K-최근접 이웃 알고리즘
K-Nearest Neighbors (KNN or K-NN)
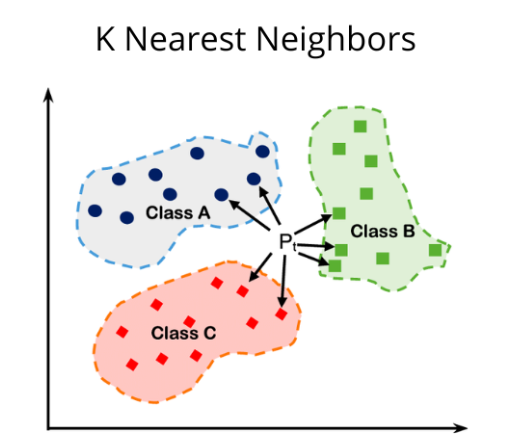
What?
- 머신러닝의 지도학습 알고리즘 중 하나.
- 새로운 데이터 포인트에서 가장 가까운 k개의 이웃을 찾고, 가장 빈도가 높은 클래스를 예측값으로 사용하는 알고리즘.
When?
- 데이터를 분류하거나 회귀할 때.
장단점
장점
- 이해하기 쉽다.
- 적은 조정으로 좋은 성능을 발휘한다.
단점
- 훈련 세트가 매우 크면 예측이 느려짐.
- 많은 특성을 가진 데이터셋에는 잘 동작하지 않음.
- 특성 값 대부분이 0인 데이터셋과는 특히 잘 동작하지 않음.
How?
# 필요한 라이브러리 import
from sklearn.datasets import load_iris # 데이터
from sklearn.model_selection import train_test_split # 데이터 분할
from sklearn.neighbors import KNeighborsClassifier # K-최근접 알고리즘 모듈
# 데이터 가져오기
iris_datasets = load_iris()
# 학습용, 테스트용 으로 데이터 분할 (75%, 25%)
X_train, X_test, y_train, y_test = train_test_split(iris_dataset['data'], iris_dataset['target'], random_state=0)
# K-최근접 이웃 알고리즘 적용. 학습용 데이터 사용
knn = KNeighborsClassifier(n_neighbors=1) # k=1 적용
knn.fit(X_train, y_train)
# 정확도 측정. 테스트용 데이터 사용
print("테스트 세트의 정확도 : {.2f}".format(knn.score(X_test,y_test)))
커피를 넣으면 코드가 나옵니다.