2주차 Day5
표본분포
- 표본평균 = 모평균을 알아내는데 쓰이는 통계랑
- 표본평균의 분포

표본에 따른 히스토그램 그래프
import numpy as np
import matplotlib as plt
xbars = [np.mean(np.random.normal(loc = 10, scale=3, size=10))for i in range(10000)]
print("mean %f, var %f "%(np.mean(xbars), np.var(xbars)))
h = plt.pyplot.hist(xbars, range=(5,15), bins=30)결과: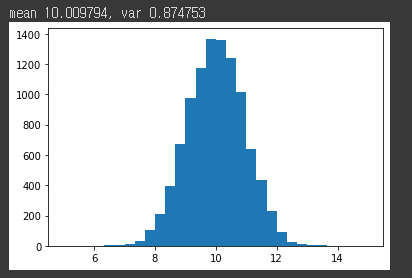
중심극한정리
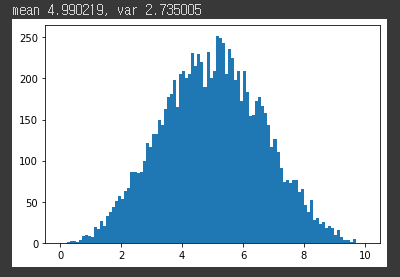
import numpy as np import matplotlib as plt n = 3 xbars=[np.mean(np.random.rand(n) * 10) for i in range(10000)] print("mean %f, var %f" %(np.mean(xbars), np.var(xbars))) h = plt.pyplot.hist(xbars, range=(0,10), bins=100)결과:

모평균의 추정
구간 추정
- 실용적이지 못함: 정규분포가 아니거나 표준편차가 알려져 있지 않음
ex) 어떤 농장에서 생산된 계란 30개의 표본을 뽑았더니 그 무게가 아래와 같다.
계란의 평균 무게에 대한 95% 신뢰 구간을 구하시오.
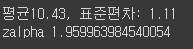
import numpy as np w = [10.7,11.7,9.8,11.4,10.8,9.9,10.1, 8.8,12.2, 11.0, 11.3, 11.1, 10.3, 10.0, 9.9, 11.1, 11.7, 11.5, 9.1, 10.3, 8.6, 12.1, 10.0, 13.0, 9.2, 9.8, 9.3, 9.4, 9.6, 9.2] xbar = np.mean(w) sd = np.std(w, ddof=1) print("평균%.2f, 표준편차: %.2f"%(xbar,sd)) import scipy.stats alpha = 0.05 zalpha = scipy.stats.norm.ppf(1-alpha/2) print("zalpha",zalpha)결과:

통계적 가설검정
가설 검정
표본 평균은 표본의 선택에 의해 달라짐 주의

엔트로피
자기정보(Self-information): i(A)

엔트로피는 다시 들어야될듯...

코린이의 성장 일기..