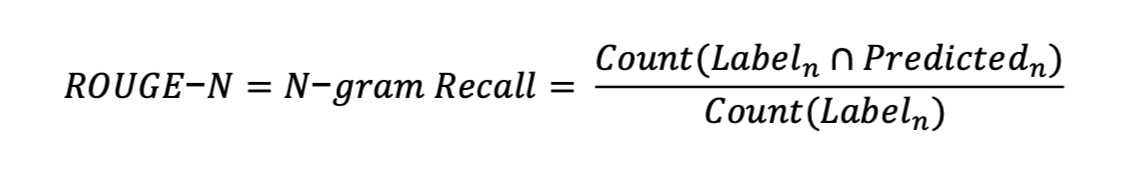
Rouge는 이름에서 알 수 있듯이 Recall 기반의 평가지표입니다.
정답 중 얼마나 맞췄나를 기준으로 삼고 점수를 매깁니다.
간단히 예를 들어보겠습니다.
predict : 나는 밥을 먹었다.
label : 나는 아침을 먹었다.
rouge1은 [['나는', '밥을', '먹었다', '.'], ['나는', '아침을', '먹었다', '.']]
rouge2는 [['나는 밥을','밥을 먹었다', '먹었다 .'], ['나는 아침을', '아침을 먹었다', '먹었다 .']]
처럼 n gram기반으로 전체 중 맞춘 수를 본다고 보시면 되겠습니다.
2. Rouge-L
label과 predict 사이에 가장 긴 문자열을 매칭시켜 점수를 매깁니다.
Rouge L은 LCS(Longest Common Subsequences) 기반의 평가 지표입니다.
label : ["The", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog"]
predict : ["A", "fast", "brown", "fox", "leaps", "over", "a", "lazy", "dog"]
라면 LCS는 ["brown", "fox", "over", "lazy", "dog"]가 되겠죠.
그렇다면
Precision = 공통 부분 문자열 길이 / 생성된 요약 길이 = 5 / 9
Recall = 공통 부분 문자열 길이 / 참조 요약 길이 = 5 / 9
이 둘의 F1 Score에 하이퍼파라미터 베타를 잘 섞은 식이 Rouge L 점수가 됩니다.
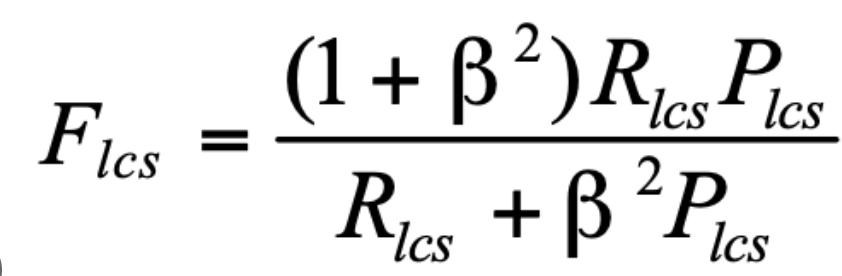
일반적으로 베타는 1로 설정된다고 하는군요. (GPT 피셜)
BLEU Score?
BLEU Score(Bilingual Evaluation Understudy)란, 자연어 처리 모델 중 주로 텍스트 번역의 성능을 확인할 때 자주 쓰이는 지표입니다
Rouge Score가 Recall 기반의 평가지표인 반면, BLEU Score는 Precision 기반의 지표입니다.

Rough score과 다른점은 분모가 라는 점입니다.
즉 예측한 단어 중 얼마나 맞췄냐를 기준으로 점수를 매긴다고 할 수 있겠습니
다.
또, BP라는 상수를 곱한다는 것과 BLEU-2,3,4로 갈수록 분수가 연쇄적으로 곱해진다는 점을 차이점이라고 할 수 있습니다.
BLEU score는 1에 가까울수록 높은 점수라고 할 수 있겠군요.
'
'
'
'
이로서 Rough score과 BLEU score에 대해 알아봤습니다.
평가 지표는 잘 알아둬야 다른 모델을 볼 때 성능이 얼마나 나오는지를 알 수 있겠죠.
다양한 평가지표를 꼭 알아두는 것이 좋겠습니다.
감사합니다 !
