Kubernetes ELK
Filebeat
만약 많은 애플리케이션이 분산되어 있고, 각 애플리케이션이 로그 파일들을 생성한다. 만약 해당 로그 파일을 하나의 서버에 일일이 ssh 터미널을 이용하여 로그 파일을 수집하는 것은 합리적이지 않다. 만약 엄청난 규모의 서비스이고 분산되어 있는 서비스의 애플리케이션이 수백개라고 생각하면 ssh를 이용하는 방법은 생각하기도 싫은 방법이다. 이런 상황에서 Filebeat는 로그와 혹은 파일을 경량화된 방식으로 전달하고 중앙 집중화하여 작업을 보다 간편하게 만들어 주는 역할을 한다.
Filebeat는 로그 데이터를 전달하고 중앙화하기 위한 경량의 Producer이다. 서버의 에이전트로 설치되는 Filebeat는 저장한 로그 파일 또는 위치를 모니터링하고 로그 이벤트를 수집한 다음 인덱싱을 위해 Elasticsearch 또는 Logstash로 전달한다.
> Filebeat 작동 방식
: Filebeat를 시작하면 설정에서 지정한 로그데이터를 바라보는 하나이상의 inputs을 가진다. 지정한 로그 파일에서 이벤트가 발생할 때마다 Filebeat는 데이터 수확기를 시작한다. 하나의 로그파일을 바라보는 각 havester는 새 로그 데이터를 읽고 libbeat에 보낸다. 그리고 libbeat는 이벤트를 집계하고 집계된 데이터를 Filebeat설정에 구성된 출력으로 데이터를 보낸다.
Kubernetes에 ELK 구축
Elasticsearch는 분산형 RESTful 검색 및 분석 엔진으로 엘라스틱 스택의 중심에 위치하고 있으며, 엘라스틱 스택은 차세대 데이터 플랫폼으로 자리잡고 있다.
- Elasticsearc: 검색,분석,데이터 저장소 역할
- Beats: 데이터 수집 역할
- Logstash: 정제, 전처리를 수행
- Kibana: 시각화, 관리 기능
Linux 또는 Windows에 직접 설치가 가능하나, 컨테이너로 배포 시 scale-out의 장접과 OS의 따른 영향을 받지 않기 때문에 쿠버네티스에 ELK를 구축하는 방법을 알아본다.
> Elasticsearch
Elasticsearch의 경우 Deployment로 구성하게 되면 Pod가 종료 될시 컨테이너 내의 데이터가 모두 삭제 되기 때문에 데이터를 유지할 수 있는 StatefulSet으로 구성해야 한다.
1. eleasticsearch-configmap.yaml
elasticsearch.yml 파일을 configmap으로 관리하기 위하여 생성한다. 상황에 따라 Master node, data node, ingest node로 구성하여 관리할 수 있다.
apiVersion: v1
kind: ConfigMap
metadata:
namespace: elk
name: elasticsearch-config
labels:
app: elasticsearch
#role: data
data:
elasticsearch.yml: |-
cluster.name: ${CLUSTER_NAME} # 클러스터 이름
#node.name: ${NODE_NAME} # 노드 이름
#discovery.seed_hosts: ${NODE_LIST} # 노드 리스트
#cluster.initial_master_nodes: ${MASTER_NODES} # 마스터 노드
network.host: 0.0.0.0 # 외부 접근
#node: # 노드 정보 옵션
# master: false
# data: true
# ingest: false
#xpack.security.enabled: true # X pack의 경우 보안설정
#xpack.monitoring.collection.enabled: true2. elasticsearch-persistentvolume.yaml
Persistent volume(PV)란 관리자에 의해 생성된 볼륨으로 사용자가 Persistent Volume Claim(PVC)을 통해 PV에 볼륨을 요청하고 그에 맞는 볼륨이 있을 경우 바인딩하여 할당한다.
컨테이너 내의 elasticsearch data를 worker node의 Host Path(서버 경로)로 백업이 되어 Pod가 종료되어도 데이터는 유지가 된다.
replicas 수에 따라 Pod가 0,1,2,3 등 순차적으로 생성이 되기 때문에 PV 또한 수량을 맞춰 주어야 한다.
