3주차 Day3 - Pands
Pandas 를 배웠다.
기초 Pandas 는 Numpy와 비슷했고
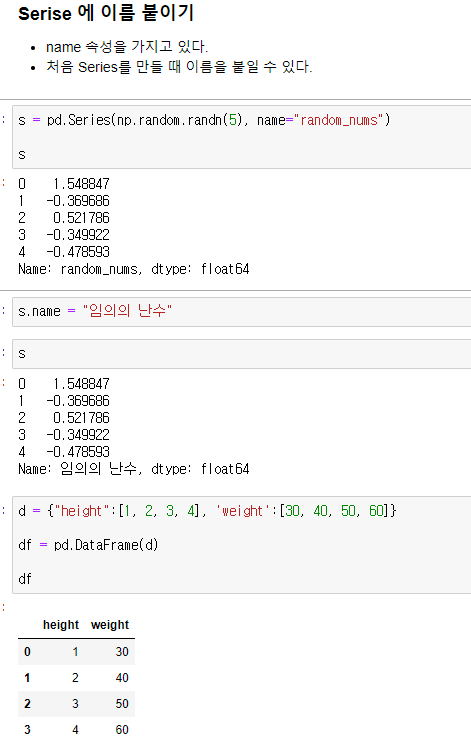
1강에서 크게 배운 부분은 Farame 기능과 .name 이 있다.
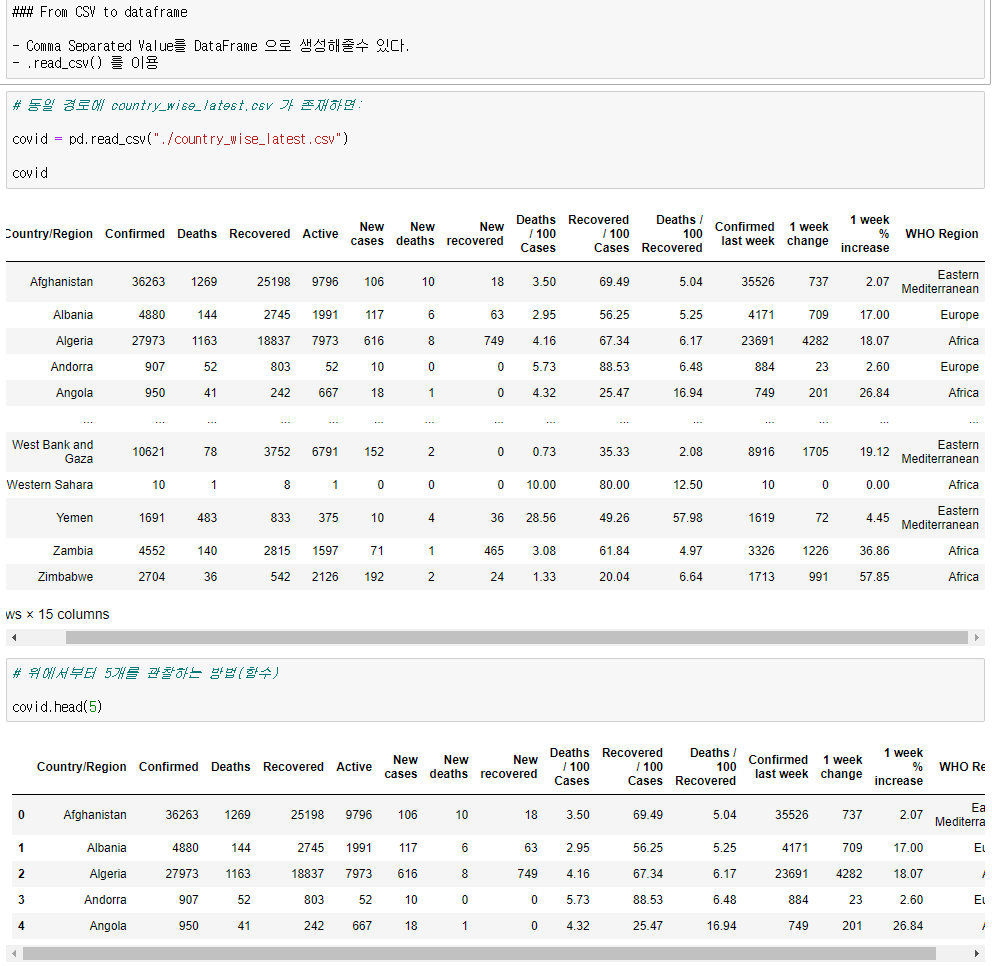
2강에서 는 실제 캐글에 있는 Covid-19 csv 데이터를 가져와서 다뤄봤다.
