반갑습니다
이번 글에서는 Unsloth에 대해 소개해볼까 합니다.
원리에 대해서도 간단히 살펴봤는데 .. 쉽지 않더군요.
최근 네이버클라우드의 AI 최적화 인턴에 넣었는데
서류에서 떨어졌습니다.
경량화나 최적화는 아주 어려운 것 같습니다.
Unsloth?
Unsloth는 LLM의 Finetuning과 Inference를 메모리 효율적이며 빠르게 수행할 수 있도록 돕는 오픈소스 라이브러리입니다.(부분 유료)
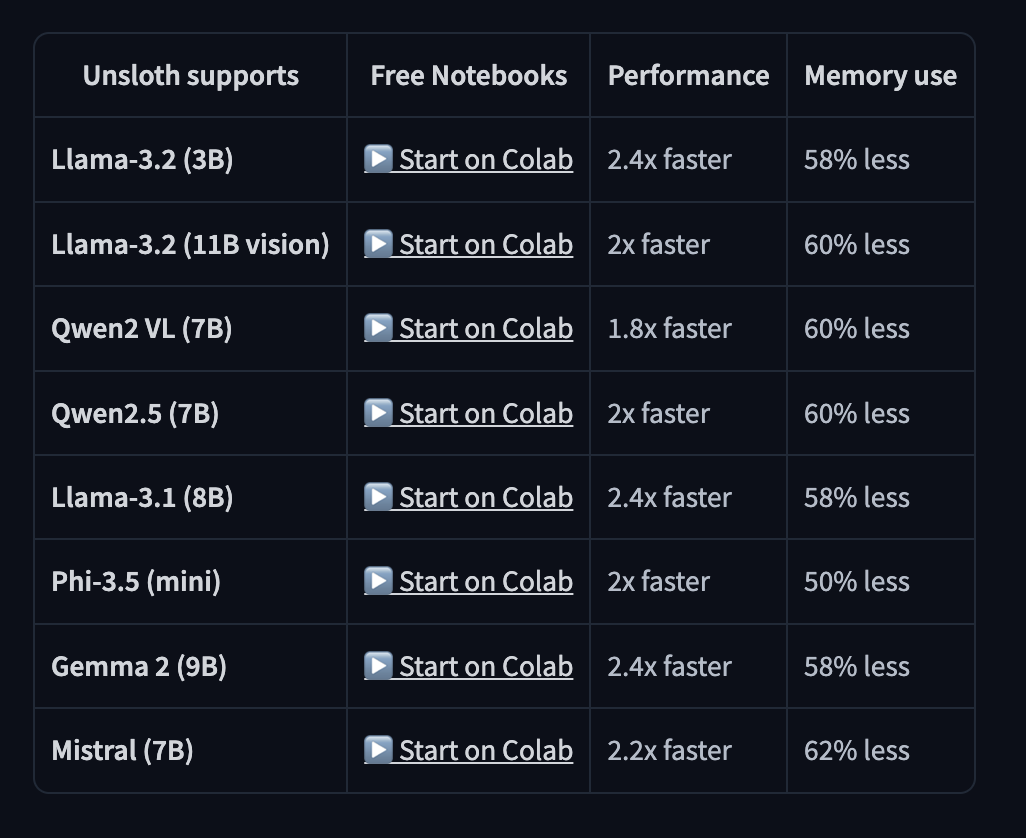
위 사진은 Unsloth에서 지원하는 모델의 일부입니다.
메모리는 평균 55% 이상 절감되며, 속도는 대부분 2배 이상 빠르다고 하는군요.
