- 인공지능에 대해서 공부한 내용을 바탕으로 포스팅하겠습니다
AI의 3개의 도메인
인공지능에는 다양한 분야가 있겠지만, 우선적으로 제가 공부한 내용을 바탕으로 먼저 포스팅 하도록 하겠습니다.
제가 공부한 인공지능 분야는 총 3가지가 있습니다.
1. 통계 데이터 / 2. 자연 언어 처리(NLP) / 3. 컴퓨터 비전
1. 통계 데이터
예시) 주식, 항공기 센서 유지 보수 예측 등
: 주로 예시들과 같은 예측 작업을 이루고, 대부분 숫자로 표현되는 데이터입니다.
2. 자연 언어 처리(NLP)
예시) 챗봇, Siri, 클로바 등
: 사람의 언어를 학습시키는 작업을 말합니다.
3. 컴퓨터 비전
예시) 마스크 인식, 자율주행 등
; 예시와 같은 분류 작업이 주를 이룹니다.
인공지능, 머신러닝, 딥러닝의 차이점
- 인공지능 ( AI ) : 컴퓨터가 인간의 지능을 모방할 수 있는 모든 기술
- 머신러닝 (ML) : 기계가 경험이 있는 작업에서 개선할 수 있는 AI의 하위 집합
- 딥러닝 (DL) : 소프트웨어가 방대한 양의 데이터로 작업을 수행하도록 스스로 훈련할 수 있게 해주는 ML의 하위 집합
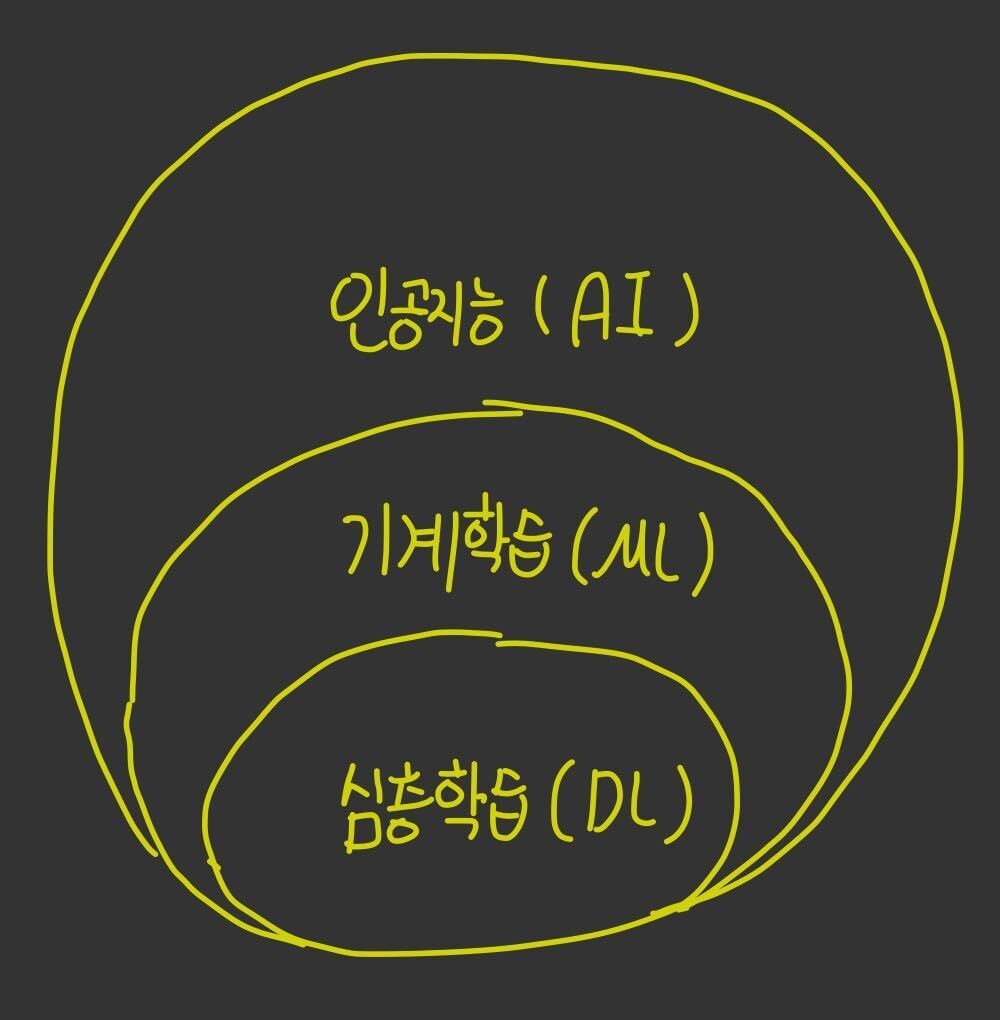
위의 그림처럼 인공지능이 가장 큰 범위를 말하는 것이고, 순서대로 기계학습, 심층학습순으로 범위가 좁아지는 것입니다.
