스택
- 물건을 쌓아 올리듯 자료를 쌓아 올린 형태의 자료구조
- 스택에 저장된 자료는 "선형 구조"를 갖는다.
- 선형 구조 : 데이터 요소들 사이에 순서가 존재
- 비선형 구조 : 데이터 요소가 순차적으로 나열되지 않음
- 스택에서 자료를 삽입하거나 스택에서 자료를 꺼낼 수 있다.
- LIFO (Last In First Out)
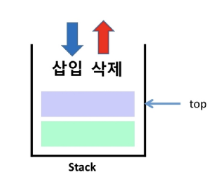
스택의 주요 연산
- Push : 삽입
- Pop : 삭제
- IsEmpty : 공백 확인
- Peek : 최상단 자료 확인
class Stack:
def __init__(self, capacity = 10):
self.capacity = capacity
self.items = [None] * capacity
self.top = -1
def is_empty(self):
return self.top == -1
def is_full(self):
return self.top == self.capacity - 1
def get_size(self):
return self.top + 1
def peek(self):
if self.is_empty():
raise IndexError("Stack is empty")
return self.items[self.top]
def push(self, item):
if self.is_full():
raise IndexError("Stack is full")
self.top += 1
self.items[self.top] = item
def pop(self):
if self.is_empty():
raise IndexError("Stack is empty")
itme = self.items[self.top]
self.items[self.top] = None
self.top -= 1
return item
파이썬에서는 list의 append()와 pop(), len()을 활용하여 쉽게 스택을 이용할 수 있다.
stack = []
# push
stack.append('a')
stack.append('b')
stack.append('c') # stack = ['a', 'b', 'c']
# pop
stack.pop() # c 출력, stack = ['a', 'b']
# peek
stack[len(stack)] # b 출력, stack = ['a', 'b']큐
- 스택과 마찬가지로 삽입과 삭제의 위치가 제한적인 자료구조
- FIFO (First In First Out)

큐의 주요 연산
- EnQueue : 삽입
- Dequeue : 삭제
- IsEmpty : 공백인지 확인
- Peek : 가장 앞쪽의 원소 확인
class Queue:
def __init__(self, capacity = 10):
self.capacity = capacity
self.items = [None] * capacity
self.front = -1
self.reer = -1
def is_empty(self):
return self.front == self.rear
def is_full(self):
return self.rear == self.capacity - 1
def peek(self):
if self.is_empty():
raise IndexError("Queue is empty")
return self.items[self.front + 1]
def get_size(self):
return self.rear - self.front
def enqueue(self, item):
if self.is_full():
raise IndexError("Queue is full")
self.rear += 1
self.items[self.rear] = item
def dequeue(self):
if self.is_empty():
raise IndexError("Queue is empty")
self.front += 1
item = self.items[self.front]
self.items[self.front] = None
return item여기서 문제점이 있음
잘못된 포화 상태 인식
삽입과 삭제를 반복하다 보면 리스트의 앞부분이 None임에도 불구하고 포화상태로 인식할 수 있다.