데이터 읽기
pd.read_cvs("파일위치") 를 통해서 csv를 읽을수 있다.
.head(n) 을 통해 위에서부터 n개를 관찰
.tail(n) 을 통해 아래에서 n개를 관찰
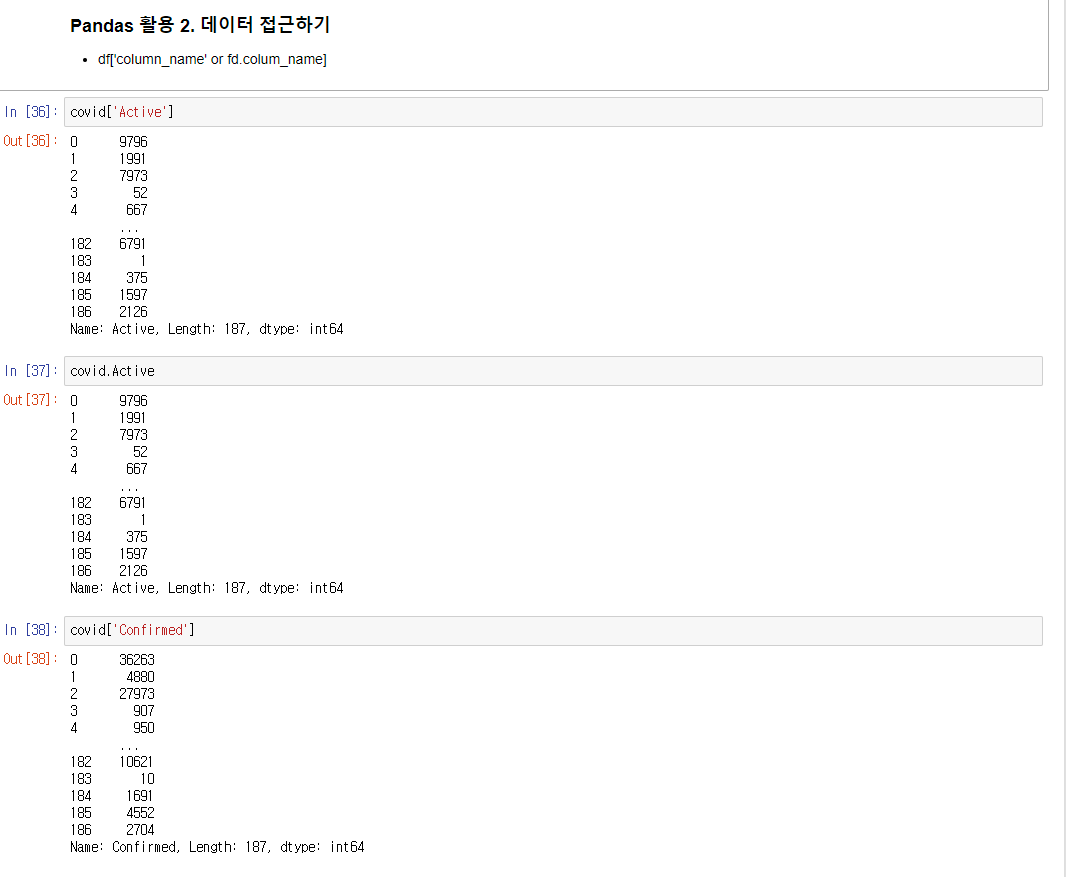
데이터 접근하기
covid['이름'] 을 통해 가져올수 있으며
covid.이름 을 통해도 가져올수 있다 다만 아래 방법을 사용한다면 띄어스기는 표기할수 없음.
covid['Confirmed'][1:5] 를 통해서 코비드의 confirmed 열의 1~4 까지의 데이터를 읽어올수 있음.
