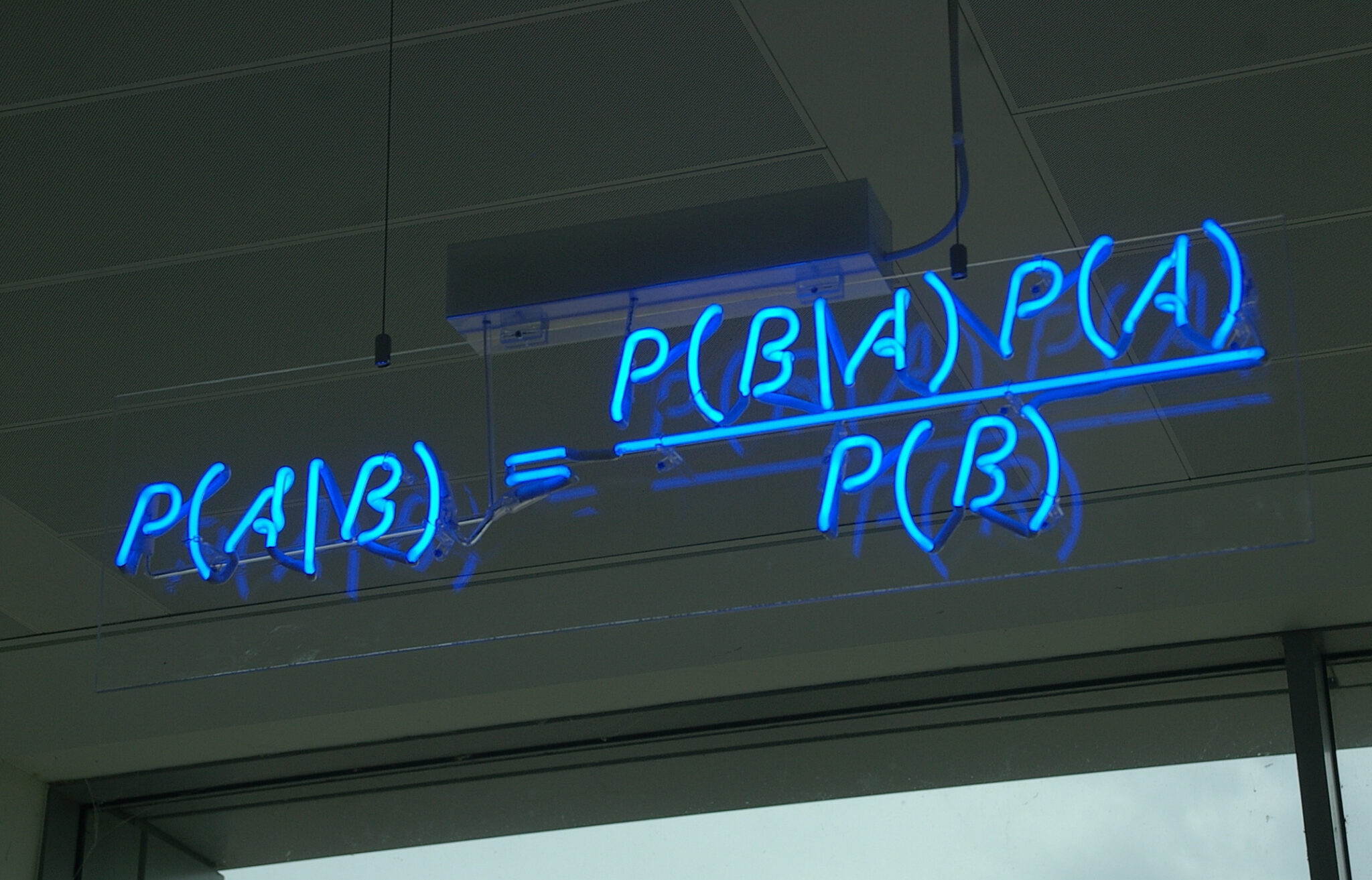
확률
- 어떤 사건이 일어날 가능성을 0과 1사이의 값으로 나타낸 것
- 표본공간 : 일어날 수 있는 모든 결과들의 집합
- 근원사건 : 일어날 수 있는 각각의 결과
- 사건 : 어떤 특성을 갖는 결과들의 집합 (표본공간의 부분집합)
- P(A) : 사건 A가 발생활 확률
- 배반(disjoint) : 두 사건 A,B의 교집합이 공집합인 경우
- 수학적 확률은 이론적인 것이고 통계적 확률은 실험적인 것이다
- 다만 통계적확률이 극한으로 간다면 수학확률로 수렴하게된다
- 여사건, 합사건, 곱사건
조건부확률
- 한 사건의 결과가 다른 사건의 확률에 영향을 미치는 경우
- 사건 B가 일어났을 때의 사건 A가 일어날 확률인 와 그냥 사건 A가 일어날 확률인 는 다름
- 원래의 사건 A가 일어날 확률의 표본공간은 전체인 반면 사건 B가 발생했다는 가정을 하게되면 표본공간이 B로 바뀌게 된다. 그 안에서 A가 일어날 확률은 인 것이다.(B밖의 A는 필요가 없으니)
사건의 독립
- A,B가 독립이라는 것은 라는 뜻이다
- 즉 B가 일어나든말든 A가 일어날 확률은 그대로임
- 위 유도로 독립사건 A,B 사이에는 라는 사실을 알수있다.
