🧮 기능 점수 산정 절차
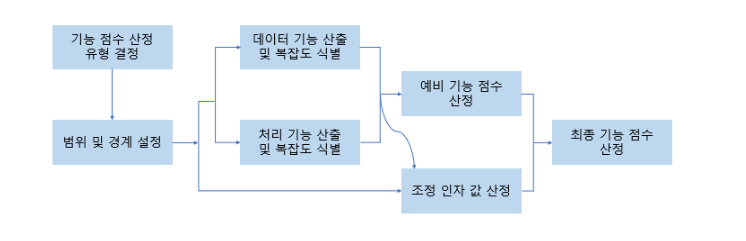
📌 기능 점수 산정 유형 결정
첫 번째 단계는 프로젝트 타입을 결정하는 것이다.
프로젝트 유형
- 개발 프로젝트: 스크래치부터 시작하여 소프트웨어 개발
- 개선 프로젝트: 새로운 기능을 추가하여 기능을 향상
- 유지보수 프로젝트: 기존 기능에서 수정만 수행
📐 범위 및 경계 선정
기능 점수 산출 범위, 소프트웨어 획득 방식, 대상 시스템의 세부 내용을 정의한다.
특히 대상 시스템의 세부 내용은 기능 점수 산정의 핵심 입력 정보가 되기 때문에 최대한 정확하고 명확하게 정의해야 한다.
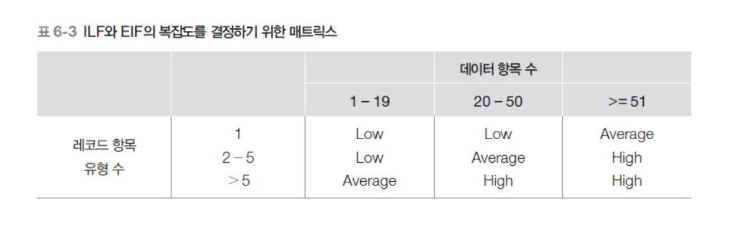
💾 데이터 기능 산출 및 복잡도 식별
데이터 기능을 산정하려면 먼저 내부 논리 파일과 외부 인터페이스 파일을 식별해야 한다.
내부 논리 파일
응용 소프트웨어 범위 내에서 유지되어야 하는 파일 또는 레코드 타입을 의미한다.
외부 인터페이스 파일
응용 소프트웨어 밖에 존재하며 단순히 참조하는 데이터 파일을 의미한다.
요구사항으로부터 파일 또는 레코드, 데이터를 산출한다.
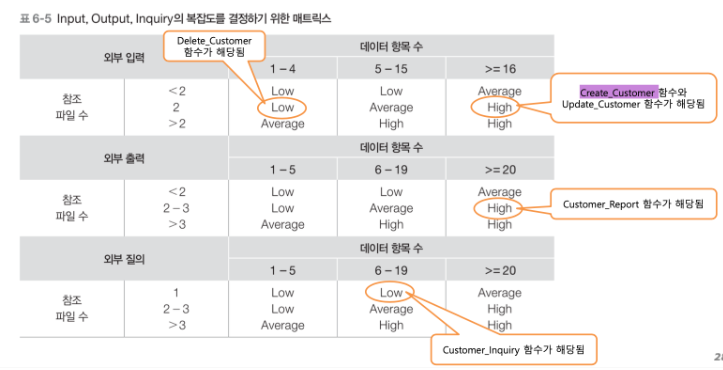
⚙️ 처리 기능 산출 및 복잡도 식별
처리 기능은 응용 소프트웨어가 데이터를 처리하여 사용자에게 제공하는 기능이다.
데이터 기능에서 식별된 각 ILF와 EIF 파일에 대하여 일반적으로 다음과 같으 5가지 처리 함수를 고려한다.
- Create(): 사용자가 입력해야 하는 데이터 항목 수를 산정한다.
- Update(): 사용자 요청에 의해 변경되는 데이터 항목을 처리한다.
- Delete(): 삭제는 주키와 보조키의 삭제를 통해 이루어진다.