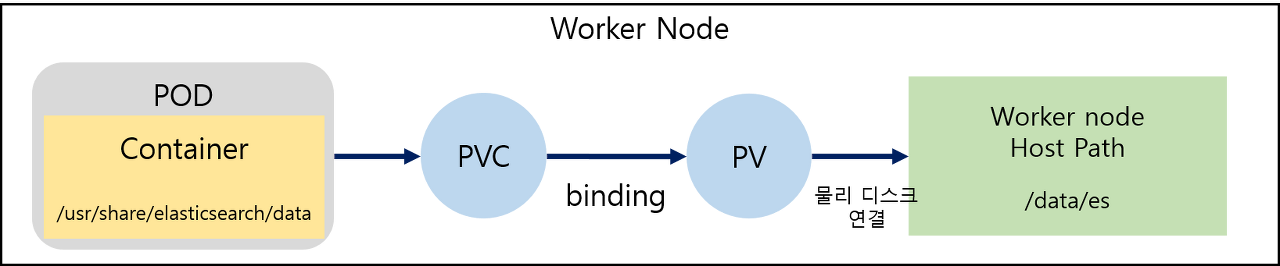
apiVersion: v1
kind: PersistentVolume
metadata:
name: elasticsearch-pv
labels:
io.kompose.service: elasticsearch
spec:
storageClassName: standard # 스토리지 클래스를 지정하여 해당 클래스에 맞는 PVC와 연결
capacity:
storage: 1Gi # 사용 용량 1GB
volumeMode: Filesystem # FileSystem 으로 사용
accessModes:
- ReadWriteOnce # 하나의 노드에서만 읽고 쓸 수 있다.
claimRef: # 특정 PVC를 연결할 때, 지정을 하지 않으면 동적 바인딩 된다.
name: elasticsearch-persistent-storage-elasticsearch-node-0 # {PVC name}-{StatefulSet name}-{pod index}로 구성
persistentVolumeReclaimPolicy: Delete # 반환 정책, 동적 프로비저닝시 기본 반환 정책은 Delete이다.
hostPath:
path: /data/es
type: DirectoryOrCreate # 디렉토리가 없으면 생성하여 매핑 , Director-이미 생성된 디렉토리에 매핑하고 없을 경우 에러3. elasticsearch-statefulset.yaml
statefulset으로 elasticsearh pod 생성
apiVersion: apps/v1
kind: StatefulSet
metadata:
namespace: elk
name: elasticsearch-node
labels:
app: elasticsearch
#role: data
spec:
serviceName: "elasticsearch"
selector:
matchLabels:
app: elasticsearch
replicas: 1
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
#image: docker.elastic.co/elasticsearch/elasticsearch-oss:7.9.3
image: docker.elastic.co/elasticsearch/elasticsearch-oss:6.8.23
imagePullPolicy: IfNotPresent
env:
- name: CLUSTER_NAME
value: elk-cluster
#- name: discovery.seed_hosts
# value: "elasticsearch"
- name: discovery.type
value: single-node
- name: "ES_JAVA_OPTS"
value: "-Xms300m -Xmx300m"
ports:
- name: rest
containerPort: 9200
- name: transport
containerPort: 9300
volumeMounts:
- name: config
mountPath: /usr/share/elasticsearch/config/elasticsearch.yml
readOnly: true
subPath: elasticsearch.yml
- name: elasticsearch-persistent-storage
mountPath: /usr/share/elasticsearch/data
- name: tz-seoul
mountPath: /etc/localtime
initContainers:
- name: fix-permissions
image: busybox
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: elasticsearch-persistent-storage
mountPath: /usr/share/elasticsearch/data
volumes:
- name: config
configMap:
name: elasticsearch-config
- name: tz-seoul
hostPath:
path: /usr/share/zoneinfo/Asia/Seoul
volumeClaimTemplates:
- metadata:
name: elasticsearch-persistent-storage
annotations:
volume.beta.kubernetes.io/storage-class: "gp2"
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: standard
resources:
requests:
storage: 1GiInit Container
- 역할: pod의 app container들이 실행되기 전에 실행되는 특수한 container이며 app image는 없는 utility, 설정 script등을 포함할 수 있다.