Honey Tip! Dataframe 의 각 column은 "Series" 다!
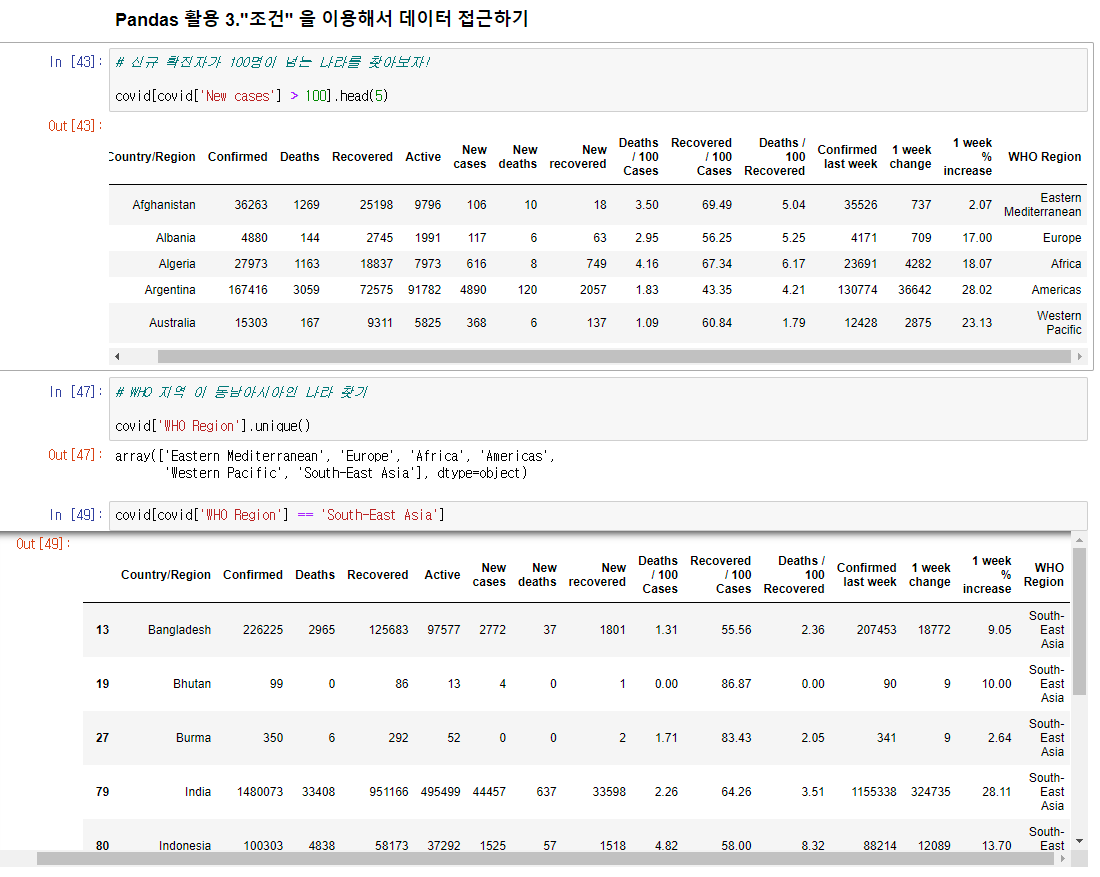
데이터 접근하기 - "조건"을 이용
covid[covid['New case'] > 100].head(5) 를 통해서코비드의 New case가 100보다 큰 값들의 위에서부터 5개의 데이터를 읽을수 있다.(covid['New case']>100 을 사용하면 False True 의 데이터로만 읽어옴)
처음 받은 데이터에서 카테고리의 중복없이 읽는방법:
covid['읽고싶은 데이터 명'].unique()
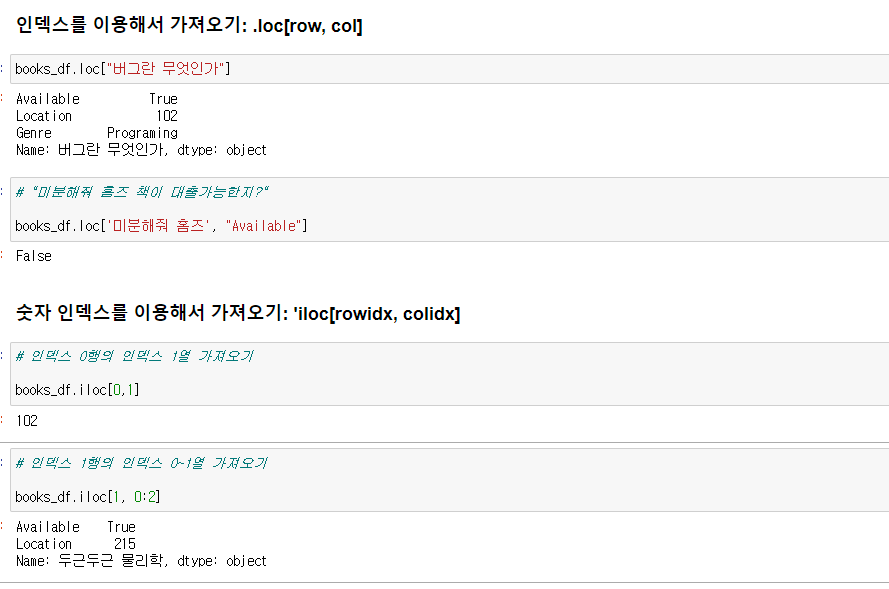
데이터 접근하기 - "행" 을 기준
.loc[row,col] 을 이용 특정 행과 열의 정보를 가져올수 있음.