-
지도학습 vs 비지도학습
머신러닝 학습 방법에는 지도학습, 비지도학습, 강화학습이 있습니다.
먼저 지도학습, 비지도학습 먼저 공부를 해보겠습니다!1. 지도학습
- 레이블이 지정된 데이터를 처리 = 정답이 있는(레이블링이 되어 있는) 데이터를 가지고 학습을 시킴
- 주로 분류나 회귀 문제에서 사용되는 학습 방법입니다.
2. 비지도학습
- 레이블이 지정되지 않은 데이터 처리 = 정답이 없는 데이터로 학습을 시킴
- 군집화와 같은 그룹을 묶어 분류하는 곳에 사용되는 학습 방법입니다.
강화학습이란?
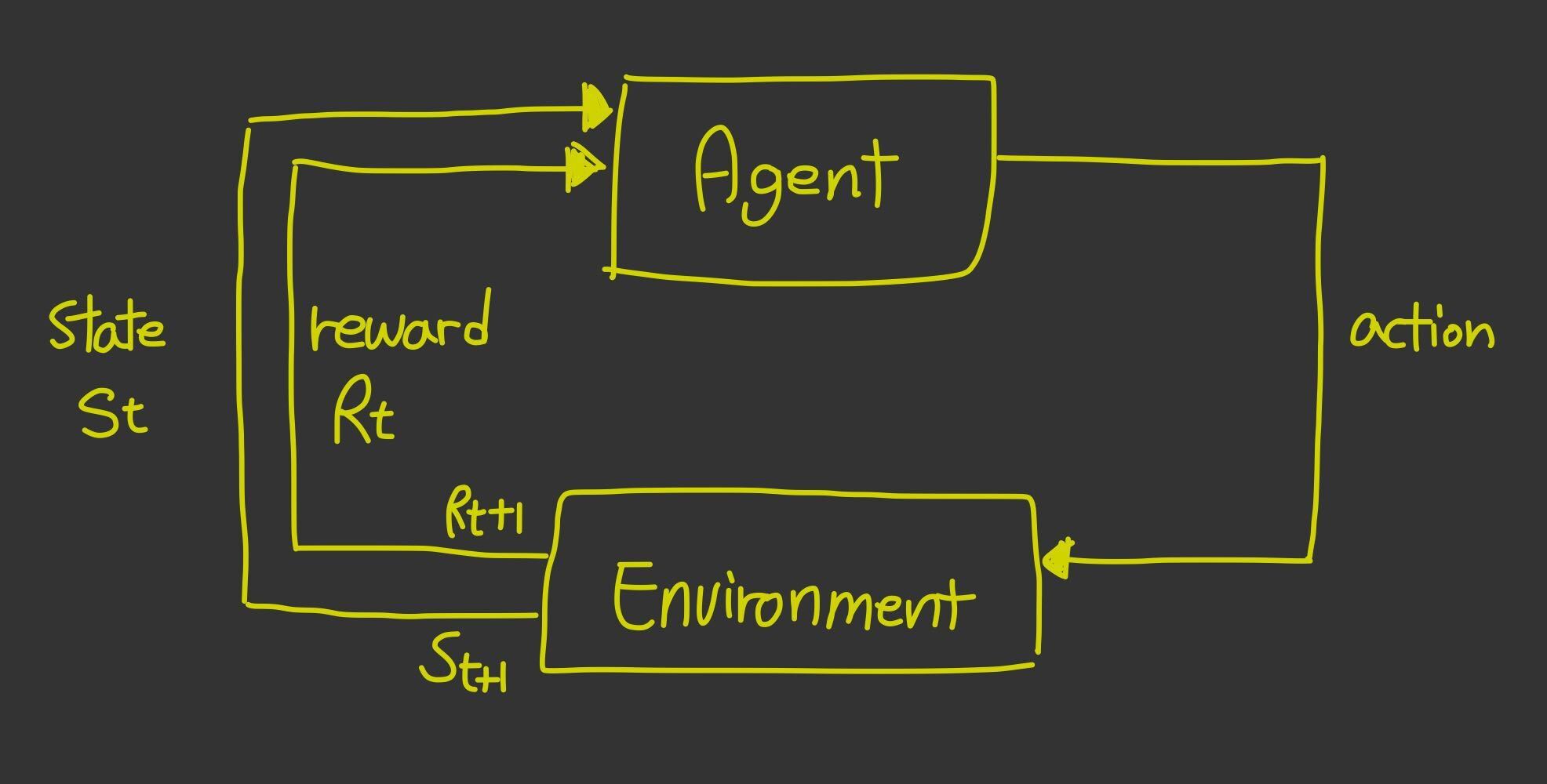
: 어떤 환경 내에서 인공지능이 사용할 수 있는 최고의 정책을 찾아내는 방법입니다.
: 강화학습은 흔히 학습 중 올바른 예측을 했을 때 보상(reward)를 부여하는 방식으로 학습을 진행합니다.
+강화학습은 데이터셋이 크지 않아도 사용이 가능합니다.
-
강화학습 예시
 이미지출처 : 구글이미지
이미지출처 : 구글이미지위와 같은 경우 치즈는 보상(reward)이며, 쥐는 agent이며 미로는 환경(environment)입니다. 그리고 쥐가 취하는 행동이 action이 되고, 미로가 열려있는지 막혀있는지가 state가 될 수 있습니다.
쥐는 치즈로 가는 길을 선택해야 하고, 쥐는 잘못된 모든 길을 기억해야 합니다. 그래서 다시 그곳에 가지 않도록 하고, 이것은 쥐가 보상에 점점 더 가까이 다가갈 수 있도록 도와줍니다.
-
강화학습과 관련된 용어 5가지
필요에 따라 관련 용어가 5 ~ 6가지가 될 수 있습니다.