- 초기화 container는 containers 배열과 나란히 pod spec에 명시할 수 있다.
- 일반 container와 유사한 점: 항상 완료를 목표로 실행한다 .각 초기화 container는 다음 init container가 시작되기 전에 성공적으로 완료되어야 한다.
- 일반 container와 차이점: 초기화 컨테이너는 앱 컨테이너의 리소스 상한, 볼륨, 보안 세팅을 포함한 모든 필드와 기능을 지원한다. 그러나, 초기화 컨테이너를 위한 리소스 요청량과 상한은 다르게 처리된다.
- 만약 pod의 init container가 실패하면 kubelet은 init container가 성공할 때 까지 반복적으로 재시작한다. 그러나, 만약 pod의 restartPolicy를 Never로 설정했을 때, 실패하면 k8s는 전체 pod가 실패한 것으로 처리한다.
4. elasticsearch-service.yaml
내부 연결형과 외부 연결용으로 2개의 서비스 생성
apiVersion: v1
kind: Service
metadata:
namespace: elk
name: elasticsearch
labels:
app: elasticsearch
spec:
clusterIP: None
ports:
- name: rest
port: 9200
- name: transport
port: 9300
selector:
app: elasticsearch
---
kind: Service
apiVersion: v1
metadata:
namespace: elk
name: elasticsearch-nodeport
labels:
app: elasticsearch
spec:
type: NodePort
ports:
- nodePort: 30920
port: 9200
targetPort: 9200
protocol: TCP
selector:
app: elasticsearchelasticsearch의 pvc와 pv가 binding 되지 않음
storageclass.storage.k8s.io "--" not found
: Storage Class를 생성하여 binding한다.
: storage class name 지정 시 namespace 꼭 지정해주기 !
> Logstash
1. logstash-configmap.yaml
logstash.conf 파일과 logstash.yaml 파일을 configmap을 생성하여 관리할 수 있다.
input,filter,output 정보는 상황에 맞게 작성한다.
elasticsearch로 데이터를 output으로 지정시 url은 {elasticsearch service name}:{elasticsearch service port}로 연결한다.
apiVersion: v1
kind: ConfigMap
metadata:
namespace: elk
name: logstash-configmap
labels:
task: logging
k8s-app: logstash
data:
logstash.yml: |
http.host: "127.0.0.0"
path.config: /usr/share/logstash/pipeline
logstash.conf:
input
{
tcp
{
port => 5000
}
}
filter
{
json
{
source => "message"
remove_field => ["@version","beat","count","fields","input_type","offset","source","host","tags","port","message"]
}
}
output
{
elasticsearch
{
hosts => ["elasticsearch:9200"]
manage_template => false
index => "my_index"
document_type => "doc"
}
}2. logstash-deployment.yaml
logstash Deployment 생성과 docker repository에서 logstash 이미지를 다운로드 하며 logstash.conf 파일은 volume에 매핑 시켜준다.
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: elk
name: logstash
spec:
replicas: 1
selector:
matchLabels:
app: logstash
template:
metadata:
labels:
app: logstash
spec:
containers:
- name: logstash
image: docker.elastic.co/logstash/logstash-oss:6.8.23
ports:
- name: logstash-tcp
containerPort: 5000
imagePullPolicy: IfNotPresent, # Always, Never
volumeMounts:
- name: config-volume
mountPath: /usr/share/logstash/config
- name: logstash-pipeline-volume
mountPath: /usr/share/logstash/pipeline
- name: tz-seoul
mountPath: /etc/localtime
volumes:
- name: tz-seoul
hostPath:
path: /usr/share/zoneinfo/Asia/Seoul
- name: config-volume
configMap:
name: logstash-configmap
items:
- key: logstash.yml
path: logstash.yml
- name: logstash-pipeline-volume
configMap:
name: logstash-configmap
items:
- key: logstash.conf
path: logstash.conf3. logstash-service.yaml
컨테이너 간의 logstash 통신할때는 아래와 같이 내부용 서비스를 생성하지만, 외부로부터 데이터를 수집하게 된다면, eternalIP 또는 NodePort 등을 이용하여 외부 접근을 허용하게 한다.