- Report(): 사용자에게 전달되는 데이터 항목과 보고서 출력을 위한 부가적인 형식 및 계산 처리 등을 포함한다.
- Inquiry(): 사용자에게 정보를 제공할 목적으로 접근하는 데이터 항목의 수를 계산한다.
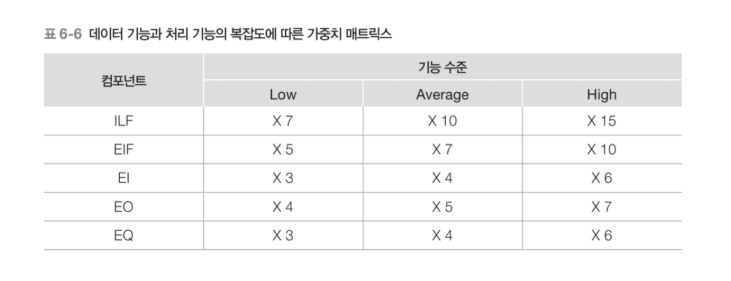
🔢 예비 기능 점수 산정
각 복잡도에 대한 가중치 값을 결정하여 곱해준다.
⚖️ 조정 인자 값 산출
산정된 예비 기능 점수는 소프트웨어 기능만 고려한 것이기에 운영적, 환경적 특성을 지원하는 분석이 필요하다.
다음과 같은 인자들을 고려해야 한다.
| 번호 | 조정 인자 (KR) | 조정 인자 (EN) | 설명 |
|---|---|---|---|
| 1 | 데이터 통신 | Data Communications | 시스템이 외부 또는 내부 네트워크와 주고받는 데이터 통신의 빈도와 복잡도 |
| 2 | 분산 데이터 처리 | Distributed Data Processing | 애플리케이션이 여러 물리적 위치(서버·클라이언트)에서 분산 처리되는 정도 |
| 3 | 성능 요구사항 | Performance Requirements | 처리 속도, 반응 시간, 처리량 등 성능에 대한 엄격성 |
| 4 | 자주 사용되는 구성 | Heavily Used Configuration | 매우 빈번하게 사용되는 시스템 구성 요소(예: 대화형 화면)의 비중 |
| 5 | 거래 처리율 | Transaction Rate | 단위 시간당 처리해야 하는 트랜잭션(입력·조회·수정 등)의 수 |
| 6 | 온라인 데이터 입력 | On-line Data Input | 사용자가 온라인 상에서 직접 입력하는 데이터의 양과 복잡도 |
| 7 | 최종 사용자 효율성 | End‑user Efficiency | 사용자 인터페이스(UI)의 편의성, 사용성 요구사항의 수준 |
| 8 | 온라인 갱신 | On-line Update | 온라인 환경에서 데이터 갱신(수정·삭제) 기능의 필요성 및 빈도 |
| 9 | 복잡한 처리 | Complex Processing | 복잡한 비즈니스 규칙·알고리즘·검증 로직의 정도 |
| 10 | 재사용성 | Reusability | 기존 컴포넌트나 코드의 재사용 요구 수준 |
| 11 | 설치 용이성 | Installation Ease | 시스템 설치·배포 과정의 난이도 |
| 12 | 운영 용이성 | Operational Ease | 시스템 운영·유지보수 지원의 편의성 |
| 13 | 다중 사이트 | Multiple Sites | 애플리케이션이 여러 지리적 위치(지사·지점 등)에서 사용되는 정도 |
| 14 | 변화 용이성 | Facilitate Change | 기능 변경·업그레이드 수행의 용이성 |
위에서 제시한 14개의 시스템 특성에 대하여 영향도가 결정되면 각 영향도의 합을 구한 후에 다음 공식에 따라 조정 인자 값(VAF)을 산출한다.

🎯 최종 기능 점수 산출
VAF 값을 예비 기능 점수에 곱해주면 된다.

작은 문제를 하나하나 해결하며, 누군가의 하루에 선물이 되는 코드를 작성해 갑니다.