반갑습니다.
저번 글에 이어서 Text 데이터의 전처리에 대해 설명해보겠습니다.
저번 글에서는 Tokenization을 통해 수많은 텍스트데이터들을 사전으로 만들었습니다.
BPE를 사용하기도 했고 Konlpy, Spacy 등의 다른 Tokenizer에 대해서도 설명했죠.
Vocab = {'나는' : 0, '매우' : 1, '힘들다' : 2 .. ,'어질하다' : 817, .. '에효' : 1000}
이라고 합시다.
ex) '에효 매우 힘들다 어질하다' > [1000, 1, 2, 817]
로 매핑될 수 있겠습니다.
이것을 그대로 모델에 넣게 된다면, 모델이 해석하는 과정에서 다양한 문제점이 생길 수 있습니다.
- '에효' 라는 단어는 '힘들다'의 500배인건가? > 의도하지 않은 편향
- 편향을 없애려고 One-hot vector을 쓰자니, '에효' 는 [0,0,0,0,,,,0,0,0,1]이 되네?
이러면 단어 하나당 천개, 만개의 숫자 메모리를 써야돼... > 메모리의 과소비 - '사과' 와 '배' 라는 단어가 있을 때 이 두 단어는 전부 과일이라는 공통점이 있는데, 그 정보는 담을 수 없을까? > One-hot vector로는 어떤 단어들도 전부 내적(유사도)가 0이 됨
어떡해애애애애애앵
Word Embedding이란 ?
단어를 고정된 크기의 벡터로 바꾸는 작업을 의미합니다.
다양한 방법들이 존재하지만, 단어를 임베딩 벡터로 변환하는 모델들은 Word2Vec, GloVe, FastText 등이 있습니다.
아이디어는 이렇습니다.
32, 13 같은 숫자로 매핑 된 단어들을 뭔가 무수한 숫자들로 표현할 수 있다면, 단어간의 유사도를 판단할 수 있지 않을까? Linear레이어로 변환을 시켜볼까?
가령, P(w|우리집고양이) 라면 뒤에 올 단어들의 확률을
- 용가리 (0.01)
- 강아지 (0.2)
- 츄르를 좋아해(0.79)
로 나타낼 수 있겠습니다.
즉 뭔가 단어들은 앞뒤에 뭐가 나오냐에 따라 비슷한 흐름으로 나오더라 라는것이지요.
이를 학습해보자
라고 해서 탄생한
Word2Vec (워드 투 벡터)
Word2Vec은 주어진 단어와 다른 단어간의 유사성을 판단하여 벡터의 형태로 표현하는 아주 기특한 모델입니다.
어떤 단어를 넣으면, 다른 비슷한 단어들과 유사한 형태의 벡터로 표현하는 모델이라고 보시면 되겠습니다.