베이즈 정리
베이지안 주의
통계학의 대표적인 관점으로 빈도주의관점과 베이지안관점이 있다. 쉽게 말해 동전을 던지면 빈도주의는 100번중 50번정도 앞면이 나온다라고 말하는 반면 베이지안에서는 동전을 한번 던지면 앞면이 나올 확률이 50%라고 대답한다. 겉보기엔 비슷한 개념같아 보여도 실제 실험을 통해 결과를 얻어내는 빈도주의와 달리 베이지안은 확률에 대한 믿음(신뢰도)에 기반한다
전체확률의 법칙
- 전체의 표본공간을 분할하는 N개의 A1,A2,...,An이라는 배반의 사건들이 존재할때 사건 B가 일어날 확률은 모든 를 더한 값이 된다.
- 이를 곱셈법칙을 이용해 변형하면 위의 식이 나오게 된다.
베이즈 정리
- 공식만 보고는 이해할 수 없는 정리이다.
- 좌변의 조건부 확률은 사후 확률로써 구하고자하는 값이며 나중에 일어나는 사건 A를 전제로 하는 조건부 확률이다
- 우변의 P(B)는 사전확률로 우리가 이미 알고있는 사건 B가 일어날 확률이다.
- 우변의 분자의 조건부 확률은 우도 혹은 가능도로 사건이 일어날 가능도 정도로 이해하면 될 것이다. 또한 이는 추후 확률을 구하기 위해서 중요한 역할을 한다
- 그리고 분모의 P(A)는 표본공간이 A로 바꼈다고 생각하면 편하다.
베이즈 정리를 보면 대충만 봐서는 어떤 공식이고 왜 쓰는지 잘 알수가 없다. 또한 개념을 이해하는것도 무척 어렵다. 예를 들어 전국 사람들의 성별에 따른 키를 조사했다고 하자. 그럼 사전확률은 성별이 될것이다. 남자가 50% 여자가 50%와 같이. P(B)를 성별의 확률로 하고 P(A)를 키가 170이라고하자. 여자중 키가 170이 몇명인지 남자중 키가 170이 몇명인지 남자는 총 몇명인지에 대한 정보를 모두 가지고 있다. 또한 전체에서 키가 170인 사람이 몇명인지도 쉽게 알수있다. 이러한 자료를 알고있을 때 "만약 키가 170인 사람이있는데 이사람이 남자일까?" 라는 질문을 던지면 답할 수 있다.
이게 베이즈 정리의 핵심이다. 우리는 성별에 따른 키를 조사하였지만 키에 따른 성별에 대한 질문에도 답을 할 수 있게된다. 개념적으로 접근하였을 때 A사건이 먼저 일어날때 우리는 보통 이를 전제 혹은 원인이라하고 나머지 B사건을 결과라고한다. 하지만 B라는 결과가 나왔을 때 A라는 사건이 이것의 원인이었을 확률을 구할 수 있어야한다는 것이다. 시간상으로 차이가 있더라도 B가 A의 전제가 되지 말라는 법은 없다. 8시에 일어나서 9시에 출근하는 사람도 있고 7시에 일어나서 9시에 출근하는 사람도있고 물론 8시 10시에 출근하는 사람도 있을테다. 하지만 9시에 이사람이 출근했다면 8시에 일어났을 확률?을 묻는 것이 베이즈 정리이다. 물론 시간적으로 기상보다 출근이 더 늦지만 충분히 전제가 될 수 있다라는 것이다.
이러한 베이즈 정리는 다양한 알고리즘으로 실생활에 적용된다. 점점 더 데이터가 많아지는 빅데이터 세상에서는 더 유용하다. 예를들어 사용자가 좋아요와 싫어요 버튼을 통해 우리에게 사전확률을 제공한다면 우리는 이를 보고 이사람에서 A를 제공했을때 좋아할지 B를 제공했을 때 좋아할지 어떤것이 더 좋을지에 대한 결론을 내린다. 이러한 결론들은 계속들어오는 정보를 토대로 갱신되며 사용자에게 적절한 추천을 해줄 수 있다는 것이다. 사용자는 좋아한다 무엇을 이라는 정보를 주면 관리자는 얼마나 좋아할까 이것을이라는 것에 대한 결론을 내릴 수 있게 하는 것이 베이즈 정리이다.