이를 위해 항상 앞쪽을 채우도록 하려면 한번의 삭제마다 n번의 이동이 필요하다. -> 매우 비효율적
이를 해결하기 위해 원형 큐를 사용할 수 있다.
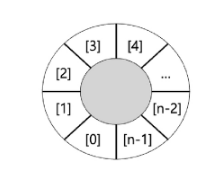
class CircleQueue:
def __init__(self, capacity = 10):
self.capacity = capacity + 1
self.items = [None] * self.capacity
self.front = 0
self.rear = 0
def is_empty(self):
return self.front == self.rear
def is_full(self):
return (self.rear + 1) % self.capacity == self.front
def peek(self):
if self.is_empty():
raise IndexError("Queue is empty")
return self.itmes[(self.front + 1) % self.capacity]
def get_size(self):
return (self.rear - self.front + self.capacity) % self.capacity
def enqueue(self, item):
if self.is_full():
raise IndexError("Queue is full")
self.rear = (self.rear + 1) % capacity
self.items[self.rear] = item
def dequeue(self):
if self.is_empty():
raise IndexError("Queue is empty")
self.front = (self.front + 1) % self.capacity
item = self.items[self.front]
self.items[self.front] = None
return item파이썬에서 deque라는 라이브러리로 쉽게 사용가능하다.
연결 리스트
기존의 리스트에서 중간에 특정 값을 삭제하면 뒤의 모든 값을 앞으로 이동시켜야 하는 문제가 있다. 이렇게 하면 한 번의 삭제에 n번의 연산이 필요한 겂이다. 이를 해결하기 위해 연결 리스트를 사용할 수 있다.
- 자료의 논리적 순서와 메모리 상의 물리적 순서가 일치하지 않음
- 링크로 원소에 접근
- 자료구조의 크기를 동적으로 조정 가능 = 메모리의 효율적인 사용이 가능
연결 리스트의 기본 구조
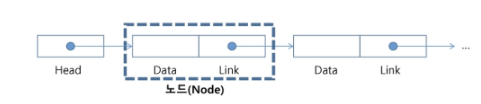
- 노드
-
연결 리스트에서 하나의 원소를 표현하는 구성 요소
-
구성요소
- 데이터 필드 : 원소의 값 저장
- 링크 필드 : 다음 노드의 참조 값을 저장
- 데이터 필드 : 원소의 값 저장
-
- 헤드
- 연결 리스트의 첫 노드에 대한 참조 값
단순 연결 리스트(Singly Linked List)
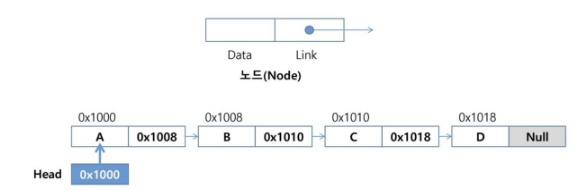
- 노드가 하나의 링크 필드에 의해 다음 노드와 연결되는 구조
- 헤드가 가장 앞의 노드를 가리키고, 링크 필드가 연속적으로 다음 노드를 가리킨다.
- 링크 필드가 Null인 노드가 가장 마지막 노드이다.
class Node:
def __init__(self, data):
self.data = data
self.next = None
class SinglyLinkedList:
def __init__(self):
self.head = None
def is_empty(self):
return self.head is None
def insert(self, data, position):
new_node = Node(data)
if position == 0:
new_node.next = self.head
self.head = new_node
else:
current = self.head
for _ in range(position - 1):
if current is None:
print("범위를 벗어난 삽입입니다.")
return
current = current.next
new_node.next = current.next
current.next = new_node
def append(self, data):
new_node = Node(data)
if self.is_empty():
self.head = new_node
else:
current = self.head
while current.next:
current = current.next
current.next = new_node
def delete(self, position):
if self.is_empty():
print("싱글 링크드 리스트가 비었습니다.")
return
if position == 0:
deleted_data = self.head.data
self.head = self.head.next
else:
current = self.head
for _ in range(position - 1):
if current is None or current.next is None:
print("범위를 벗어났습니다.")
return
current = current.next
deleted_node = current.next
deleted_data = deleted_node.data
current.next = current.next.next
return deleted_data
def search(self, data):
current = self.head
position = 0
while current:
if current.data == data:
return position
current = current.next
position += 1
return -1
def __str__(self):
result = []
current = self.head
while current:
result.append(current.data)
current = current.next
return str(result)장점
- 필요한 만큼만 메모리를 사용
단점
- 특정 요소에 접근하려면 순차적으로 탐색 (O(n))
- 역방향 탐색 불가
이중 연결 리스트(Doubly Linked List)
역방향 탐색이 가능하도록 링크 필드를 두 개, 데이터 필드 한 개로 구성
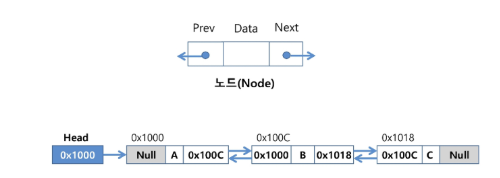
삽입 연산
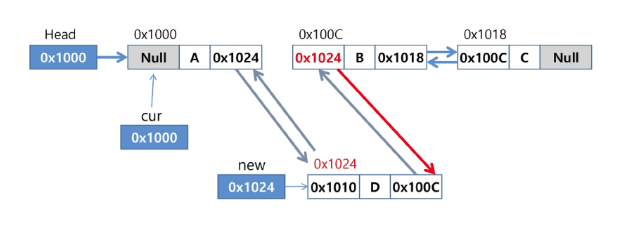
삭제 연산


커피를 넣으면 코드가 나옵니다.