.iloc[rowidx, colidx] 를 이용해서 특정 행의 인덱스를 가져올 수 있음.
.iloc[1, 0:2] 등의 슬라이싱 가능.
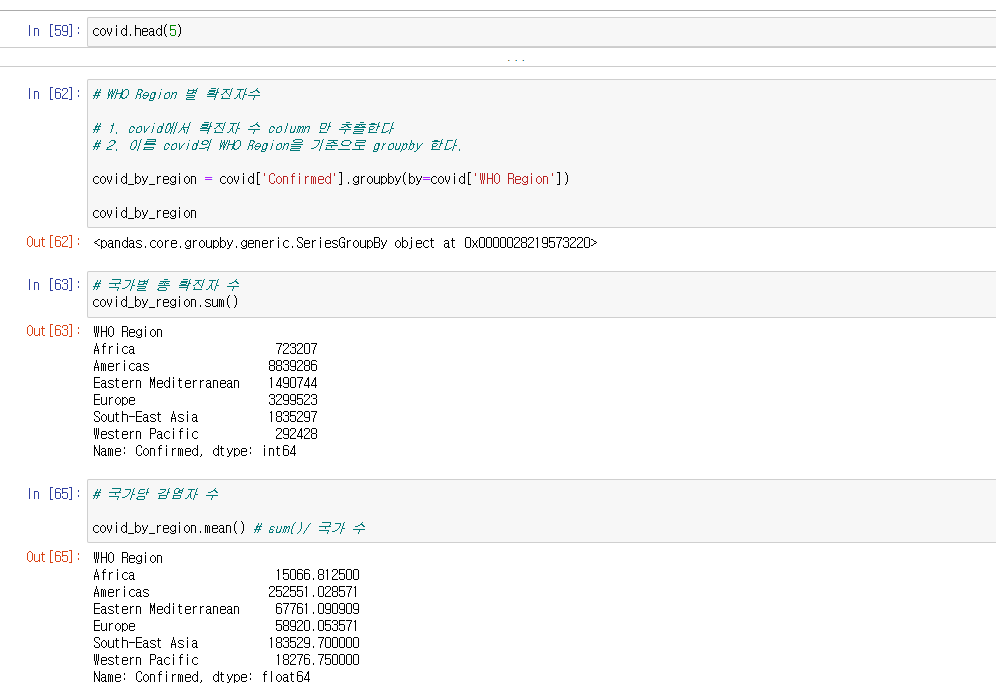
데이터 접근하기 - 'Groupby' 를 이용
- Split : 특정한 '기준' 을 바탕으로 DataFrame을 분할
- Apply : 통계함수 - sum(), mean(), median() - 을 적용해서 각 데이터를 압축
- Combine: Apply 된 결과를 바탕으로 새로운 Series를 생성(group_key: applied_value)
covid_by_region=covid['Confirmed].groupby(by=covid['WHO Region']
