반갑습니다
이번엔 멀티모달 RAG에 이어서 Self RAG에 대해 다뤄볼까 합니다.
RAG에 대해 왜 이렇게 많은 방법들과 아이디어가 계속해서 나올까요?
다양하게 활용되는 기술이기 때문이며,
또 기존의 방법에 단점이 존재했기 때문이기도 합니다.
살펴봅시다 !
RAG의 단점 ?
RAG는 다양한 문제점을 해결한 아주 좋은 기술입니다.
특히, Foundation 모델의 성능이 올라갈 수록 더 많은 문서를 참고할 수도 있고, LLM 모델의 Knowledge update를 거치지 않아도 최신 정보를 다룰 수 있죠.
이런 RAG에도 몇몇 단점이 존재합니다.
-
모든 질의에 꼭 RAG가 필요하지 않다
"안녕?" 이라는 간단한 인사같은 질문, "30*30은 뭐야 ?" 같은 불변의 진리에 대해 묻는 질의에는 꼭 참고 문서가 필요하지 않습니다. 이는 RAG 없이도 대답할 수 있는 질문이겠죠. -
참고 문서의 길이가 아주 길어질 경우, 질의의 핵심을 놓칠 수 있다.
물론 Text의 길이를 잘 잘라서 RAG를 구성하겠지만,, 어찌 됐든 기본적으로 입력되는 토큰 수가 많아지면 질문의 핵심을 놓칠 수 있으며, 나아가 답변 생성 속도에도 악영향을 끼칠 수 있습니다. -
답변 품질이 Retriever의 성능에 크게 좌우된다.
보통 RAG를 구성할 때에는 LLM의 프롬프트에 "반드시 참고 문서에 기반하여 대답하세요." 와 같은 문장을 입력하게 되는데, Retrieval의 성능이 안좋다면, 잘못된 정보를 전달해 줄 가능성이 있습니다.
주로 사용되는 챗봇은 결국 사용자의 경험이 제일 중요한 요소이기에, 항상 대답을 잘 하더라도 불안정한 모습이 보인다면 이는 수익에도 큰 악영향을 미칠 수 있습니다.
"안녕? 너에 대해 소개해줘."라고 질의를 던졌는데, 답변에 대한 참고 문서가 뜨면 뭔가 이상하겠죠.
이러한 다양한 문제들 중, 3번을 해결하기 위해 기존의 RAG 시스템을 좀 더 매끄럽게 사용할 수 있도록 고안한 방법이 Self-RAG입니다.
Self-RAG
LLM이 답변을 수행하기 전에, LLM 스스로 Retrieve된 문서들의 품질과 이를 바탕으로 출력한 답변의 품질을 검토하고 수정을 반복합니다.
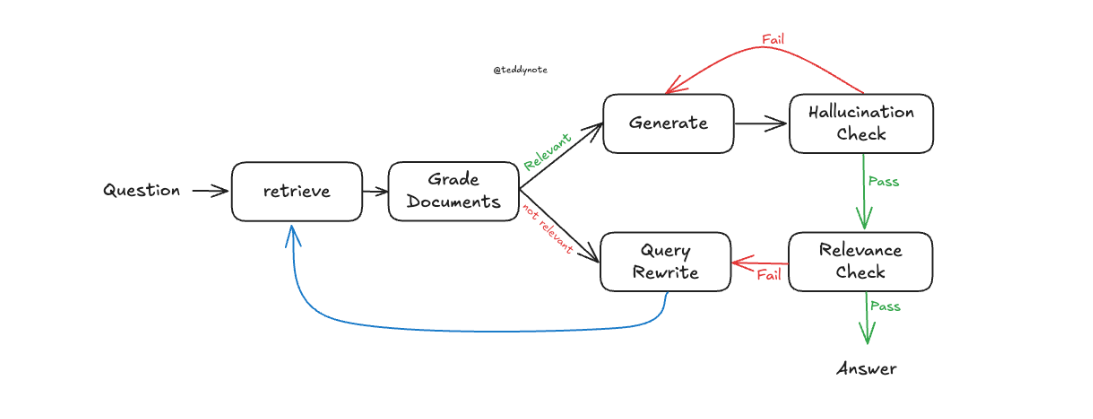
출처 : https://wikidocs.net/270687
위 사진이 Self-RAG의 구조도입니다.