관련용어 5가지로는
- 상태 State
- 에이전트 Agent
- 동작 Action
- 보상 Reward
- 처벌 Punishment
- 환경 Environment
등이 있습니다.
Q-Learning이란?
Q-Learning은 Model Free 형탸의 강화 학습입니다. 기본적으로 이전에 수행한 작업의 품질을 학습합니다.
강화 학습과의 차이점
강화 학습과 Q-Learning의 차이점은?
어떤 행동이 보상을 극대화하고 어떤 행동이 보상을 가져 오는데 도움이 되지 않는지 기록하는 부분입니다.
쉽게 말해서, 강화 학습의 한 종류로 보상을 극대화하는 방식입니다.
이전의 행동 데이터를 모두 알고 있어야 된다는 특징도 있습니다.
행동 데이터를 가지고 Q-table을 만든다는 점도 있습니다.
Q-Learning 관련 용어 정리
- Alpha
알파 값은 모델이 학습하는 속도를 나타냅니다. 학습률이 너무 낮으면 학습하는 데 시간이 너무 오래걸리고 학습률이 너무 높으면 우리가 원하는 최적의 결과값을 얻기 어렵습니다.
- Gamma
감마 값은 모델이 학습하는 방법을 결정하는 데 중요합니다. 감마가 너무 높으면 모델은 멀리서 크게 보고, 감마가 낮으면 너무 가깝게 자세히 봅니다.
- Epsilon
우리가 과거의 실패로부터 더 많은 것을 배울 수 있는 모델을 원할 때 엡실론 값을 높일 수 있습니다.
이상으로 지도학습에서의 데이터처리 과정에 대한 포스팅을 마치겠습니다!!
추가로 궁금한 점이나 포스팅 내용 중에 수정할 내용이 있다면 편하게 댓글 달아주시면 감사하겠습니다!!