을 통하여 WHO Region 별 확진자 수로 groupbycovid_by_region.sum() 을 통하여 groupby 한 결과의 총합을 구함
covid_bt_region.mean() 을 통하여 grouby 한 결과의 평균을 구함
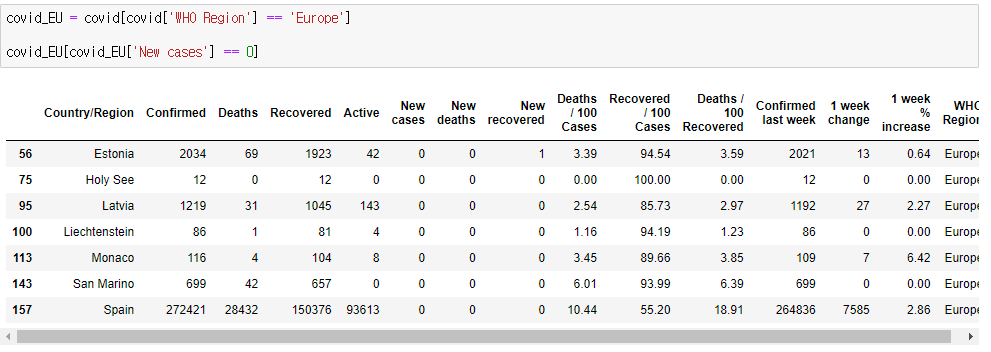
오늘의 실습
1.covid 데이터에서 100 case 대비 사망률(Deaths / 100 Cases) 이 가장 높은 국가는?

2. covid 데이터에서 신규 확진자가 없는 나라 중 WHO Region 이 'Europe' 를 모두 출력하면?
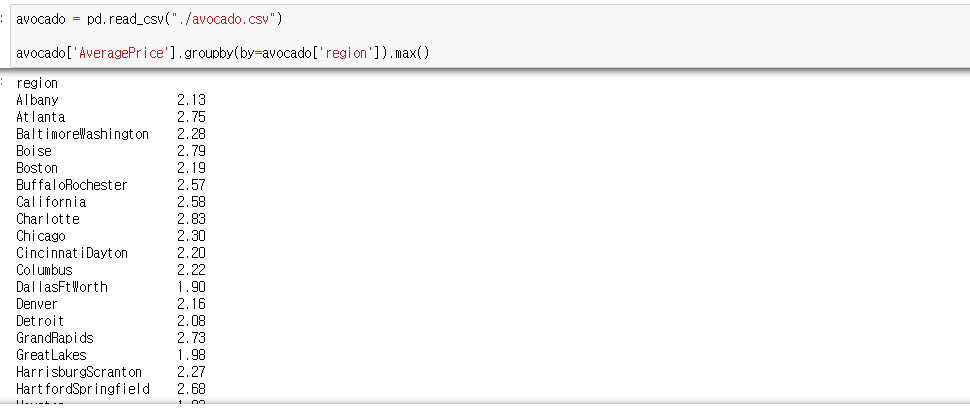
3. 다음 데이터를 이용해 각 Region별로 아보카도가 가장 비싼 평균가격(AveragePrice) 를 출력하면?