apiVersion: v1
kind: Service
metadata:
namespace: elk
name: logstash
labels:
app: logstash
spec:
clusterIP: None
ports:
- name: logstash-tcp
port: 5000
selector:
app: logstash> Kibana
1. kibana-configmap.yaml
kibana.yaml 파일을 configmap을 통해 관리한다.
apiVersion: v1
kind: ConfigMap
metadata:
namespace: elk
name: kibana-config
labels:
app: kibana
data:
kibana.yml: |-
server.host: 0.0.0.0
elasticsearch.hosts: ${ELASTICSEARCH_HOSTS}
#elasticsearch:
# hosts: ${ELASTICSEARCH_HOSTS}
# username: ${ELASTICSEARCH_USER}
# password: ${ELASTICSEARCH_PASSWORD}2. kibana-deployment.yaml
elasticsearch url은 logstash에서 설명한 내용과 동일하게 {elasticsearch service name}:{elasticsearch service port} 이다.
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: elk
name: kibana
labels:
app: kibana
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
#image: docker.elastic.co/kibana/kibana-oss:7.9.3
image: docker.elastic.co/kibana/kibana-oss:6.8.23
imagePullPolicy: IfNotPresent
ports:
- containerPort: 5601
name: view
env:
- name: ELASTICSEARCH_HOSTS
value: "http://elasticsearch:9200"
#- name: ELASTICSEARCH_USER
# value: "elastic"
#- name: ELASTICSEARCH_PASSWORD
# valueFrom:
# secretKeyRef:
# name: elasticsearch-pw-elastic
# key: password
volumeMounts:
- name: config
mountPath: /usr/share/kibana/config/kibana.yml
readOnly: true
subPath: kibana.yml
- name: tz-seoul
mountPath: /etc/localtime
volumes:
- name: config
configMap:
name: kibana-config
- name: tz-seoul
hostPath:
path: /usr/share/zoneinfo/Asia/Seoul3. kibana-service.yaml
kibana는 view가 목적이기 때문에 외부망 연결을 대부분 허용한다.
상황에 따라 NodePort or LoadBalaner를 사용할 수 있다. nodePort는 30000~32767 범위내에서 사용자 입력이 가능하며 입력 하지 않을 경우 임의의 포트로 연결이 된다.
apiVersion: v1
kind: Service
metadata:
namespace: elk
name: kibana
labels:
app: kibana
spec:
ports:
- port: 33000
name: view
targetPort: 5601
#nodePort: 30930
#type: NodePort
#type: LoadBalancer
externalIPs:
- 192.168.1.10
selector:
app: kibana> Filebeat
1. filebeat-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: kube-system
labels:
k8s-app: filebeat
data:
filebeat.yml: |-
filebeat.config:
inputs:
# Mounted `filebeat-inputs` configmap:
path: ${path.config}/inputs.d/*.yml
# Reload inputs configs as they change:
reload.enabled: false
modules:
path: ${path.config}/modules.d/*.yml
# Reload module configs as they change:
reload.enabled: false
# To enable hints based autodiscover, remove `filebeat.config.inputs` configuration and uncomment this:
#filebeat.autodiscover:
# providers:
# - type: kubernetes
# hints.enabled: true
processors:
- add_cloud_metadata:
cloud.id: ${ELASTIC_CLOUD_ID}
cloud.auth: ${ELASTIC_CLOUD_AUTH}
output.elasticsearch:
hosts: ['${ELASTICSEARCH_HOST:elasticsearch}:${ELASTICSEARCH_PORT:9200}']
username: ${ELASTICSEARCH_USERNAME}
password: ${ELASTICSEARCH_PASSWORD}2.filebeat-daemonset.yaml