모델이니까 학습을 시켜야겠죠? 학습 방법으로는 CBOW, Skip-gram이 있습니다.
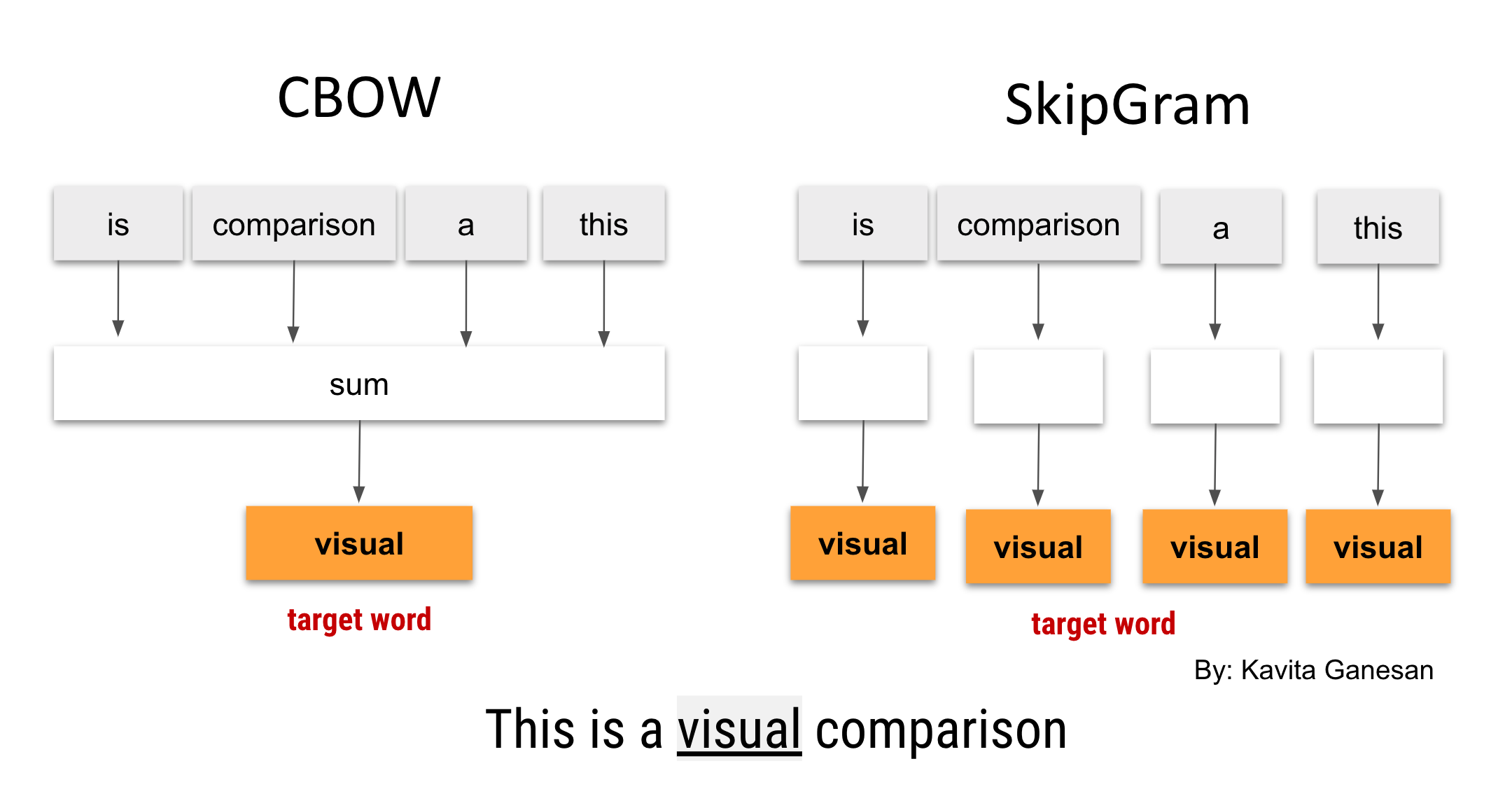
CBOW는 input으로 주변 단어들을 넣어 줍니다.
정답으로는 가운데 단어를 넣어 줍니다.
즉 가운데 단어를 맞추는 Task를 반복 학습 하는 것이지요.
Skip-gram은 반대로 input을 가운데 단어를 하나 줍니다.
정답으로는 주변 단어를 넣어 줍니다.
주변에 단어를 맞추는 Task를 반복 학습합니다.
딱봐도 Skip-gram이 더 어려워 보이지 않나요
한개로 두개, 네개, 여섯개를 맞추랍니다 ㅋㅋ
그래서 Skip-gram으로 학습한 모델의 성능이 일반적으로 더 높습니다.
Word2Vec이 어떻게 구성되는지를 살펴보면
- 단어들을 랜덤한 값으로 매핑 (예를들어 매핑 될 벡터의 크기를 30으로 정했다면 [12] > [0.321, 0.241, -0.32, ...].shape = (1,30) (nn.Embedding을 통해 표현할 수 있습니다.)
- Linear 모델을 통과
- 다시 원래 임베딩의 크기로 한번 더 Linear 모델을 통과
- 그 값이 정답 단어의 임베딩 벡터와 비슷한가?
from torch import nn
import torch
class CBOW(nn.Module):
def __init__(self, vocab_size, dim):
super(CBOW, self).__init__()
self.embedding = nn.Embedding(vocab_size, dim, sparse=True)
self.linear = nn.Linear(dim, vocab_size)
def forward(self, x):
output = self.embedding(x)
output = torch.sum(output, dim = 1)
output = self.linear(output)
return output위 코드는 CBOW 모델의 코드입니다. 간단하죠?
[31, 41, 213, 52, 12] 의 단어들이 있다면
x : [31, 41, 52, 12]
y : [213]
이 되는 것이지요.
Skip-gram 또한 원리를 생각해본다면 코드로 금방 생각해낼 수 있다고 생각합니다. (생략하겠다는 뜻)
그렇게 해서 학습을 끝냈다면 ~???