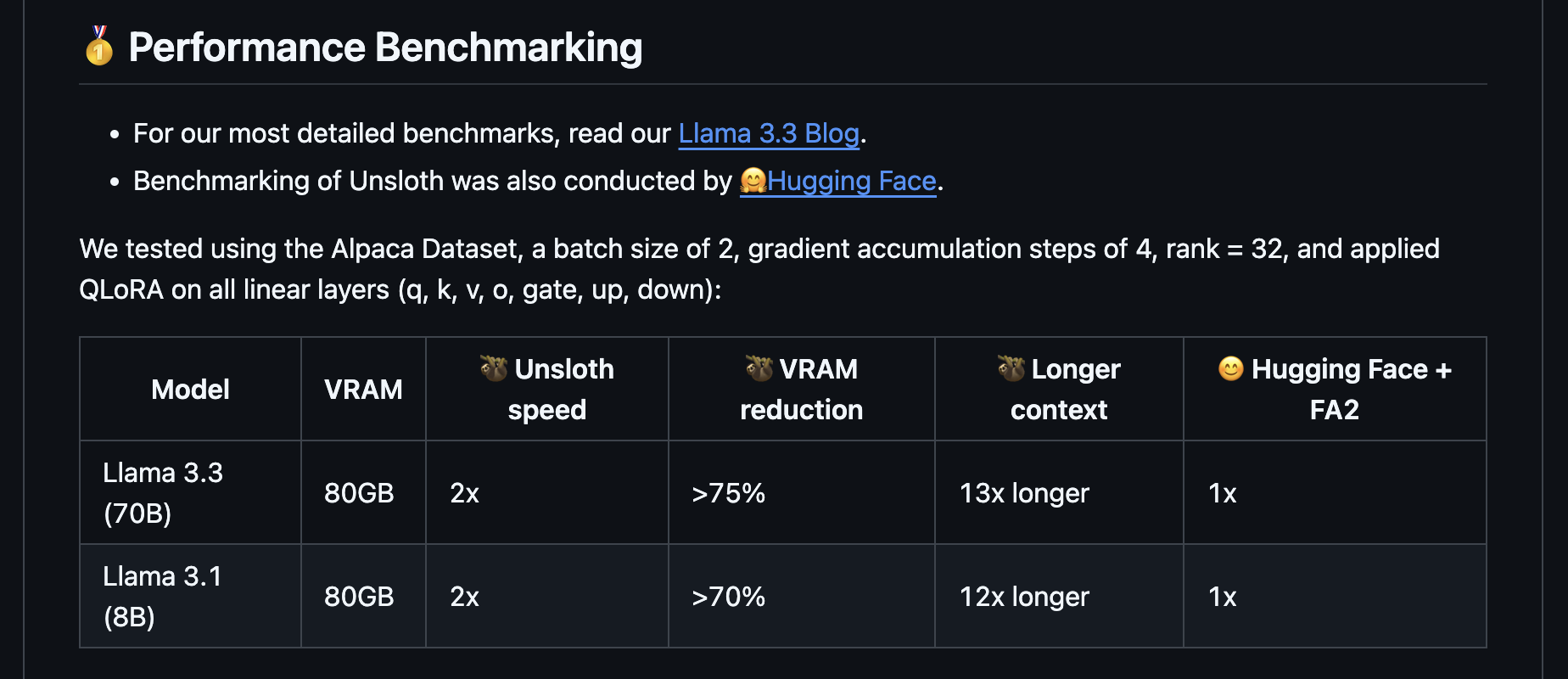
출처 : https://github.com/unslothai/unsloth
또, 최근 출시된 Llama 3.3 70B 모델을 VRAM 80GB GPU에서 QLoRA를 활용해 Finetuning도 가능하다고 합니다.
70B 모델은 fp32기준 기본 크기만으로도
70억 * 4byte(32bit) = 280GB입니다.
여기에 Training할 경우
Optimizer의 메모리 사용량과 (Adam시리즈는 파라미터 한개당 두개 더 필요)
Activation에서의 메모리사용량(약 모델크기의 1~2배)
그래디언트 (모델크기 1배)가 추가로 필요하기에
약 1.4T~1.7T의 VRAM 공간이 필요합니다.
우와 ~~
32GB V100 GPU가 몇개가 필요한거지 ?? ㅎㅎ
그렇다면 Unsloth는 어떤 달란트를 받았길래 이렇게 큰 용량의 모델을 80GB GPU 한장으로 Finetuning할 수 있었을까요
간단히 살펴보겠습니다. (간단히밖에모름)
Cuda Kernel
Cuda Kernel이라는 것이 있습니다.
이게 뭐냐면
GPU가 연산을 하도록 시키는 코드 스크립트입니다.
CPU가 코드를 실행시키도록 하고 GPU가 일하는 구조이죠.
CUDA 커널은 스레드로 실행됩니다.
스레드는 블록 단위로 묶이며, 블록은 다시 그리드(grid) 단위로 구성됩니다.
Global Memory: 모든 스레드가 접근 가능 (느림).
Shared Memory: 같은 블록 내 스레드 간 공유 (빠름).
Register Memory: 각 스레드 전용 (가장 빠름).
Local Memory: 스레드 전용 변수 저장.
//__global__: CUDA 커널임을 나타냄.
__global__ void vector_add(float* a, float* b, float* c, int n) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
// threadIdx.x: 현재 스레드의 ID
// blockIdx.x: 현재 블록의 ID.
// blockDim.x: 각 블록 내의 스레드 수.
if (idx < n) {
c[idx] = a[idx] + b[idx];
}
}이러한 함수를 작성했다고 합시다.
간단한 벡터의 덧셈이죠.
이러한 함수를 CPU에서 실행합니다.
int n = 1024;
float *a, *b, *c;
// ~~~메모리 할당 및 초기화 코드 ~~~
vector_add<<<n/256, 256>>>(a, b, c, n);
// 256개의 스레드로 구성된 블록을 n/256개의 블록으로 실행.이러한 Cuda Kernel들은 어떻게 구성하느냐 어떤 메모리를 사용하느냐 얼마나 오버헤드를 적게하냐 등 다양한 방법으로 속도를 올릴 수 있습니다.