과정들을 살펴봅시다.
1. Retrieve
질의와 관련된 문서를 Retrieve하여 찾습니다.
2. Grade Documents
검색된 문서들을 질문과 빗대어 평가합니다. Yes or No로 평가할 수도 있고, 점수를 매겨 평가할 수도 있습니다.
검색된 문서들을 어떻게 평가할까요? 이는 LLM이 수행합니다.
예시 프롬프트를 작성해 보면
retrieved_documents = [f"{i+1}번째 문서 : {doc}" for i,doc in enumerate(retrieved_documents)]
f'''다음은 질의를 바탕으로 검색된 참고 문서들입니다.
이 문서들이 질의에 대답하기 위해 정말 필요한 문서인지 판단하세요.
답변은 반드시 YES OR NO로만 대답하세요.
사용자 질문 : {question}
검색된 문서 : {retrieved_documents}
답변 :
...'''프롬프트는 간단하게 작성했지만, json으로 출력하도록 강제할 수도 있고, 더 자세한 프롬프트를 통해 답변을 일관되게 내보내게 할 수도 있습니다.
이렇게 작성하여 내부에서 한번 검토한 뒤, 만약 그 답변이 YES라면
3. Generate
참고문서를 바탕으로 질의의 답변을 생성합니다.
4. Hallucination Check
생성된 문장이 사실에 근거한 문장인지 판단합니다.
이는 위에 작성한 프롬프트를 바탕으로 G-Eval 하여 평가됩니다.
점수로 평가하거나, YES OR NO로 평가하거나 등 다양한 바리에이션이 있을 수 있겠습니다.
여기서 Fail을 받는다면 다시 Generate로 돌아갑니다.
5. Relevance Check
생성된 문장이 질문을 해소할 수 있는 정말 유용한 대답인지 평가합니다.
이는 마찬가지로 G-Eval과 같은 방법으로 평가됩니다.
여기서 Fail을 받는다면 Query Rewrite로 돌아갑니다.
6. Query Rewrite
질의를 다시 작성합니다.
기존의 Retrieve 된 문서와 이를 바탕으로 생성한 답변이 기준에 충족되지 않으면 질의를 좀 더 핵심을 묻는 질문으로 바꿉니다.
바꿔진 질문은 제일 처음의 Retrieve 단계로 돌아가 처음부터 RAG과정을 시작합니다.
이처럼 Self-RAG는 직접 검색된 문서와 답변을 비교하며 더 높은 수준의 생성을 이끌어 낼 수 있습니다. 이로서 위에 소개한 RAG의 몇몇 단점 중, Retriever의 성능에 따라 품질이 차이가 난다는 단점을 해결할 수 있죠.
참고 문서가 길다거나, 모든 질문에 RAG가 들어간다는 단점은 Self-RAG 외에 다른 방법들을 조합하여 해결할 수 있습니다.
가령, [3] Grade Document 과정에서 관계가 없는 문서들은 Filtering 하도록 설계하면 해당 문제를 대처할 수 있습니다.
[1] 모든 질문에 RAG를 넣고 싶지 않다면, 제일 앞단에 Query가 RAG가 필요한지 아닌지 구별하는 Router을 둘 수도 있겠습니다.
'
'
'
이렇게 Self-RAG에 대해서 알아봤습니다.
RAG의 개념만 알고 있다면, 사실 이해가 어려운 개념은 아닌 것 같습니다.
늘 말씀드리듯, 적용이 어려운 것 같아요.
만약 또 RAG에 대해 다루게 된다면, 그때는 Self-RAG로 구현해 봐야겠습니다.
감사합니다 !

4개의 댓글

왜 해당 RAG가 등장하게 되었는지 배경부터, 어떤 구조로 구성되어 있는지까지. 핵심적인 내용을 보기 편하게 잘 정리되어 있네요. 잘 읽었습니다!
용준님 좋은 글 감사합니다~!