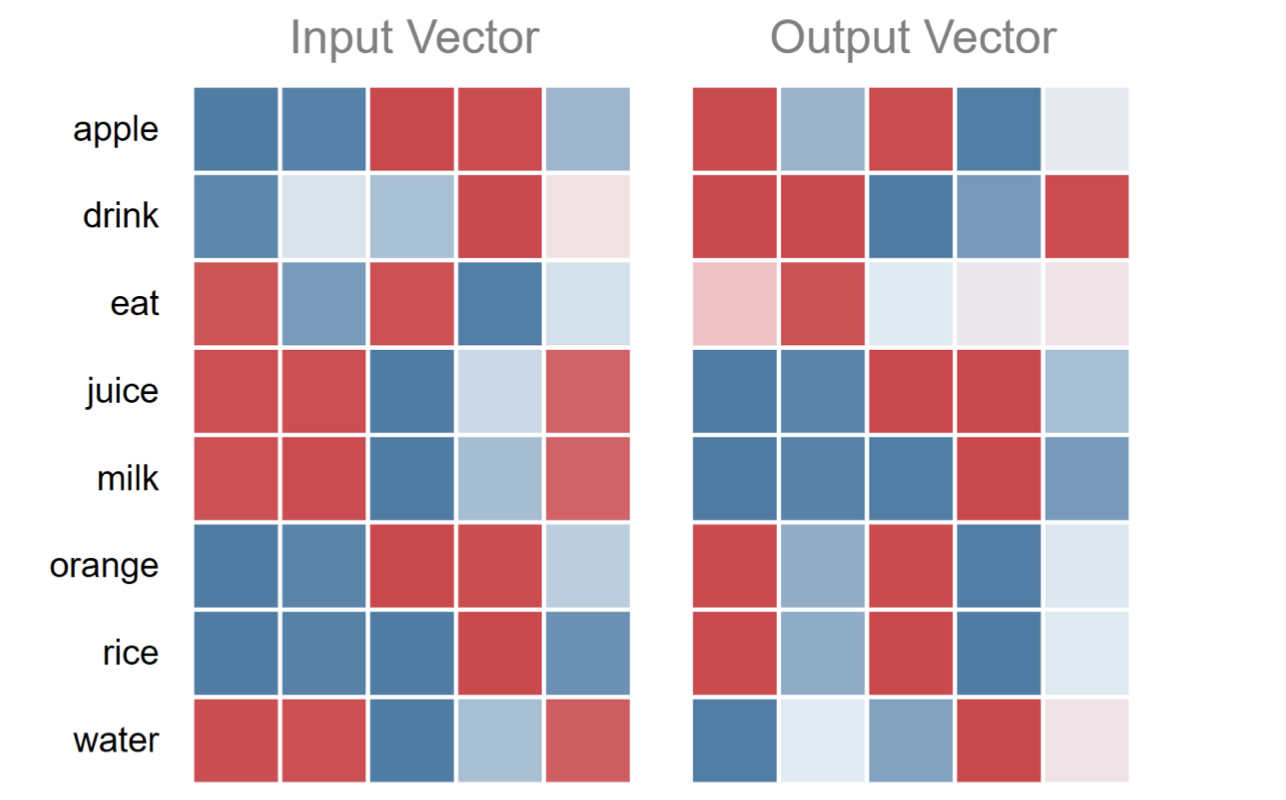
위 사진은 Linear 레이어의 파라미터입니다.
보시면 input의 'eat' 벡터는 output의 'apple', 'orange', 'rice'와 같은 벡터와 비슷하게 생겼죠.
내적값이 높다는 의미입니다.
그말은 즉 유사성을 띄는 단어 벡터를 완성했다는 의미로도 볼 수 있겠습니다.
아이 기특해라 ~~
학습된 Word2Vec 모델은 t-SNE나 PCA를 통하여 차원 축소를 하면 단어 하나하나를 시각화 할 수도 있습니다.
t-SNE는 데이터간의 고차원에서의 유사도와 저차원에서의 유사도를 최소화 하는 방향으로 차원을 축소하는 기법이고, PCA는 데이터간의 분산을 최소화하는 방향으로 차원을 축소하는 기법입니다.
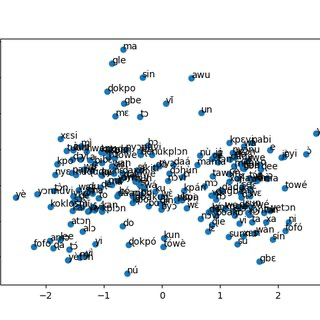
비슷한 단어끼리는 가깝게 있고, 비슷하지 않은 단어들은 멀리 있음을 볼 수 있겠습니다.
'
GloVe나, fastext모델들도 알고리즘은 다르지만, 목적은 결국 단어를 아주 맛있게 표현하는 데에 있습니다.
관심 있으시다면 한번 찾아보시는 것도 도움이 많이 될 것 같습니다.
'
'
'
이로서 텍스트 데이터들의 전처리에 대한 애기를 마치겠습니다.
부족한 부분이 많지만, 제 글이 도움이 되었기를 바랍니다.
감사합니다.