제가 네이버클라우드 인턴에 붙었다면 그러한 작업을 배웠을 수도 있겠군요.
하지만 Cuda Kernel은 큰 단점이 있습니다.
GPU의 아키텍처에 따라 많은 부분이 달라진다는 점이지요.
그러니까 이러한 커널들이 GPU를 뭐를 쓰냐에 따라 너무많이 달라진다는겁니다.
실제로 Cuda Kernel들을 깃허브에서 찾아보면 Matmul 하나에 400줄 정도로 구현돼 있는 것을 볼 수 있습니다.
모국어가 Cpp이신분들만 가능한 일이라고 생각하시면 되겠습니다.
그러면 Unsloth는 이러한 Cuda Kernel들을 C++로 기가막히게 개발한건가요?
그렇지는 않습니다.
Unsloth는 OpenAI에서 개발한 Triton이라는 언어로 커널들을 개발하였습니다.
Triton은 OpenAI에서 개발한 GPU의 Architecture을 자동으로 찾아주는 Kernel 개발 언어입니다.
즉 GPU 구조를 신경 쓸 필요 없이 오로지 Scaled dot attention이나 Optimizing 과정 같은 연산들을 최적화하는 알고리즘에만 신경쓸 수 있도록 해주는 도구이죠.
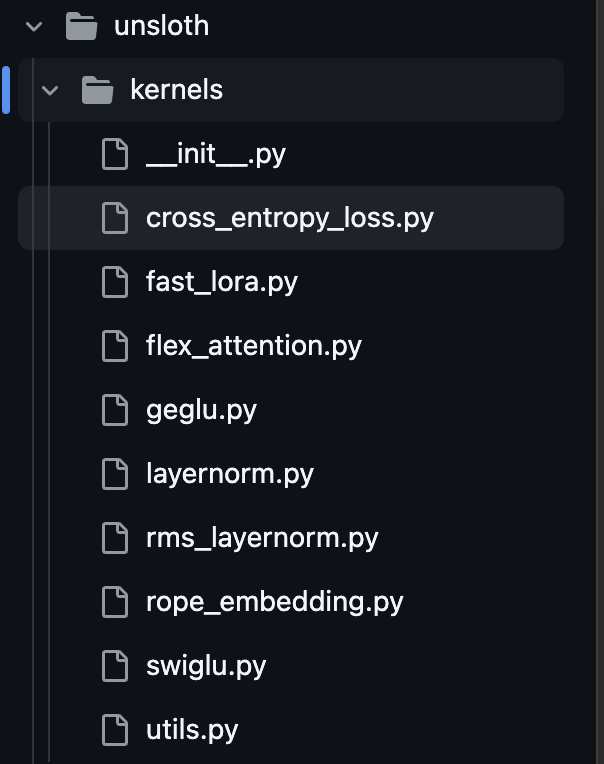
출처 : https://github.com/unslothai/unsloth/tree/main/unsloth/kernels
실제로 Unsloth의 커널들은 모두 .py파일로 작성된 것을 볼 수 있습니다.
들어가서 살펴보니 Unsloth의 개발자분들은
import triton.language as tl으로 선언해서 뭔가를 만드셨더군요.
OpenAI는 대단한 것 같습니다.
'
'
'
제가 설명할 수 있는 부분들은 이정도입니다.
더 자세히 알지 못해 속상하군요.
아무튼 넘어가 어떻게 설치하고 사용하는지에 대해 살펴봅시다.
Unsloth의 설치
Unsloth는 공식 Docs(https://docs.unsloth.ai/get-started/installing-+-updating)에서 자세한 설치 방법을 명시하고 있습니다.
다만 다양한 오류가 많이 발생하기에, 제가 성공한 방법을 공유합니다.
먼저 가장 신경써야 할 부분은 Torch와 본인 GPU의 Cuda Version입니다.
Unsloth는 torch 버전 2.1.0 이하는 지원하지 않습니다.
만약 버전이 낮다면 업그레이드 해야겠죠.
Torch는 뭐 아무데나 임포트하고
import torch
torch.__version__을 통해 알 수 있습니다.
Cuda의 Version은
터미널에 nvidia-smi를 입력해 알 수 있습니다.
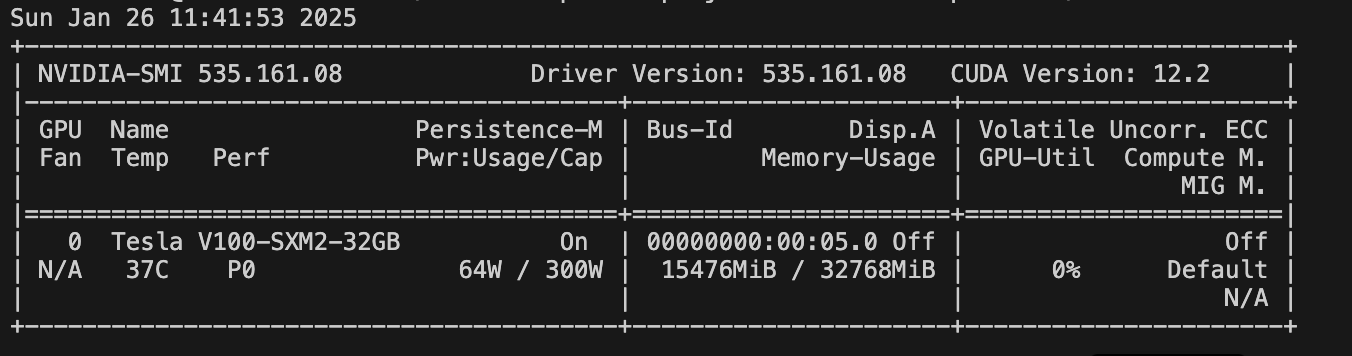
저의 경우, Cuda Version 12.2, 32GB V100 GPU 환경에서 설치하였습니다.
conda init
source ~/.bashrc
apt update
pip install --upgrade pip
pip install torch==2.4.0 torchvision --index-url https://download.pytorch.org/whl/cu121
apt install git
pip install "unsloth[cu121-torch240] @ git+https://github.com/unslothai/unsloth.git”
# torch가 2.4.1로 다시깔림
pip install transformers==4.46.1
apt install build-essential --Y
저같은 경우는 위와 같은 방법으로 다운로드 할 수 있었습니다.
(네이버 부스트캠프 AI Tech의 V100서버 기준입니다.)
핵심적으로 봐야 할 부분은
pip install torch==2.4.0 torchvision --index-url https://download.pytorch.org/whl/cu121
pip install "unsloth[cu121-torch240] @ git+https://github.com/unslothai/unsloth.git”이렇게 두가지 입니다.
torch 버전을 다운받을 때, 쿠다 버전에 따라 뒤에 cu121, cu118 등 바꿔야 합니다.
(Cuda Version 12.2는 121로 다운받으면 되더군요.)
이후, https://docs.unsloth.ai/get-started/installing-+-updating/pip-install 에 방문하여 본인의 torch 버전과 맞는 unsloth를 다운받으면 되겠습니다.
밑의 transformers는 저 버전이 아니면 오류가 나서 추가하였습니다.
또
RuntimeError: Failed to find C compiler. Please specify via CC environment variable.
라는 에러가 발생했습니다.
시스템에 C 컴파일러가 설치되지 않았거나, 설치된 컴파일러가 시스템에서 제대로 인식되지 않는 경우 발생한다고 하는군요.
따라서 gcc 및 기타 필수 도구가 포함돼 있는 build-essential을 재설치하였습니다.
아무튼 어찌저찌 다운을 받으셨다면

다음과 같이 이쁘게 임포트가 되는지 확인하고 사용하시면 되겠습니다.
사용 방법은 그리 어렵지 않습니다.
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
# Can select any from the below:
# "unsloth/Qwen2.5-0.5B", "unsloth/Qwen2.5-1.5B", "unsloth/Qwen2.5-3B"
# "unsloth/Qwen2.5-14B", "unsloth/Qwen2.5-32B", "unsloth/Qwen2.5-72B",
# And also all Instruct versions and Math. Coding verisons!
model_name = "unsloth/Qwen2.5-7B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)위처럼 불러와 사용하면 됩니다.
model_name은 https://docs.unsloth.ai/get-started/all-our-models 해당 페이지에서 찾아보실 수 있습니다.
저같은 경우는 Unsloth를 활용하여 Qwen 2.5 32B 모델을 32GB GPU에서 10초정도의 Latency로 QA Task를 수행할 수 있었습니다.
Finetuning은 해보지 않아서 잘 모르지만 .. 아마 14B정도의 모델은 32GB 이내의 메모리 사용량으로 학습이 가능한걸로 알고 있습니다.
Finetuning도 자세한 과정을 소개해드리고 싶지만
https://docs.unsloth.ai/get-started/unsloth-notebooks
여기에 너어무나도 자세히 예쁘고 착하게 작성이 돼 있어 생략합니다.
사실 Unsloth는 설치가 제일 어렵기에 그 부분만 성공하면 다들 무리없이 사용하실 수 있을거라고 생각합니다.
'
'
'
이번 Unsloth에 대한 글을 여기서 마칩니다.
혹시라도 설치가 어려우신 분들은 댓글 남겨주시면 같이 고민해보면 좋을 것 같습니다.
읽어주셔서 감사합니다 !
